案例目标
本题目标:采集 5 页中胜点列的数据,找出胜点最高的召唤师,将召唤师姓名填入答案中

字体反爬
演变的基本阶段:
1. 固定字体编码、固定字体坐标
2. 动态字体编码、固定字体坐标
3. 动态字体编码、动态字体坐标
字体反爬的原理:前端工程师通过自定义的字体来替换页面中某些关键的数据,在 HTML 中使用 @font-face 自定义字体:
@font-face {
font-family: <identifier>;
src: <fontsrc> [, <fontsrc>]*; <font>;
}
里面的 font-family 也就是一个特定的名字,src 就表示需要引用的具体的文件,而这个文件就是字体文件,一般是 ttf 类型,eot 类型,现在因为 ttf 类型文件过大,在移动端使用的时候会导致加载速度过慢,woff 类型的文件较为广泛应用。
更多相关推荐阅读:谈谈字体反爬的前世今生
常规 JavaScript 逆向思路
一般情况下,JavaScript 逆向分为三步:
- 寻找入口:逆向在大部分情况下就是找一些加密参数到底是怎么来的,关键逻辑可能写在某个关键的方法或者隐藏在某个关键的变量里,一个网站可能加载了很多 JavaScript 文件,如何从这么多的 JavaScript 文件的代码行中找到关键的位置,很重要;
- 调试分析:找到入口后,我们定位到某个参数可能是在某个方法中执行的了,那么里面的逻辑是怎么样的,调用了多少加密算法,经过了多少赋值变换,需要把整体思路整理清楚,以便于断点或反混淆工具等进行调试分析;
- 模拟执行:经过调试分析后,差不多弄清了逻辑,就需要对加密过程进行逻辑复现,以拿到最后我们想要的数据
接下来开始正式进行案例分析:
寻找入口
F12 打开开发者人员工具,刷新网页进行抓包,在 Network 中可以看到数据接口为 7,响应预览中可以看到当前页面各玩家胜点数据被混淆了:

最底下的部分为 woff 文件:
woff: "AAEAAAAKAIAAAwAgT1MvMvz1V98AAAEoAAAAYGNtYXAXunFWAAABpAAAAYpnbHlmG6nCuAAAA0gAAAQEaGVhZBpe3c8AAACsAAAANmhoZWEGwgFBAAAA5AAAACRobXR4ArwAAAAAAYgAAAAabG9jYQVeBnQAAAMwAAAAGG1heHABGABFAAABCAAAACBuYW1lUGhGMAAAB0wAAAJzcG9zdCztalcAAAnAAAAAiAABAAAAAQAA9ZRArF8PPPUACQPoAAAAANnIUd8AAAAA3ztIRgAG/+wCOALZAAAACAACAAAAAAAAAAEAAAQk/qwAfgJYAAAAOgIeAAEAAAAAAAAAAAAAAAAAAAACAAEAAAALADkAAwAAAAAAAgAAAAoACgAAAP8AAAAAAAAABAIqAZAABQAIAtED0wAAAMQC0QPTAAACoABEAWkAAAIABQMAAAAAAAAAAAAAEAAAAAAAAAAAAAAAUGZFZABAoWnnUQQk/qwAfgQkAVQAAAABAAAAAAAAAAAAAAAgAAAAZAAAAlgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAwAAAAMAAAAcAAEAAAAAAIQAAwABAAAAHAAEAGgAAAAWABAAAwAGoWmlc6YZtHi1Y7h2xBflluYk51H//wAAoWmlc6YZtHi1Y7h2xBflluYk51H//16hWpNZ8EuNSqRHizvtGmwZ3xi3AAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACwBDAJoA2wDxAQ4BTAFfAZAB0wICAAEABv/sADAAEgACAAA3MxUGKhImAAABACv/8gIsAsUAJAAAEwMzNjc2MxYWFRQGIyInJjUjBhcWMzI3NjU0JiMGBwYHIzchNXUyRBYuJjpCZ2k0RTspYANjLl58RD11ZD4OShUEFgGHAsX+cC8mDAlUYkJXFCk7WTgzTEFgcYMBCh0h6VIAAwAd//ICLALQAB8ALAA4AAABIgcGFRQXFhc1BgcGFRQWIDc2NTQnJicVNjc2NTQnJgcyFxYUBwYiJyY0NzYTMhcWFAcGIiY0NzYBK341NSYLMTIfN4UBHR5FLScwOR82VjR3awg2FUqhHRIQKkxPQRMTRppoKj4C0DYxUSpADSkJFiw7Tl9lNy5fTjssFgkpDUAqUTE2RCcbXDAhITBcGyf+xywdiyInSYsdLAAAAgAu//ICIALZABsAKAAAASIHBhUUFxYXNjY0JiMiBwYHIyc0NzY3FhUzNgM2FwYUBwYHIicmNDYBOX5DSkUyimKPUo49EUUfDgY9JFSfPQzeOVwEKDE4GHQIPwLQaFTPbH9nAQGH5m0iFUEjbE9YFRVjsf6xKFslmSE6DS0um2MAAAEAdQAAAXICxQAJAAABBgYHFTY3ETMRATk1Zil9JloCxQNiE1QlQv2gAsUAAgAaAAACOALFAAoADgAAAQEVIRUzNTM1IxEHMxEhAX/+mwFbcFNTcwP/AALF/jFTo6MzAe9g/nEAAAIALv/yAiAC0AAcACgAAAEiBhUUFxYzNjY3MxcUBwYjIjcjFjM2NzY1NCcmBzIXFhQGIyImNTQ2ARtkiT1CY0FtEAkOQwx7hA5vIsd7QkQ8RoRUKjZjUShkTQLQhl54QUEPMi0bekNXcbABZ3yio1JjMDg+mV5kVT13AAABADYAAAIsAsUABgAAExUhATMBNTYBif79ZQELAsVC/X0Cg0IAAAEAMQAAAiwC0AAdAAABIgYHMyY3NhcyFhUUBwYHBgcGFSE1ITY3Njc2NCYBOXRyHV8CJGoYNWlBLVRoH10B2v6RF4FvJmOWAtCGfFw+OAhFQjVbITlGP0haP1xSTB5brnAAAQAu//ICLALQACsAAAEiBwYHMzY2NxYXFhQGIyMVMzYWFAcGIyYnJjcjFhcWFzI2NTQnJic2NTQmATluPTwcXxB8GDQ1KFk4R0c+XQZdP1ArOAVWJS9KZmaIKBNIj44C0DY6Z0VaCAgzG25TQwhBgS8fCg8vSm0oSAFvbEIqGyQqZoNFAAACADD/8gIgAtkADAAZAAABJgcGEBcWMjc2ECcmBzIXFhAHBiInJhA3NgErb1M5OVPgSDw8SHFZMBYWMLgfHx8fAtAJeEf+v39oaH8BQUd4QVxQ/u4/U1M/ARJQXAAAAAASAN4AAQAAAAAAAAAXAAAAAQAAAAAAAQAMABcAAQAAAAAAAgAHACMAAQAAAAAAAwAUACoAAQAAAAAABAAUACoAAQAAAAAABQALAD4AAQAAAAAABgAUACoAAQAAAAAACgArAEkAAQAAAAAACwATAHQAAwABBAkAAAAuAIcAAwABBAkAAQAYALUAAwABBAkAAgAOAM0AAwABBAkAAwAoANsAAwABBAkABAAoANsAAwABBAkABQAWAQMAAwABBAkABgAoANsAAwABBAkACgBWARkAAwABBAkACwAmAW9DcmVhdGVkIGJ5IGZvbnQtY2Fycmllci5QaW5nRmFuZyBTQ1JlZ3VsYXIuUGluZ0ZhbmctU0MtUmVndWxhclZlcnNpb24gMS4wR2VuZXJhdGVkIGJ5IHN2ZzJ0dGYgZnJvbSBGb250ZWxsbyBwcm9qZWN0Lmh0dHA6Ly9mb250ZWxsby5jb20AQwByAGUAYQB0AGUAZAAgAGIAeQAgAGYAbwBuAHQALQBjAGEAcgByAGkAZQByAC4AUABpAG4AZwBGAGEAbgBnACAAUwBDAFIAZQBnAHUAbABhAHIALgBQAGkAbgBnAEYAYQBuAGcALQBTAEMALQBSAGUAZwB1AGwAYQByAFYAZQByAHMAaQBvAG4AIAAxAC4AMABHAGUAbgBlAHIAYQB0AGUAZAAgAGIAeQAgAHMAdgBnADIAdAB0AGYAIABmAHIAbwBtACAARgBvAG4AdABlAGwAbABvACAAcAByAG8AagBlAGMAdAAuAGgAdAB0AHAAOgAvAC8AZgBvAG4AdABlAGwAbABvAC4AYwBvAG0AAAIAAAAAAAAADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAsACwAAAQoBCAEJAQIBCwEDAQUBBwEEAQYHdW5pYzQxNwd1bmlhNTczB3VuaWE2MTkHdW5pYjU2Mwd1bmlhMTY5B3VuaWU3NTEHdW5pZTU5Ngd1bmllNjI0B3VuaWI4NzYHdW5pYjQ3OA=="woff 文件是字体文件,实际上就是编码和字符的映射表,如 섴,&#x 是字符前缀,c134 是字符对应的编码,本题字体文件和胜点列的数据都在一个接口里,从 Initiator 中向下跟栈到 request 对应的 7:formatted 文件中:

ctrl + f 局部搜索 woff 关键字,有一个结果,在该文件的第 993 行

ttf = data.woff;
$('.font').text('').append('<style type="text/css">@font-face { font-family:"fonteditor";src: url(data:font/truetype;charset=utf-8;base64,' + ttf + '); }</style>');src 为下载路径,这里可以看到 woff 文件被保存为了 ttf 格式,通过 python 将其下载下来:
import base64
# 填入 woff 后字符串中的内容
woff_content = "AAEAA........jMjUx"
with open('./yrx7.ttf', 'wb') as f:
f.write(base64.b64decode(woff_content))
调试分析
经过测试,字体编码是在动态变化的,所以无法直接对应替换:
import requests
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
}
url = "https://match.yuanrenxue.com/api/match/7"
for _ in range(3):
response = requests.get(url, headers=headers)
print(response.json()['data'][0])
# {'value': '씔 쒖 씔 ꢔ '}
# {'value': '늇 ꕨ 늇 넧 '}
# {'value': '륓 뒓 륓  '}所以我们需要通过观察字体文件的具体内容来寻找突破口,通过 fontTools 库将 ttf 格式文件转换为 xml 格式文件:
fontTools 官方文档:fontTools Docs — fontTools Documentation
Github fontTools:GitHub - fonttools/fonttools: A library to manipulate font files fromPython.
pip3 install fonttoolsfrom fontTools.ttLib import TTFont
font = TTFont('./yrx7.ttf')
font.saveXML('./yrx7.xml')先来分析下该 ttf 文件的结构:
from fontTools.ttLib import TTFont
font = TTFont("yrx7.ttf")
# 获取 ttf 文件中的表名
list_name = font.keys()
print(list_name)
# ['GlyphOrder', 'head', 'hhea', 'maxp', 'OS/2', 'hmtx', 'cmap', 'loca', 'glyf', 'name', 'post']表名包含 glyf 关键字,表示图元数据,以序列形式保存,每个图元以图元头(GlyphHeader)结构开始,表明这是一个使用 TrueType 轮廓的字体文件 :
TrueType:Windows 和 Mac 系统最常用的字体格式,基于轮廓技术的数学模式来进行定义,比基于矢量的字体更容易处理,保证了屏幕与打印输出的一致性,同时,这类字体和矢量字体一样可以随意缩放、旋转而不必担心会出现锯齿。
TTGlyph 的两个子类 TTGlyphGlyf 和 _TTGlyphCFF 分别对应 TrueType 轮廓和 Postscript 轮廓:
from fontTools.ttLib import TTFont
font = TTFont("xxx.ttf")
glyph = font.getGlyphSet()["uni70E0"] # 获取 _TTGlyph 实例
print(glyph._glyph.coordinates) # 坐标
print(glyph._glyph.endPtsOfContours) # 轮廓结束点
print(list(glyph._glyph.flags)) # 点类型 flag生成的 xml 文件对应的字体编码部分如下:
<GlyphOrder>
<!-- The 'id' attribute is only for humans; it is ignored when parsed. -->
<GlyphID id="0" name=".notdef"/>
<GlyphID id="1" name="unif472"/>
<GlyphID id="2" name="unif865"/>
<GlyphID id="3" name="unic846"/>
<GlyphID id="4" name="unic251"/>
<GlyphID id="5" name="unif165"/>
<GlyphID id="6" name="unib294"/>
<GlyphID id="7" name="unib721"/>
<GlyphID id="8" name="unic215"/>
<GlyphID id="9" name="unib241"/>
<GlyphID id="10" name="unie291"/>
</GlyphOrder>字体编码为 unic846 的字体坐标:

刷新网页获取新的 woff 值,再下载保存一份 ttf 文件作对比,会发现字体坐标 x、y 是动态变化的,但是 on 的值是不变的:
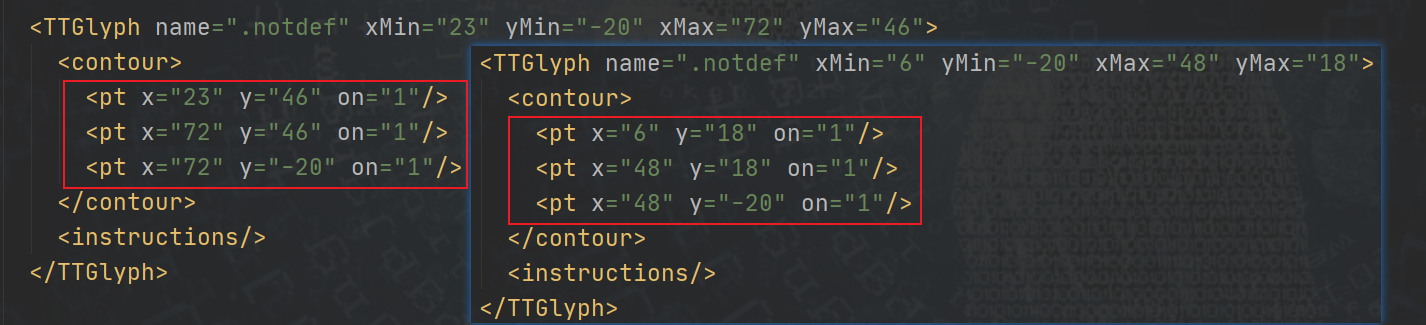
通过比较,其他字符的 on 值也不变,所以可以用过 on 值形成映射关系从而进行识别,将下载后的 ttf 文件放到 在线字体编辑器-FontStore 中打开,这里还原出了每个加密编码对应的数字字符:
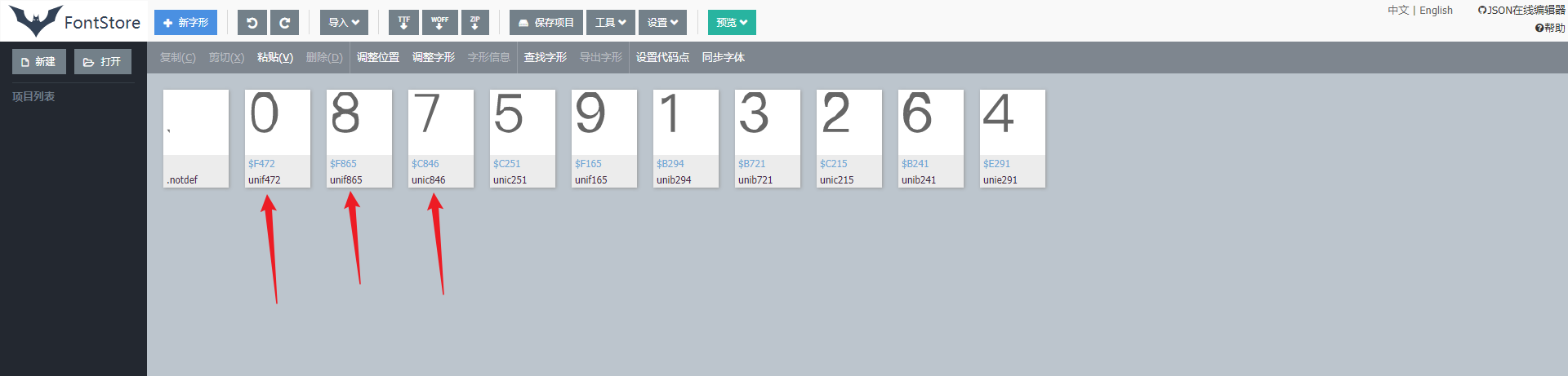

根据 ttf 文件编码顺序对应更改,我的 ttf 文件对应的数字顺序为:6, 1, 3, 2, 5, 7, 4, 9, 0, 8 ,接下来获取每个坐标对应的 on 值:
方式一:
from fontTools.ttLib import TTFont
# 创建 TTFont 实例
font = TTFont("yrx7.ttf")
# 返回一个 _TTGlyphset 对象, 包含字形轮廓数据
# _TTGlyphset 是一个类似字典的, 以字形名称为键、_TTGlyph 为值的对象
glyf = font.getGlyphSet()
# 返回一个字形名称列表, 以字母顺序排序
glyphNames = font.getGlyphNames()
# 数字列表
num_list = [6, 1, 3, 2, 5, 7, 4, 9, 0, 8]
map_dict= {}
for i, name in enumerate(glyphNames[1:]):
# 通过字形名称选择字形对象
g = glyf[name]
# 点类型 flag
# 读取每个坐标对应的 on 值
flag = list(g._glyph.flags)
# 控制点的坐标
# print(glyph._glyph.coordinates)
# map_dict 字典里的键对应的数字,值则是 on 值构成的列表
map_dict[num_list[i]] = flag
print(map_dict)方式二:
on_dict = {}
num_list = [6, 1, 3, 2, 5, 7, 4, 9, 0, 8]
# 创建 TTFont 实例
font = TTFont("yrx7.ttf")
# 返回一个字形名称列表,以字母顺序排序
glyphNames = font.getGlyphNames()
for i, name in enumerate(glyphNames[1:]):
# 读取 glyf 表, 获取各字形对应的 on 值
on_data = font['glyf'][name].flags
on_key = "".join([str(n) for n in on_data])
on_dict[on_key] = num_list[i]
print(on_dict)接下来需要知道各胜点是如何赋值给对应玩家的,相关计算逻辑同样在 7 文件中,在格式化后的第 1008 行,打下断点进行调试:
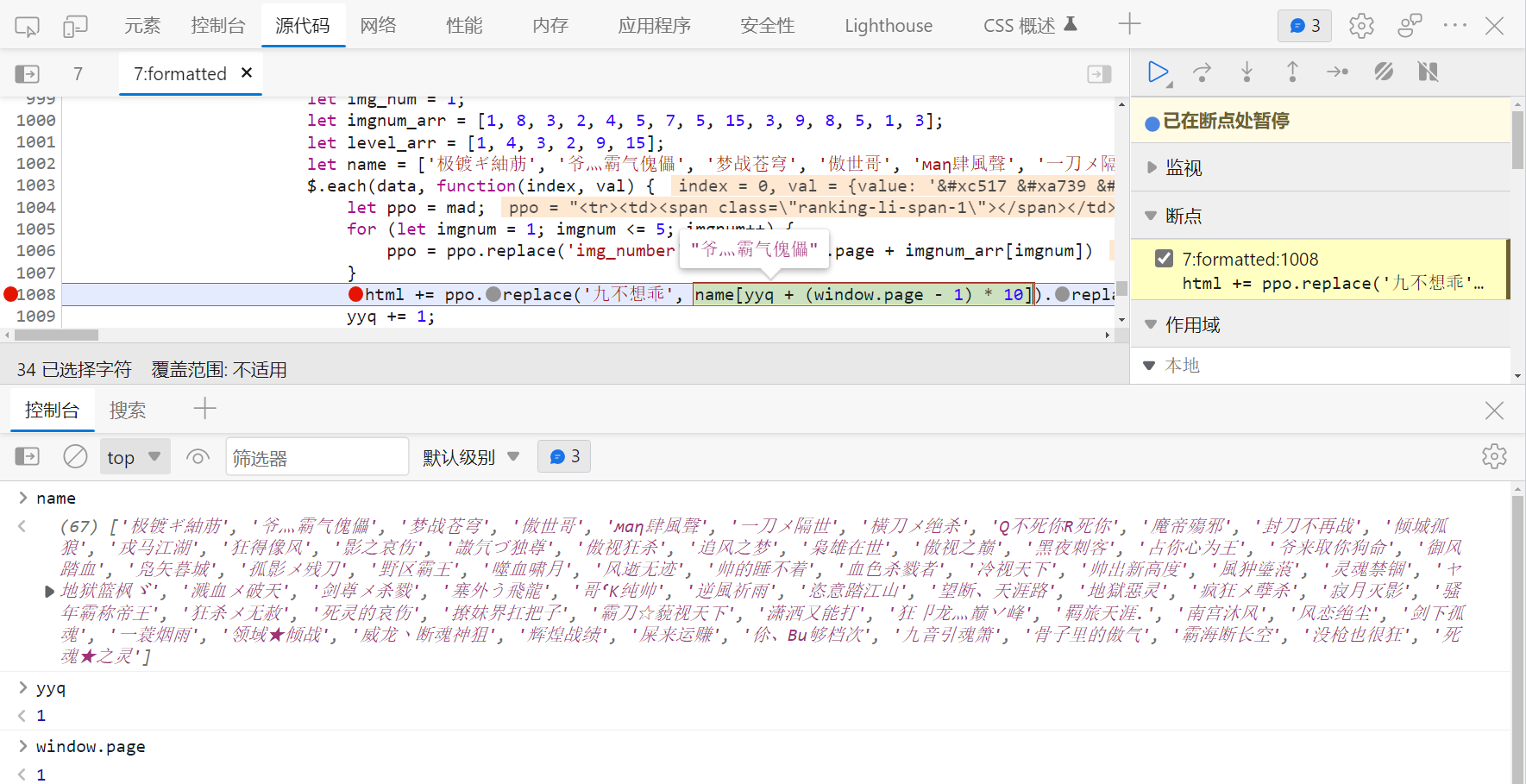
name[yyq + (window.page - 1) * 10]Python 代码
get_on_map() 函数的 num_list 列表中的数字顺序需要与保存的 ttf 文件中的编码顺序一致 ,sessionid 要改为自己的:
import base64
import requests
from fontTools.ttLib import TTFont
# 玩家名称列表
player_list = ['极镀ギ紬荕', '爷灬霸气傀儡', '梦战苍穹', '傲世哥', 'мaη肆風聲', '一刀メ隔世', '横刀メ绝杀', 'Q不死你R死你', '魔帝殤邪', '封刀不再战', '倾城孤狼', '戎马江湖',
'狂得像风', '影之哀伤', '謸氕づ独尊', '傲视狂杀',
'追风之梦', '枭雄在世', '傲视之巅', '黑夜刺客', '占你心为王', '爷来取你狗命', '御风踏血', '凫矢暮城',
'孤影メ残刀', '野区霸王', '噬血啸月', '风逝无迹', '帅的睡不着', '血色杀戮者', '冷视天下', '帅出新高度',
'風狆瑬蒗', '灵魂禁锢', 'ヤ地狱篮枫ゞ', '溅血メ破天', '剑尊メ杀戮', '塞外う飛龍', '哥‘K纯帅',
'逆風祈雨',
'恣意踏江山', '望断、天涯路', '地獄惡灵', '疯狂メ孽杀', '寂月灭影', '骚年霸称帝王', '狂杀メ无赦',
'死灵的哀伤',
'撩妹界扛把子', '霸刀☆藐视天下', '潇洒又能打', '狂卩龙灬巅丷峰', '羁旅天涯.', '南宫沐风', '风恋绝尘',
'剑下孤魂', '一蓑烟雨', '领域★倾战', '威龙丶断魂神狙', '辉煌战绩', '屎来运赚', '伱、Bu够档次',
'九音引魂箫',
'骨子里的傲气', '霸海断长空', '没枪也很狂', '死魂★之灵']
def get_on_map():
on_dict = {}
# 根据 ttf 文件编码顺序对应更改
num_list = [6, 1, 3, 2, 5, 7, 4, 9, 0, 8]
# 创建 TTFont 实例
font = TTFont('yrx7.ttf')
# 返回一个字形名称列表,以字母顺序排序
glyphNames = font.getGlyphNames()
for i, name in enumerate(glyphNames[1:]):
# 读取 glyf 表, 获取各字形对应的 on 值
on_data = font['glyf'][name].flags
on_key = "".join([str(n) for n in on_data])
on_dict[on_key] = num_list[i]
return on_dict
def parse_ttf(woff):
map_dict = {}
woff_decode = base64.b64decode(woff)
with open('match7.ttf', 'wb') as f:
f.write(woff_decode)
# 创建 TTFont 实例
font = TTFont('match7.ttf')
font.saveXML('match7.xml')
# 返回一个字形名称列表,以字母顺序排序
glyphNames = font.getGlyphNames()
# 第一个是 .notdef
for name in glyphNames[1:]:
# 读取 glyf 表, 获取各字形对应的 on 值
on_data = font['glyf'][name].flags
on_key = "".join([str(n) for n in on_data])
map_dict[name.replace('uni', '&#x')] = get_on_map()[on_key]
return map_dict
def main():
player_dict = {}
num_list = []
headers = {
'user-agent': 'yuanrenxue.project'
}
cookies = {
'sessionid': ' your sessionid '
}
for page in range(1, 6):
url = "https://match.yuanrenxue.com/api/match/7?page=%s" % page
response = requests.get(url, headers=headers, cookies=cookies)
# 获取 woff 值
woff = response.json()['woff']
# 获取数据
value_list = response.json()['data']
# 解析 woff
woff_dict = parse_ttf(woff)
for index, value in enumerate(value_list):
# 解析获取胜点值
win_point = value['value'].split(' ')[:-1]
# 将经过编码的字符转为数字
num = "".join([str(woff_dict[i]) for i in win_point])
# 玩家名称对应的值
player = player_list[(index + 1) + (page - 1) * 10]
player_dict[num] = player
num_list.append(num)
print("最强玩家: " + player_dict[max(num_list)] + " ---> 胜点: " + max(num_list))
if __name__ == '__main__':
main()
TTFont 相关方法:
参考链接:fontTools-字体文件的解析
font.getGlyphOrder() # 返回一个字形名称列表,以其在文件中的顺序排序
font.getGlyphNames() # 返回一个字形名称列表,以字母顺序排序
font.getBestCmap() # 返回一个字形 ID 为键、字形名称为值的字典
font.getReverseGlyphMap() # 返回一个字形名称为键、字形 ID 为值的字典
font.getGlyphName(10000) # 输入字形 ID 返回字形名称
font.getGlyphID("uni70E0") # 输入字形名称返回字形 ID
font.getGlyphSet() # 返回一个 \_TTGlyphSet 对象,包含字形轮廓数据