文章目录
前言
总结下比赛中常用的加权框融合WBF
论文链接:https://arxiv.org/pdf/1910.13302.pdf
源码:https://github.com/ZFTurbo/Weighted-Boxes-Fusion
1.WBF
过滤bbox
filtered_boxes = prefilter_boxes(boxes_list, scores_list, labels_list, weights, skip_box_thr)
1.每个模型(可以是一个模型)中的每个预测框都被添加到一个单一的列表boxes_list中,筛选掉小于阈值skip_box_thr的框,用一个字典prefilter_boxes保存框的信息,将不同种类的目标保存为字典形式,并将此字典按分类分数得分C降序排列
# 截取函数的部分代码
filtered_boxes = prefilter_boxes(boxes_list, scores_list, labels_list, weights, skip_box_thr)
def prefilter_boxes(boxes, scores, labels, weights, thr):
new_boxes = dict() # 创建个字典
# 字典样式:{label:[int(label), float(score) * weights[t], weights[t], t, x1, y1, x2, y2]}
if label not in new_boxes:
new_boxes[label] = []
new_boxes[label].append(b) # 不同种类,单独用一个label键值表示
# Sort each list in dict by score and transform it to numpy array
for k in new_boxes:
current_boxes = np.array(new_boxes[k]) # 转成array数组
new_boxes[k] = current_boxes[current_boxes[:, 1].argsort()[::-1]] # 按score从大到小排序
return new_boxes
2.遍历每类,创建一个空列表new_boxes用来存放框信息和一个weighted_boxes用来存放融合后的框信息;
3.遍历每类中的box,尝试在列表weighted_boxes中找到一个匹配的框。根据weighted_boxes列表里的框和boxes里的框的iou值判断是否要进行融合(IoU > THR);
4.如果未找到匹配框,将列表boxes中的框添加到列表new_boxes和weighted_boxes的末端,作为新的框,接着继续遍历列表boxes中的下一个框;
5.如果找到匹配,将此框添加到列表weighted_boxes和对应匹配框的列表new_boxes中;
6.使用new_boxes中积累的所有T框,重新计算weighted_boxes中的置信度和框坐标得分,并使用以下融合公式进行融合,weighted_boxes列表里的框变为融合后的框;
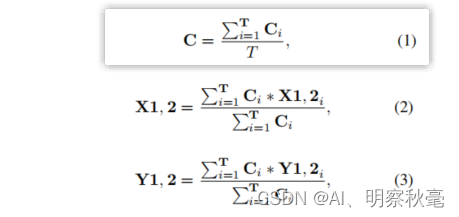
2-6步骤的代码
for label in filtered_boxes:
boxes = filtered_boxes[label]
new_boxes = []
weighted_boxes = np.empty((0, 8))
# Clusterize boxes
for j in range(0, len(boxes)):
index, best_iou = find_matching_box_fast(weighted_boxes, boxes[j], iou_thr)
if index != -1: # 不是第一个框
new_boxes[index].append(boxes[j])
weighted_boxes[index] = get_weighted_box(new_boxes[index], conf_type)
else:
new_boxes.append([boxes[j].copy()]) #
weighted_boxes = np.vstack((weighted_boxes, boxes[j].copy()))
find_matching_box_fast:根据融合列表里的框和boxes里的框的iou值判断是否要进行融合
get_weighted_box:根据Iou的值和论文的计算公式,对框进行融合
融合框公式对应的代码:
def get_weighted_box(boxes, conf_type='avg'):'''
'
Create weighted box for set of boxes
:param boxes: set of boxes to fuse
:param conf_type: type of confidence one of 'avg' or 'max'
:return: weighted box (label, score, weight, model index, x1, y1, x2, y2)
'
box = np.zeros(8, dtype=np.float32)
conf = 0
conf_list = []
w = 0
for b in boxes:
box[4:] += (b[1] * b[4:]) #
conf += b[1]
conf_list.append(b[1])
w += b[2]
box[0] = boxes[0][0] # 标签
if conf_type in ('avg', 'box_and_model_avg', 'absent_model_aware_avg'):
box[1] = conf / len(boxes)
elif conf_type == 'max':
box[1] = np.array(conf_list).max()
box[2] = w
box[3] = -1 # model index field is retained for consistency but is not used.
box[4:] /= conf
return box
7.执行完框的融合后,还要对融合框里的box再进行一次分类分数的调整并按照分类分数降序排序。如果融合的框置信分数很低,这可能意味着只有少量的模型预测到。因此,需要降低这类情况下的置信度分数。公式代码如下:
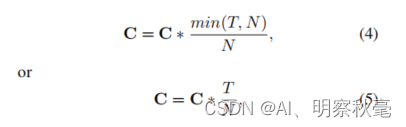
T:是重叠框的数量,N是模型的数量
**7步骤代码**
# 部分代码
weighted_boxes[i, 1] = weighted_boxes[i, 1] * min(len(weights), len(clustered_boxes)) / weights.sum()
overall_boxes = overall_boxes[overall_boxes[:, 1].argsort()[::-1]]
boxes = overall_boxes[:, 4:]
scores = overall_boxes[:, 1]
labels = overall_boxes[:, 0]
return boxes, scores, labels
2.使用wbf
首先,要pip install ensemble_boxes才能在ensemble_boxes导入wbf的相关模块
这里给出,单个模型的融合操作,多个模型的只要把预测框增加一个维度放到一个boxes列表里就行。
输入的boxes和scores都要是列表的形式,并且对box要进行归一化。可以自己进weighted_boxes_fusion函数看看。
# wbf
from ensemble_boxes import *
def run_wbf(boxes, scores, image_size=640, iou_thr=0.5, skip_box_thr=0.7, weights=None):
labels = [np.zeros(score.shape[0]) for score in scores]
#labels = [np.zeros(scores.shape[0]) for _ in range(len(scores))]
boxes = [box/(image_size) for box in boxes] #
scores = [score for score in scores]
boxes, scores, labels = weighted_boxes_fusion(boxes, scores, labels, weights=None, iou_thr=iou_thr, skip_box_thr=skip_box_thr)
boxes = boxes*(image_size)
return boxes, scores, labels
boxes = np.array([[100, 100, 210, 210, 0.72],
[250, 250, 420, 420, 0.8],
[220, 220, 320, 330, 0.92],
[200, 210, 300, 300, 0.81],
[220, 230, 315, 340, 0.9]])
box = boxes[:,:4]
box = np.expand_dims(box,axis=0)
scores = boxes[:,4]
scores = np.expand_dims(scores,axis=0)
wboxes, wscores, wlabels = run_wbf(box,scores)
print('wboxes:',wboxes,'\n','wscores:',wscores,'\n', 'wlabels',wlabels)
# 画图
def draw_boxes1(boxes,scores,color):
x1 = boxes[:,0] # 二维的变成一维的了
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
s = scores
print(s)
plt.plot([x1,x1],[y1,y2],color)
plt.plot([x1,x2],[y1,y1],color)
plt.plot([x1,x2],[y2,y2],color)
plt.plot([x2,x2],[y1,y2],color)
for i in range(len(s)):
plt.text(float(x1[i]), float(y2[i]), str(round(s[i],3)),ha='center', fontdict=None,bbox=dict(facecolor='red', alpha=0.5))
plt.figure()
ax1 = plt.subplot(121)
ax2 = plt.subplot(122)
plt.sca(ax1)
draw_boxes1(boxes,boxes[:,4],'b')
plt.sca(ax2)
draw_boxes1(wboxes,wscores,'r')
plt.show()

相同boxes经过nms和softnms的结果,在https://blog.csdn.net/weixin_41311686/article/details/128008640?spm=1001.2014.3001.5501
这个和nms,softnms不同,wbf返回的是融合框之后的坐标和分类分数,会改变原来预测的结果。
3.直观的理解wbf
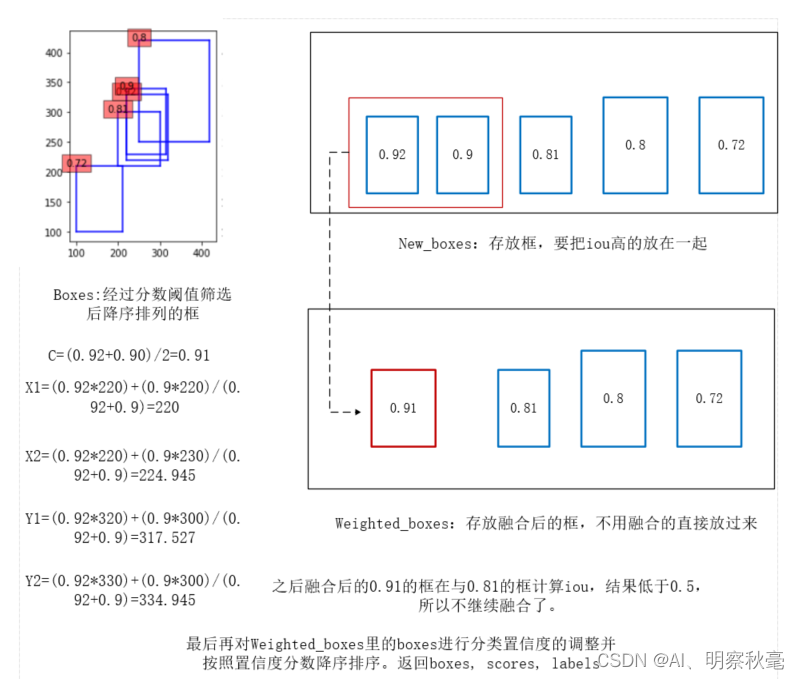
总结
加权框融合WBF相对于nms和softnms来说,速度要慢四倍的样子。更适合用在多个模型结果的融合,有点集成学习的感觉。可以用在对精度要求高,实时性要求不是很高实际项目或者比赛中。