python基础+
前言:
本文中的代码均取自编程小白的第一本Python入门书中,写本文章的主旨意在锻炼写博客的能力以及提升编程能力,如有侵权,请联系删除,如有错误,会及时更改。
所使用的IDE为jupyter,安装过程在这不详细介绍
1.打开一个文件:

# 打开files下的test.txt文件,且可读可写
file = open('./files/test.txt','r+')
# 在文件中写入 Hello world!
file.write("Hello world!")
# 将文件中内容赋值给file_read
file_read = file.readline()
# 关闭文件,必不可少
file.close()
# 输出文件中内容
print(file_read)
output:
2.字符串基本用法:
下面我们分别为last_name、first_name以及cool赋值字符串,会输出什么呢?
last_name = '狗'
first_name = '蛋'
cool = 'cool!'
output = last_name + first_name + cool
print(output)
想必各位应该已经想到了,就是输出与狗蛋ccol!

3.通过分片找出所需:
将下列网址中的图片名导出
‘http://ww1.site.cn/14d2e8ejw1exjogbxdxhj20ci0kuwex.jpg’
‘http://ww1.site.cn/85cc87jw1ex23yhwws5j20jg0szmzk.png’
‘http://ww2.site.cn/185cc87jw1ex23ynr1naj20jg0t60wv.jpg’
‘http://ww3.site.cn/185cc87jw1ex23yyvq29j20jg0t6gp4.gif’
提问: 如何将以上网址中的图片文件名输出呢,以第一个网址作为例子。
# 将网址赋值给url
url = 'http://ww1.site.cn/14d2e8ejw1exjogbxdxhj20ci0kuwex.jpg'
# -35就是将url中的值倒着数35个数开始给file_name赋值
file_name = url[-35:]
print(file_name)
得到的结果想必聪明的小伙伴们应该已经可以想到啦,就是图片的文件名,嘿嘿!!

4.查找数据位置
接下来我们写一个简单的查找数字位置的code,比如我们拥有一个字段158,如何查找他在一个手机号中的位置呢。

# 先将158放在我们的search中,以便调用
search = '158'
# 下面设置两个手机号
num_a = '158-9135-7829'
num_b = '167-7158-6788'
# 下面使用find()函数查找158字段的位置,并且输出
print(search + ' is at ' + str(num_a.find(search) + 1) + ' to ' + str(num_a.find(search) + len(search)))
print(search + ' is at ' + str(num_b.find(search) + 1) + ' to ' + str(num_b.find(search) + len(search)))
output:

以上的代码不难看懂,使用的是标题2中字符串的拼接,print() 函数中所有的项都是字符串类型,不是字符串类型的也转换成了字符串类型。其中str() 函数的作用就是将其他类型的值转换为字符串类型,find() 函数可以查找到search被赋予的值得索引位置,由于索引时从0开始的,所以需要在索引的基础之上加1,才是我们正常人所辨别的位置,后面使用len() 为获取search中值得长度,在索引的基础上加上长度可以得出查找字段的截止位置。
5.字符串格式化:

如何可以实现将以上A、B选项中的单词填入空中呢?
# 在这里大概列举三种方式:
# 1.直接使用.format进行填充{
}
print('{} is a word she can get what she {} for.'.format('With', 'came'))
# 2.将字符串先赋值,然后再讲变量放入{
}
print('{preposition} is a word she can get what she {verb} for.'.format(preposition = 'With', verb = 'came'))
# 3.通过索引的方式
print('{0} is a word she can get what she {1} for.'.format('With', 'came'))

输出的结果一致,在需要填空的数量很少时,没有什么影响,但是当需要填空的位置很多时,第一种方法与第三种不能及时的让我们知道填空内容的位置,第二种方法却可以很快找出填空内容,故此本人认为第二种方法比较好用!
6.自带函数:

练习题1:
1.初级难度:设计一个重量转换器,输入以“g”为单位的数字后返回换算成“Kg”的结果
在这里我们设计一个简单的函数来实现我们需要的结果。
# 创建一个重量转换的函数
def weight_convert(weight):
# 将输入进来的字符串转换为浮点型
weight = float(weight)
# 进行重量的转换
weight /= 1000
# 返回一个重量+‘kg’
return str(weight) + ' Kg'
# 输入一个重量(g)
weight = input("请输入一个重量(g):")
# 调用写好的重量函数,并且将上面输入进来的重量传入函数中
weight_Kg = weight_convert(weight)
# 按照一定格式输出重量转换
print(weight + " g 以 kg 为单位的大小是" + weight_Kg )

2.中级难度:设计一个求直角三角形斜边长的函数(两条直角边为参数,求最长边),如果直角边边长为3和4,那么返回的结果应为5
这个题目的思路也比较简单,和上题想死,我们创建一个函数,将求斜边的运算法则写入函数中,这样在我们需要求斜边时,只需要调用函数啦!
在这里我们调用了一个第三方库,numpy是一个功能十分强大的第三方库,在以后的博客中可能会讲到
import numpy as np
# 创建一个求直角三角形斜边的函数
def hypotenuse(a, b):
# 求斜边定理
c = np.sqrt((a ** 2) +(b ** 2))
# 将斜边返回
return str(c)
# 下面的内容就不难理解了,输入两个直角边,调用函数输出斜边
input_a = input("请输入第一条直角边:")
input_a = float(input_a)
input_b = input("请输入第二条直角边:")
input_b = float(input_b)
output_c = hypotenuse(input_a, input_b)
print("直角三角形的斜边长度为:" + output_c)

练习题2:
1.设计这样一个函数,可以在电脑中创建相应数量的文件

一个比较简单的思路就是我们使用一个for遍历,从1到10创建十次文件,并使用**.format()**来对文件名进行编号。
for i in range(1, 11):
file = open('./files/{}.txt'.format(i), 'w+')
file.close()
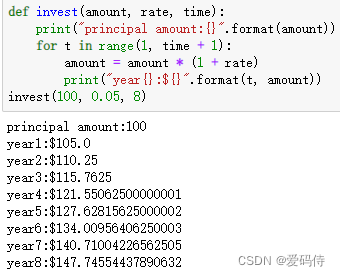
2.复利是一件神奇的事情,正如富兰克林所说:“复利是能够将所有铅块变成金块的石头”。设计一个复利计算函数 invest(),它包含三个函数:amount(资金),rate(利率),time(投资时间)。输入每个参数后调用函数,应该返回每一年的资金总额。他看起来就应该像这样(假设利率为5%)
在这里呢,我们还是创建一个函数,毕竟我们学习Pyhton是面向对象的编程嘛。
# 这次创建的函数需要我们输入资金,利率以及时间,想起来也比较简单
def invest(amount, rate, time):
print("principal amount:{}".format(amount))
for t in range(1, time + 1):
amount = amount * (1 + rate)
print("year{}:${}".format(t, amount))
invest(100, 0.05, 8)
3.打印1~100内的偶数
比较简单直接放上code
for i in range(100):
if i % 2 == 0:
print(i)
7.综合练习:
接下来我们设计一个综合案例
在这里为了节省时间直接将书中的思想直接贴上

分为以下几个模块
1.掷骰子模块
在本次游戏中我们有三颗骰子,骰子的点数我们使用产生随机数的函数产生1-6的随机数字,并且通过一个while循环来实现控制骰子数目。
def roll_dice(numbers=3, points=None):
print('<<<<< Roll The Dice! >>>>>')
if points is None:
# 在这里我们创建一个空列表来存放骰子的点数
points = []
while numbers > 0:
# 产生骰子的点数
point = np.random.randint(1, 7)
points.append(point)
numbers = numbers - 1
return points
2.胜负模块
def roll_result(total):
# 大为11到18,小为3到10,因为最小为3,最大为18
isBig = 11 <= total <= 18
isSmall = 3 <= total <= 10
if isBig:
return 'Big'
elif isSmall:
return 'small'
3.游戏开始模块
如果我们的输入与随机数产生的大小相同则胜利,否则为输
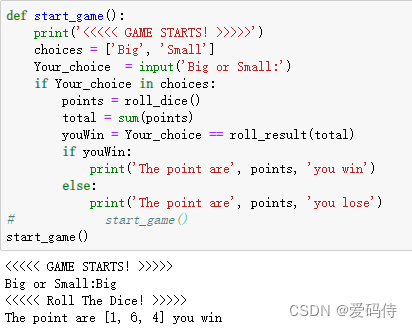
def start_game():
print('<<<<< GAME STARTS! >>>>>')
# 下面我们来输入自己的决定
choices = ['Big', 'Small']
Your_choice = input('Big or Small:')
# 首先我们要确保,我们的输入的为Big以及Small,否则后续无法正常运行
if Your_choice in choices:
# 在这里我们调用函数,得到三颗骰子点数的列表
points = roll_dice()
# 求和
total = sum(points)
# 判定结果
youWin = Your_choice == roll_result(total)
if youWin:
print('The point are', points, 'you win')
else:
print('The point are', points, 'you lose')
# start_game()
# 在这里我们调用开始游戏模块,进入游戏
start_game()
练习题3:
1.在最后一个项目的基础上增加这样的功能,下注金额和赔率。具体规则如下:
- 初始金额为1000元
- 金额为0时游戏结束
- 默认赔率1倍,也就是说押对了能得到相应的金额,押错了会输掉相应金额
我们加上一些简单的金钱功能、想法就是在开始界面加入一个充值功能,并且加入while循环,这样就可以一局接着一局完啦,并且在钱为0时,游戏就应该结束,当钱款小于0时应该让玩游戏的同志”还钱“,并且结束游戏,结束游戏我们使用break。
下面让我们来看一下改进后的code
def start_game():
money = input('充值金额:')
while True:
money = float(money)
print('<<<<< GAME STARTS! >>>>>')
choices = ['Big', 'Small']
Your_choice = input('Big or Small:')
if Your_choice in choices:
points = roll_dice()
cash_pledge = input('How much you wanna bet ? --')
cash_pledge = float(cash_pledge)
balance_outstanding = money - cash_pledge
total = sum(points)
youWin = Your_choice == roll_result(total)
if youWin:
money = money + cash_pledge
print('The point are', points, 'you win')
print('You gained ' + str(cash_pledge) + ',you have' + str(money))
else:
money = balance_outstanding
print('The point are', points, 'you lose')
print('You lost ' + str(cash_pledge) + ',you have' + str(money))
if money < 0:
print('把欠的钱抓紧还了')
break
elif money == 0:
print('没钱了')
break
# start_game()
start_game()

8.多重推导:
在进行遍历时我们也可以使用**b = [i for i in range(1,20000)]**方法来进行,并且有着更加意想不到的效果,我们来测试一下运行时间。可以看出多重推导的方法有着更好的计算能力。
import time
a = []
t0 = time.clock()
for i in range(1,20000):
a.append(i)
print(time.clock() - t0, "seconds process time")
t0 = time.clock()
b = [i for i in range(1,20000)]
print(time.clock() - t0, "seconds process time")

a = [i**2 for i in range(1,10)]
print(a)
c = [j+1 for j in range(1,10)]
print(c)
k = [n for n in range(1,10) if n % 2 ==0]
print(k)
z = [letter.lower() for letter in 'ABCDEFGHIGKLMN']
print(z)

看起来是更加简洁了哈,不过有时可能在理解时出现了一些些难度。
9.切片:
随便写的切片,括号中输入的参数是需要进行切片的位置。
# eg1
lyric = 'The night begin to shine, the night begin to shine'
words = lyric.split('e')
print(words)

是不是输出有些丑呢,我们对空格进行切片,看一下输出

是不是好看多了,在我们处理数据时也要注意,不要胡闹。
尾言:
本次的分享结束啦,如果有错误有疑问请提出!!欢迎大家的批评!指正!