MMSE适合处理平稳序列,因为MMSE是一个均匀加权的最优化问题,也就是说,每一时刻的误差信号对目标函数的贡献权重是相同的,如果对于非平稳的语音信号效果就不太好了。
RLS重新定义了目标函数:


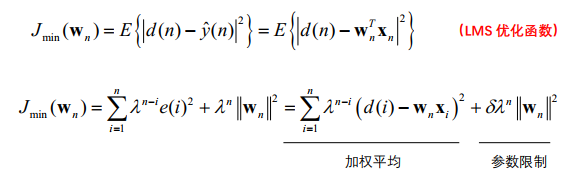







扫描二维码关注公众号,回复:
14863019 查看本文章

一个广泛的共识是RLS 算法的收敛速度和跟踪性能都优于 LMS 算法,所付出的代价是需要更复杂的计算 。
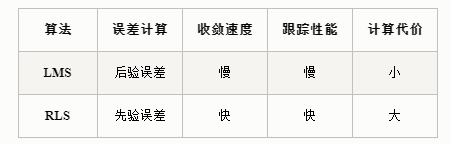
- 优点:RLS自适应滤波器提供更快的收敛速度和跟踪性能。
- 缺点:由于RLS 使用了自相关矩阵的逆矩阵的递推,所以,一旦输入信号的自相关矩阵接近奇异时RLS 的收敛速度和跟踪性能会严重恶化 。
代码如下:
import numpy as np
import librosa
import soundfile as sf
import pyroomacoustics as pra
def rls(x, d, N = 4, lmbd = 0.999, delta = 0.01):
nIters = min(len(x),len(d)) - N
lmbd_inv = 1/lmbd
u = np.zeros(N)
w = np.zeros(N)
P = np.eye(N)*delta
e = np.zeros(nIters)
for n in range(nIters):
u[1:] = u[:-1]
u[0] = x[n]
e_n = d[n] - np.dot(u, w)
r = np.dot(P, u)
g = r / (lmbd + np.dot(u, r))
w = w + e_n * g
P = lmbd_inv*(P - np.outer(g, np.dot(u, P)))
e[n] = e_n
return e
# x 原始参考信号
# v 理想mic信号
# 生成模拟的mic信号和参考信号
def creat_sim_sound(x,v):
rt60_tgt = 0.08
room_dim = [2, 2, 2]
e_absorption, max_order = pra.inverse_sabine(rt60_tgt, room_dim)
room = pra.ShoeBox(room_dim, fs=sr, materials=pra.Material(e_absorption), max_order=max_order)
room.add_source([1.5, 1.5, 1.5])
room.add_microphone([0.1, 0.5, 0.1])
room.compute_rir()
rir = room.rir[0][0]
rir = rir[np.argmax(rir):]
# x 经过房间反射得到 y
y = np.convolve(x,rir)
scale = np.sqrt(np.mean(x**2)) / np.sqrt(np.mean(y**2))
# y 为经过反射后到达麦克风的声音
y = y*scale
L = max(len(y),len(v))
y = np.pad(y,[0,L-len(y)])
v = np.pad(v,[L-len(v),0])
x = np.pad(x,[0,L-len(x)])
d = v + y
return x,d
if __name__ == "__main__":
x_org, sr = librosa.load('female.wav',sr=8000)
v_org, sr = librosa.load('male.wav',sr=8000)
x,d = creat_sim_sound(x_org,v_org)
e = rls(x, d, N=256)
e = np.clip(e,-1,1)
sf.write('x.wav', x, sr, subtype='PCM_16')
sf.write('d.wav', d, sr, subtype='PCM_16')
sf.write('rls.wav', e, sr, subtype='PCM_16')参考资料: