Transformer
Transformer 是 2017 年引入的深度学习模型,主要用于自然语言处理领域。与循环神经网络一样,Transformers 旨在处理顺序数据(例如自然语言),以执行翻译和文本摘要等任务。但是,与 RNN 不同,Transformers 不需要按顺序处理顺序数据。

Why do we need the Transformer?
- RNN
- 是最经典的处理 Sequence 的模型,单向 RNN 或双向 RNN 等等。
- RNN 存在的问题:难以并行化处理
于是,就有人提出用 CNN 取代 RNN
-
CNN 替代 RNN
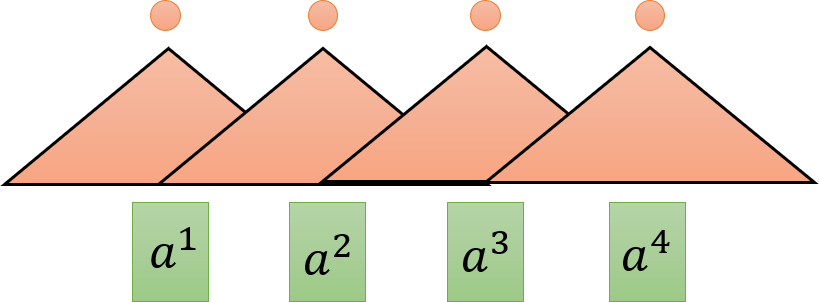
- CNN filters:每一个三角形代表一个
filter输入为seq的一小段,输出一个数值(做内积得到),不同的filter对应seq中不同的部分。

- 每一个 CNN 只能考虑有限的内容,RNN 能考虑一整个句子
- 考虑很长的句子:叠很多层 CNN,上层的
filter就可以考虑较多资讯,因为上层的filter会把下层的filter的输出当作输入 - 问题:必须叠很多层才有办法做到考虑较长的句子,因此出现了
self-attention机制

- CNN filters:每一个三角形代表一个
self-attention layer
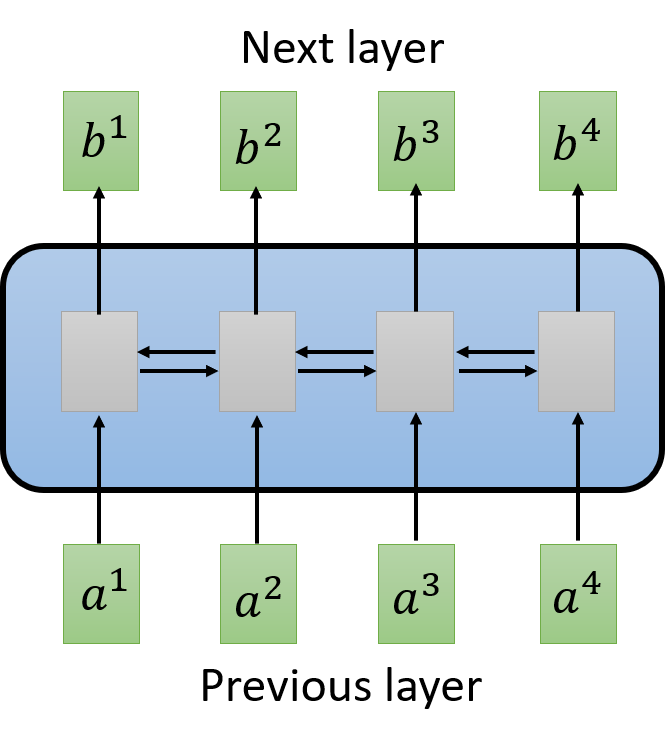
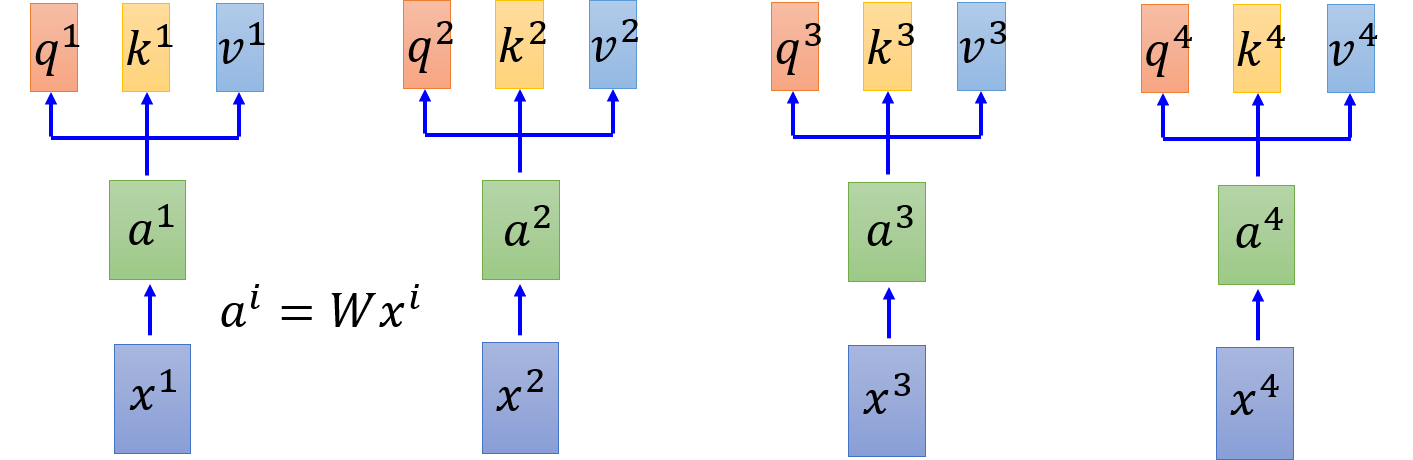
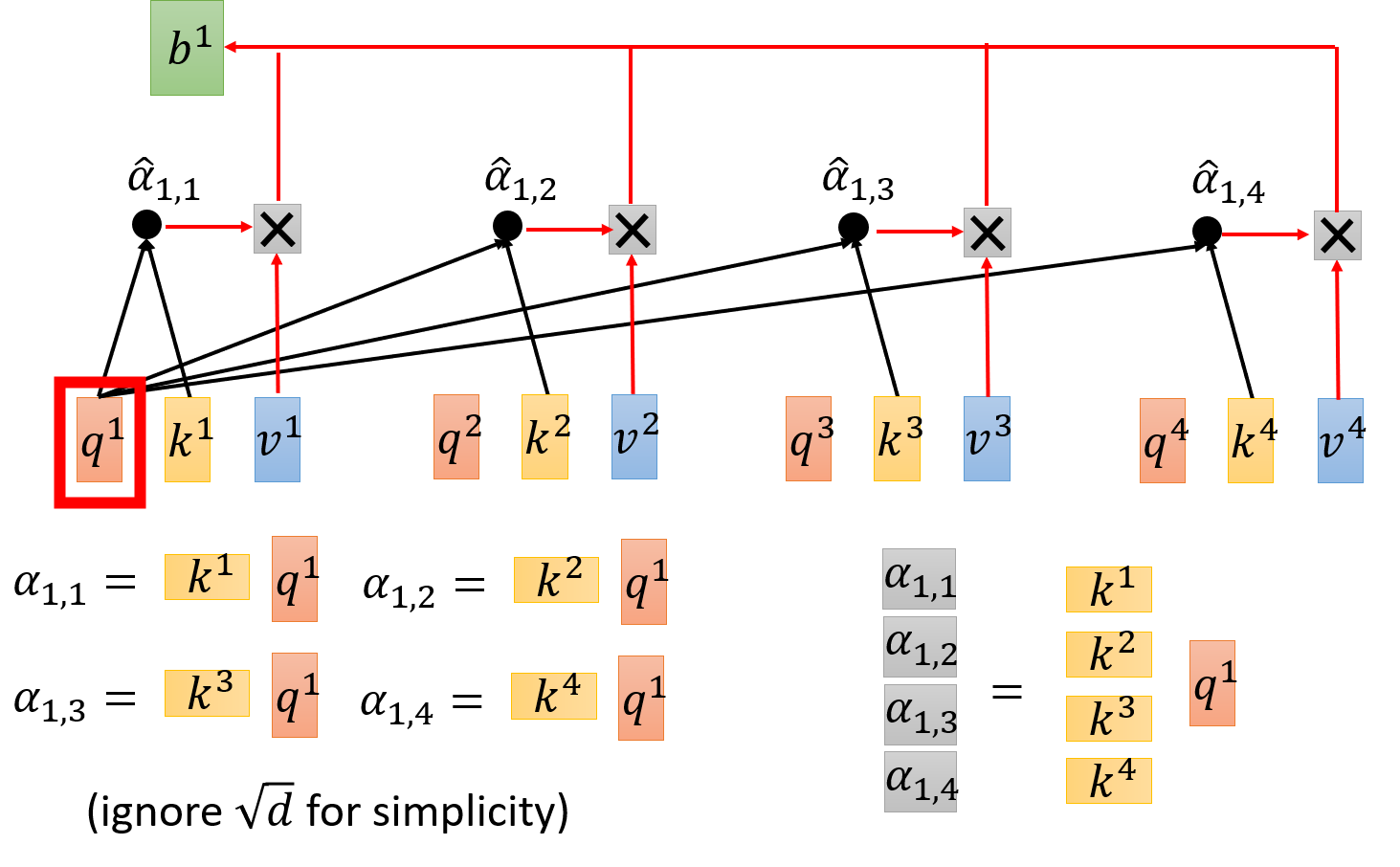
例如,输入 x 1 , x 2 , x 3 , x 4 x_1,x_2,x_3,x_4 x1,x2,x3,x4 通过 embedding 得到 a 1 , a 2 , a 3 , a 4 a_1,a_2,a_3,a_4 a1,a2,a3,a4,每一个 input 都分别乘以三个不同的 transformation(矩阵)得到三个不同的 vector q , k , v q,k,v q,k,v。
- q q q: query (to match others)
q i = W q a i q^i = W^q a^i qi=Wqai
- k k k: key (to be matched)
k i = W k a i k^i = W^k a^i ki=Wkai
- v v v: information to be extracted
v i = W v a i v^i = W^v a^i vi=Wvai
拿每个 query q q q 去对每个 key k k k 做 attention,文中使用 Scaled Dot-Product Attention:
α 1 , i = q 1 ⋅ k i / d \alpha_{1,i} = q^1 \cdot k^i / \sqrt{d} α1,i=q1⋅ki/d
其中, ⋅ \cdot ⋅ 表示 dot product, d d d 是 q q q 的维度,能够抵消因维度引起的不平衡。
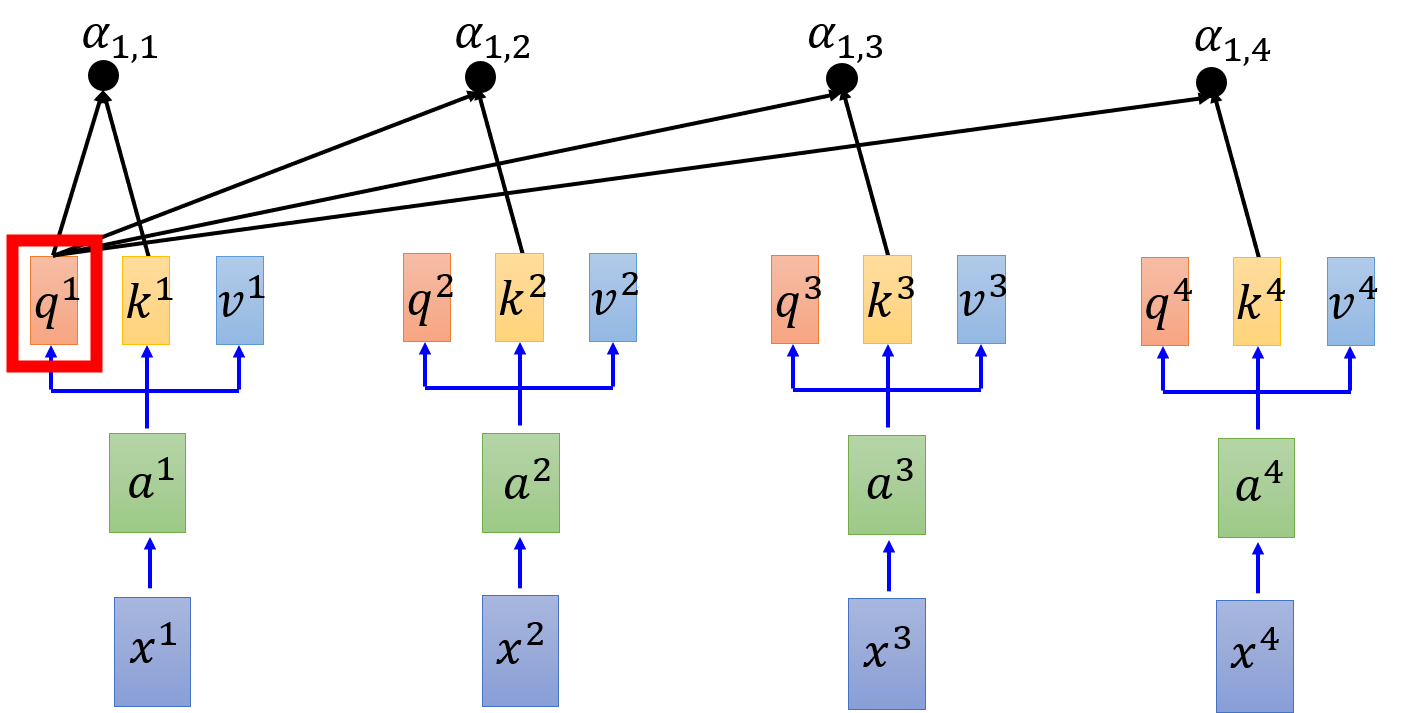
然后,再进行 softmax 进行激活
α ^ 1 , i = exp ( α 1 , i ) ∑ j exp ( α 1 , i ) \hat{\alpha}_{1,i} = \frac{\exp \left( \alpha_{1,i} \right)}{\sum\limits_j \exp\left( \alpha_{1,i} \right)} α^1,i=j∑exp(α1,i)exp(α1,i)
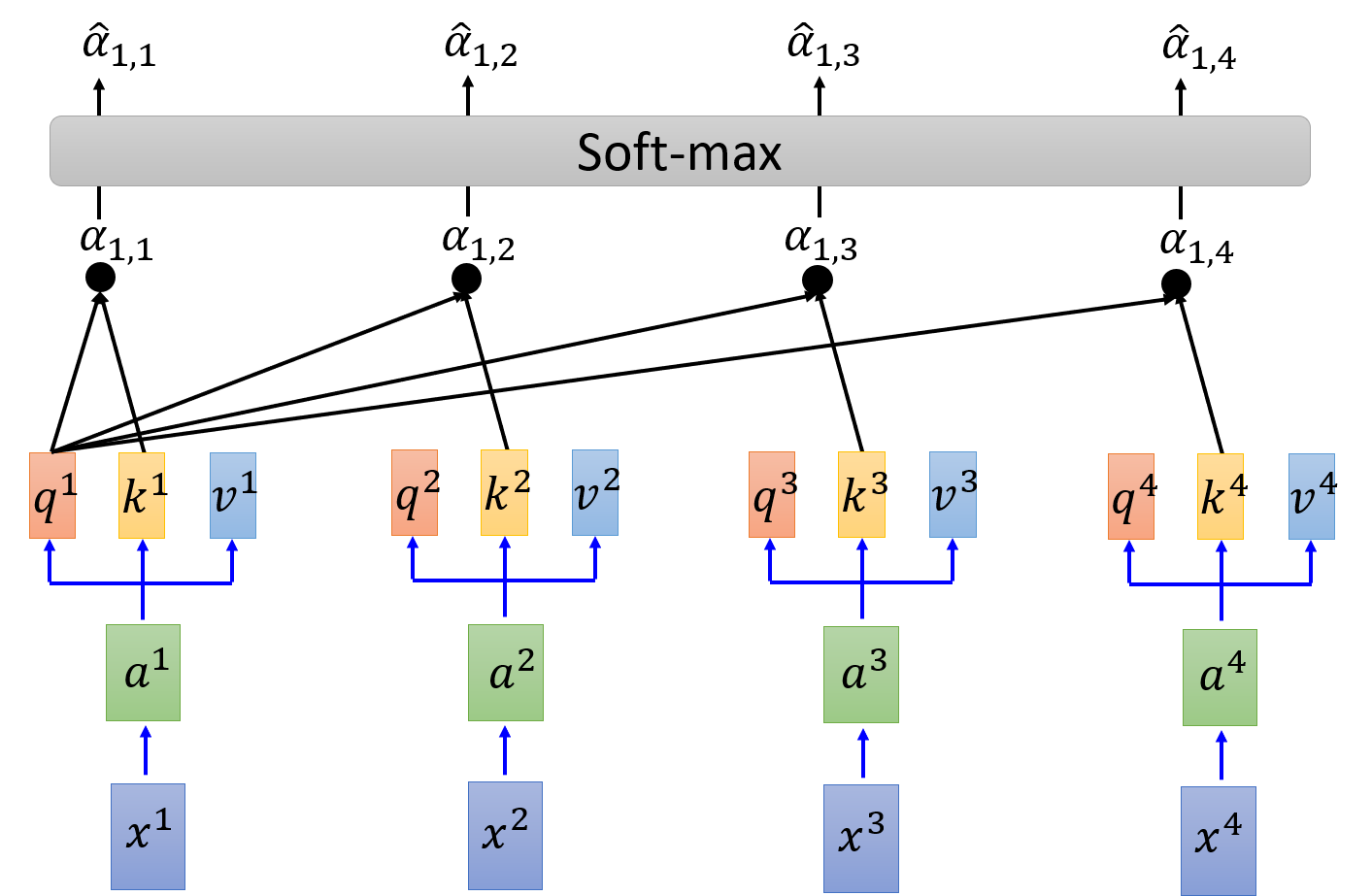
拿每个 query q q q 去对每个 key k 做 attention
b 1 = ∑ i α ^ 1 , i v i b^1 = \sum\limits_i \hat{\alpha}_{1,i} v^i b1=i∑α^1,ivi
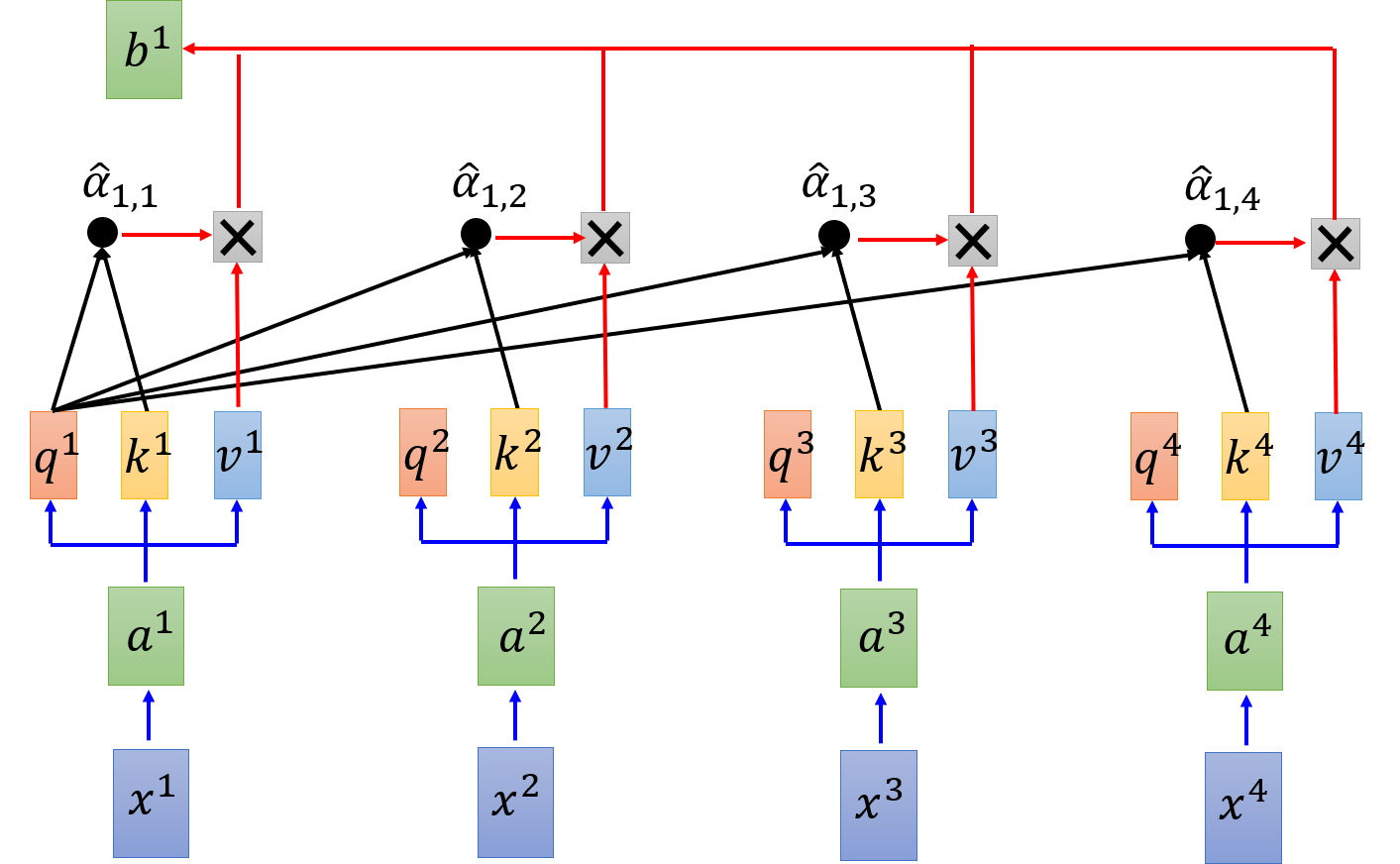
这样, b 1 , b 2 , b 3 , b 4 b^1,b^2,b^3,b^4 b1,b2,b3,b4 可以并行计算得到。
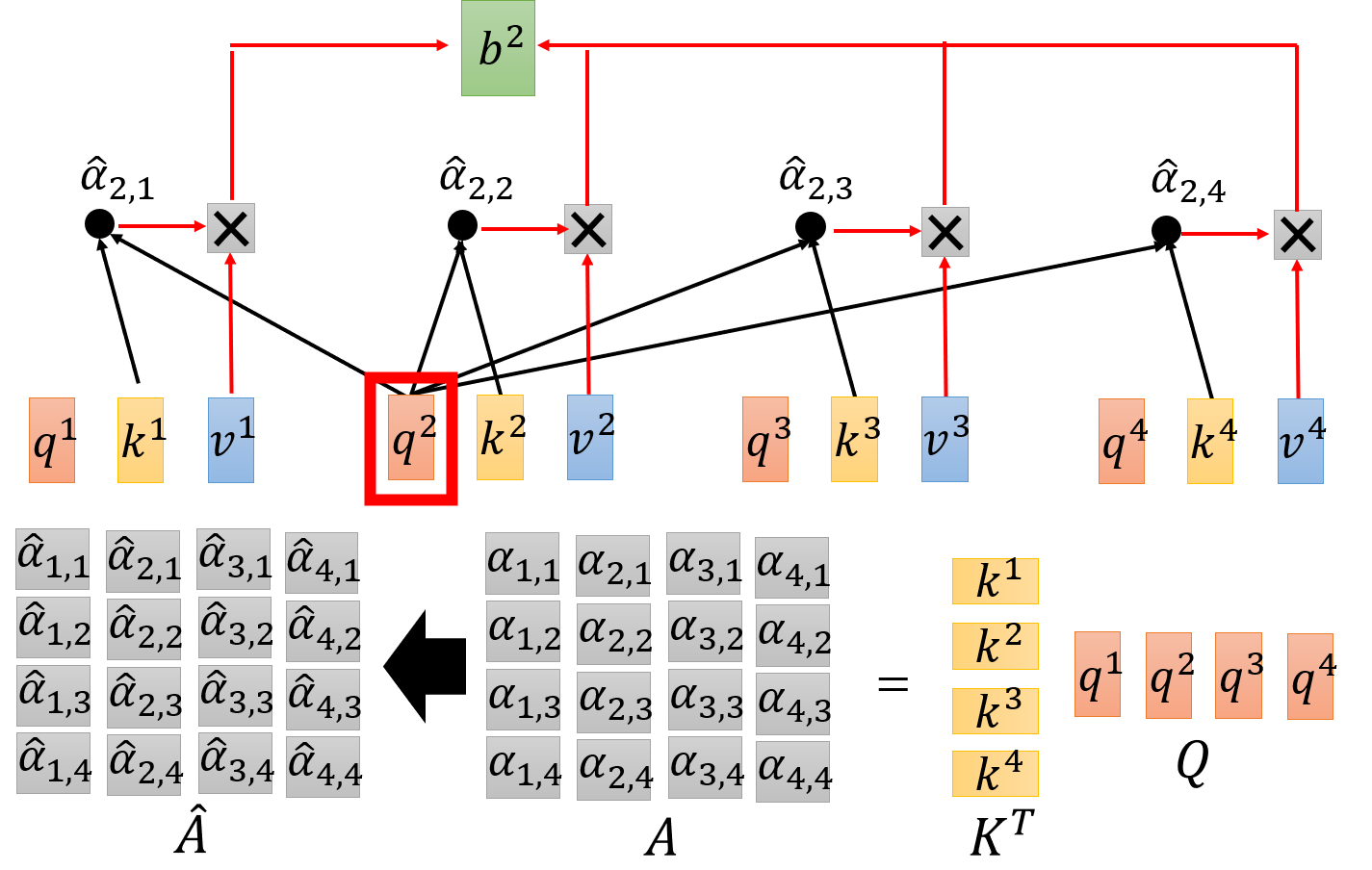
接下来,使用矩阵运算来说明 self-attention layer 的过程:
- Step 1:
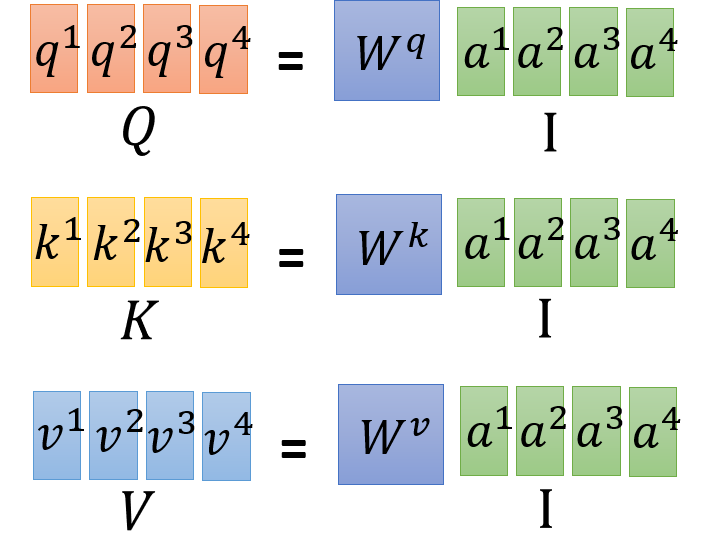
- Step 2:
-
Step 3:
-
Step 4:
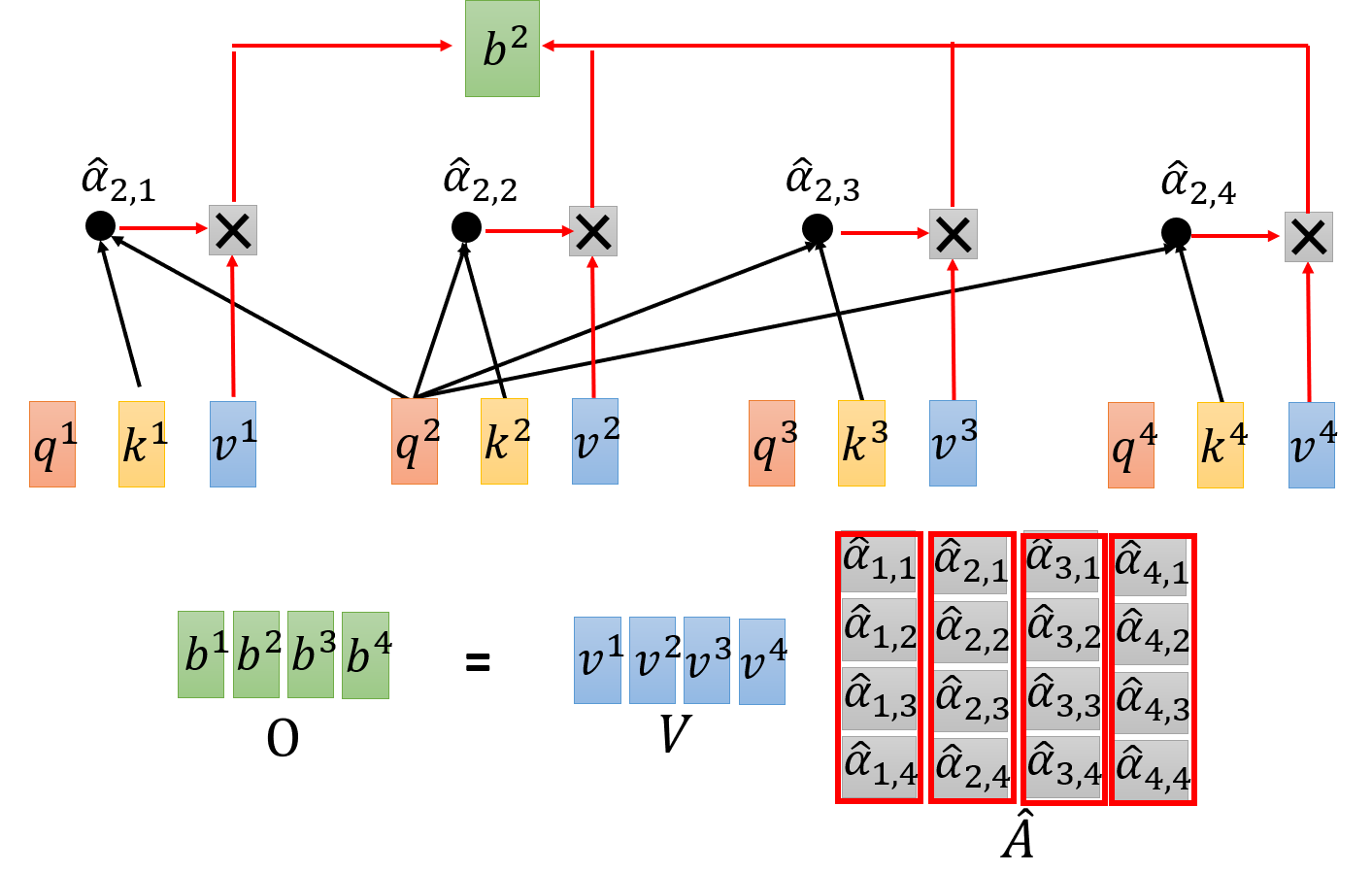
于是,可得
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
如下图所示:

反正就是一堆矩阵乘法,可以用 GPU 可以加速
Multi-head Self-attention
Multi-head Self-attention 允许模型共同注意来自不同位置的不同表示子空间的信息。不同的 head 可以各司其职,学习到不同意义的特征(如 local 的或者 global 的)。
MultiHead ( Q , K , V ) = Concat ( head 1 , ⋯ , head h ) W O \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1,\cdots,\text{head}_h) W^O MultiHead(Q,K,V)=Concat(head1,⋯,headh)WO
其中
head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q,KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
下图是 2 head 的注意力图
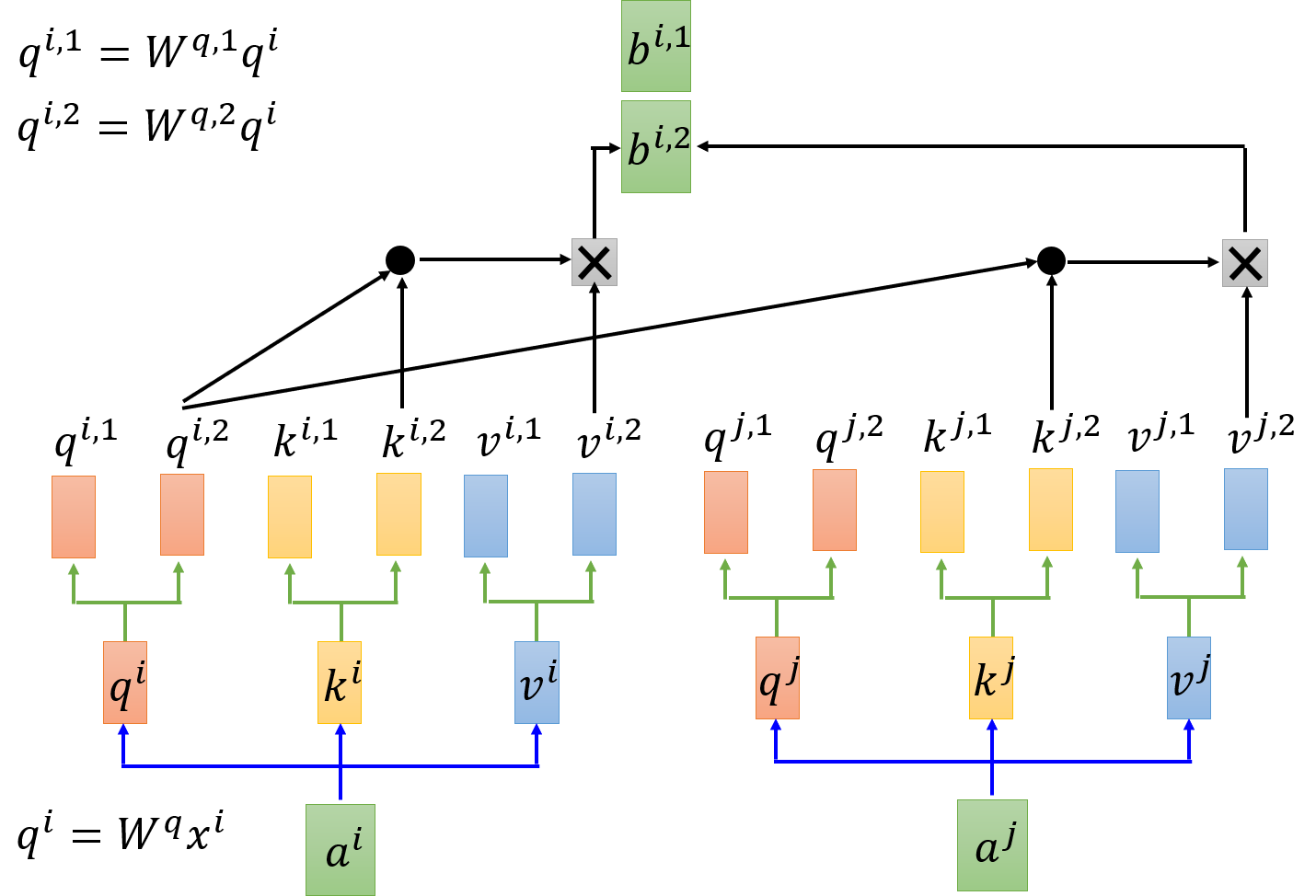
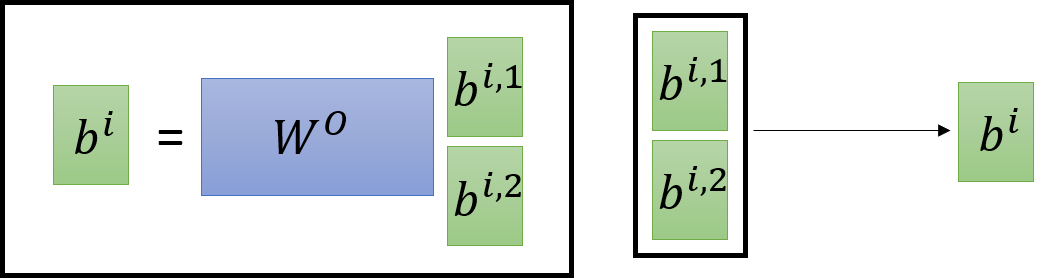
得到 b i , 1 , b i , 2 b^{i,1},b^{i,2} bi,1,bi,2 可以通过 concatenate 进行拼接,还可以引入 W W W 进行维度的变化
Positional Encoding
- 原始的
self-attention中没有考虑位置信息,所以可以引入一个的位置向量 e i e_i ei,不是学出来的而是人设置的。 - 其他方法:使用
one-hot encoding表示的 p i p_i pi 为 x i x_i xi 表示其位置
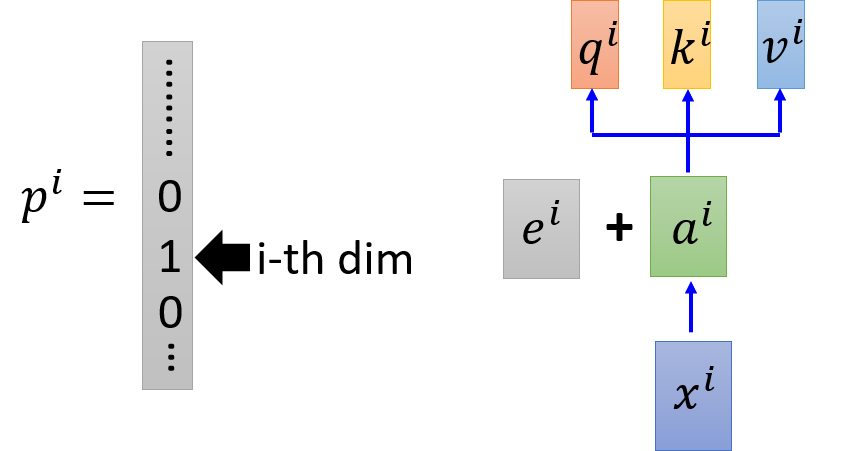
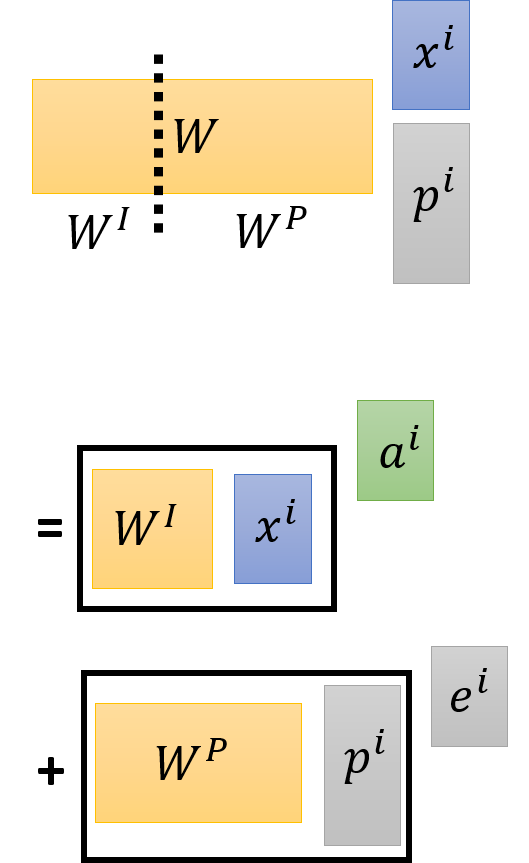
具体地,可以将 x x x 和 p p p 进行 concatenate 或者上图直接在 a i a^i ai 中加入 e i e^i ei。
keras 官方给出的 embedding layer 实现如下
class TokenAndPositionEmbedding(layers.Layer):
def __init__(self, maxlen, vocab_size, embed_dim):
super(TokenAndPositionEmbedding, self).__init__()
self.token_emb = layers.Embedding(input_dim=vocab_size, output_dim=embed_dim)
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=embed_dim)
def call(self, x):
maxlen = tf.shape(x)[-1]
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
x = self.token_emb(x)
return x + positions
Seq2seq Architecture
原始 seq2seq2 model 由两个 RNN 分别组成了 Encoder、Decoder,可以应用于机器翻译。

上图中原本 Encoder 里面是双向 RNN,Decoder 里面是一个单向 RNN,下图把两个都用 Self-attention layer 取代,可以到达一样的目的而且可以平行运算。

一个动画形象地刻画这一过程

Transformer
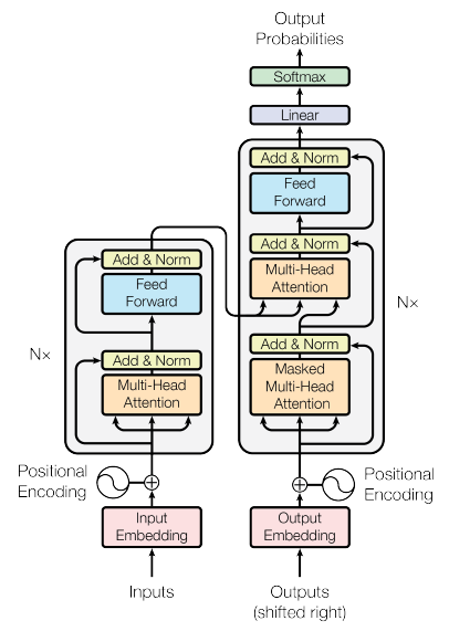
下图是 transformer 的架构图:
-
Encoder
-
Input通过Input Embedding,考虑位置资讯,加上人为设置的Positional Encoding,进入会重复 $N $次的blockMulti-head:进到 Encoder 里面,他是 Multi-head Attention的,也就是 q , k , v q,k,v q,k,v 有多个,在里面做 q k v qkv qkv 个别乘以 a a a 的运算,算出 α \alpha α 最后得到 b b b

Add & Norm: 把Multi-head attention的inputa a a 和outputb b b 加起来得到 b ′ b' b′,再做Layer Normalization- 计算完后丢到前向传播,再经过一个
Add & Norm
-
-
Decoder
input为前一个 time step 的output,通过output embedding,考虑位置资讯,加上人为设置的positional encoding,进入会重复 n n n 次的blockMasked Multi-head Attention:做Attention,Masked 表示只会 attend 到已经产生出来的 sequence,再经过Add & Norm Layer- 再经过
Multi-head Attention Layer,attend 到之前 Encoder 的输出,然后再进到Add & Norm Layer - 计算完丢到 Feed Forward 前向传播,再做
Linear和Softmax,产生最终输出
Transformer block 实现如下:
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = keras.Sequential(
[layers.Dense(ff_dim, activation="relu"), layers.Dense(embed_dim),]
)
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
下载和准备数据集:
vocab_size = 20000 # Only consider the top 20k words
maxlen = 200 # Only consider the first 200 words of each movie review
(x_train, y_train), (x_val, y_val) = keras.datasets.imdb.load_data(num_words=vocab_size)
print(len(x_train), "Training sequences")
print(len(x_val), "Validation sequences")
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_val = keras.preprocessing.sequence.pad_sequences(x_val, maxlen=maxlen)
使用 transformer 创建分类器模型
embed_dim = 32 # Embedding size for each token
num_heads = 2 # Number of attention heads
ff_dim = 32 # Hidden layer size in feed forward network inside transformer
inputs = layers.Input(shape=(maxlen,))
embedding_layer = TokenAndPositionEmbedding(maxlen, vocab_size, embed_dim)
x = embedding_layer(inputs)
transformer_block = TransformerBlock(embed_dim, num_heads, ff_dim)
x = transformer_block(x)
x = layers.GlobalAveragePooling1D()(x)
x = layers.Dropout(0.1)(x)
x = layers.Dense(20, activation="relu")(x)
x = layers.Dropout(0.1)(x)
outputs = layers.Dense(2, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
训练和评估
model.compile("adam", "sparse_categorical_crossentropy", metrics=["accuracy"])
history = model.fit(
x_train, y_train, batch_size=32, epochs=2, validation_data=(x_val, y_val)
)
打印信息如下:
Epoch 1/2
782/782 [==============================] - 15s 18ms/step - loss: 0.5112 - accuracy: 0.7070 - val_loss: 0.3598 - val_accuracy: 0.8444
Epoch 2/2
782/782 [==============================] - 13s 17ms/step - loss: 0.1942 - accuracy: 0.9297 - val_loss: 0.2977 - val_accuracy: 0.8745
Attention Visualization
single head

multi-head
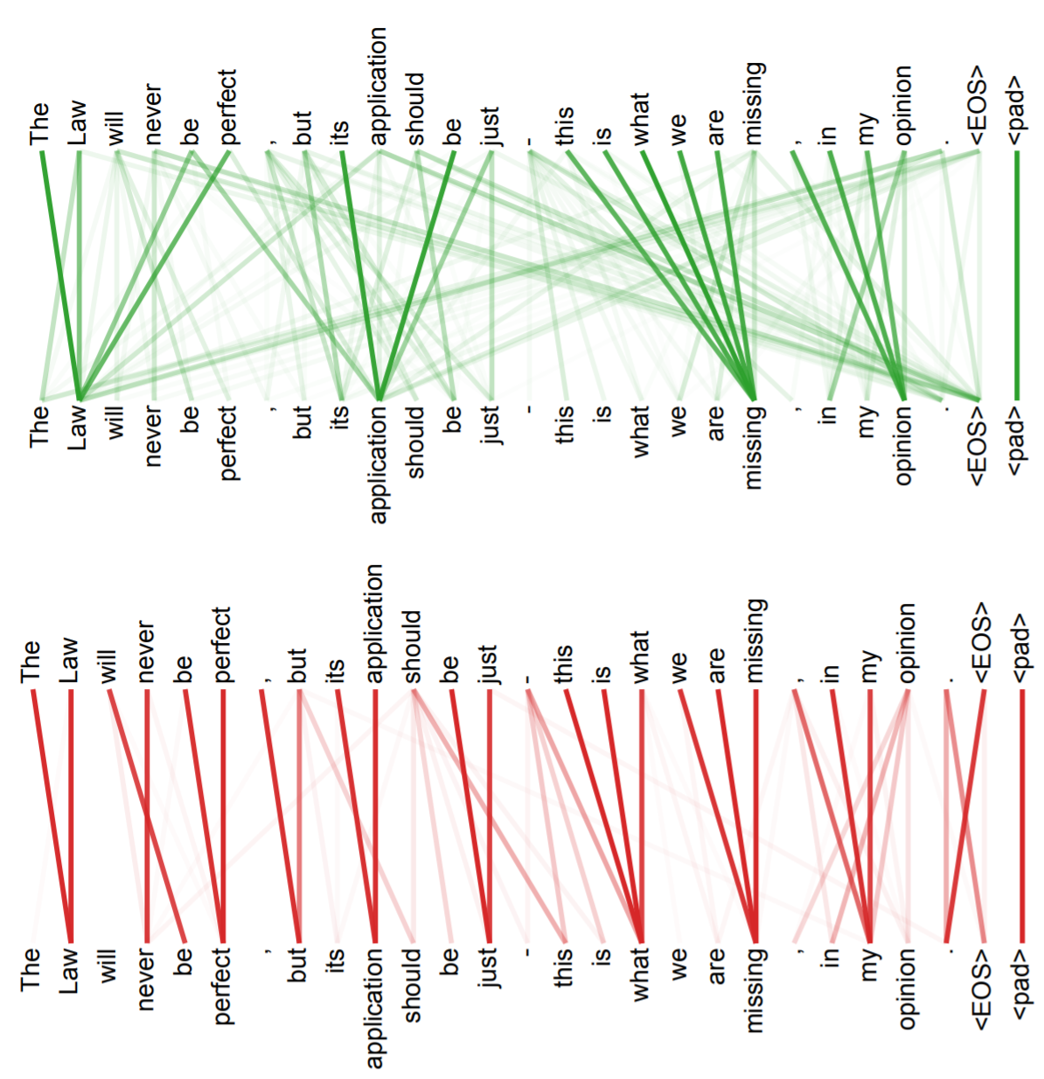
Example Application
- Summarizer By Google
input 为一堆文档,output 为一篇文章(summarize)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fEMpvaW3-1612535321252)(https://arxiv.org/abs/1801.10198 “Generating Wikipedia by Summarizing Long Sequences”)]](https://cdn.jsdelivr.net/gh/ZhouKanglei/jidianxia/2021-2-5/1612530043763-example.png)
- Universal Transformer
横向(时间上)是Transformer,纵向是RNN
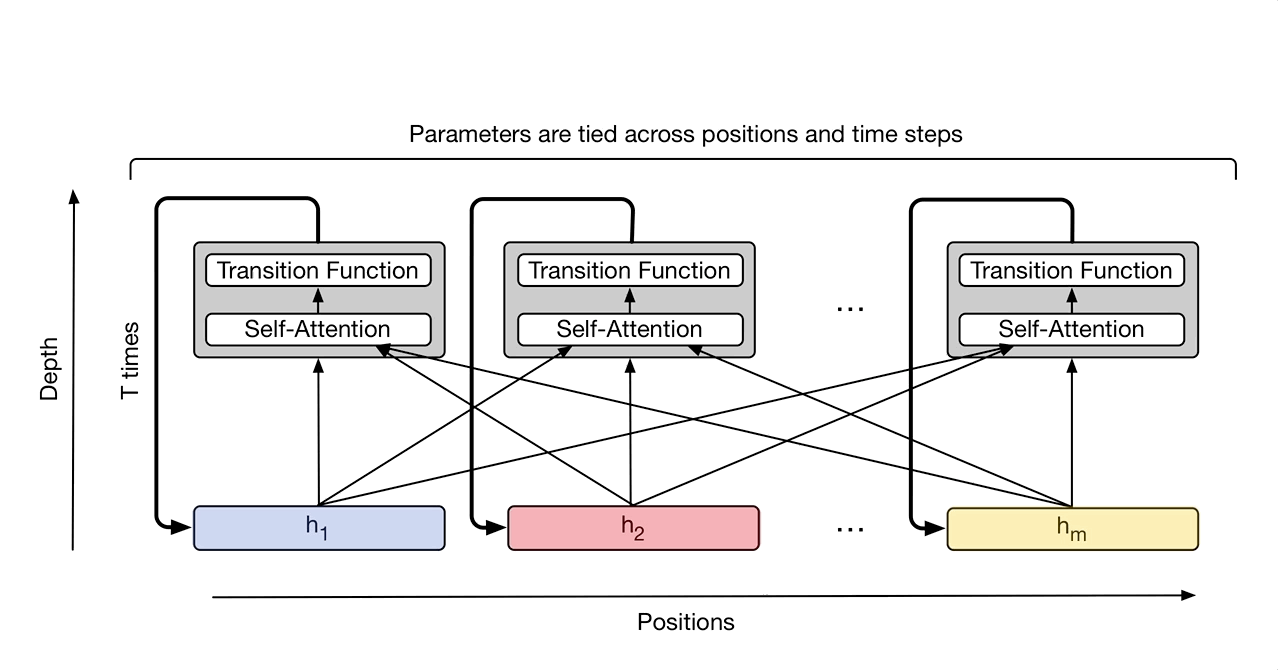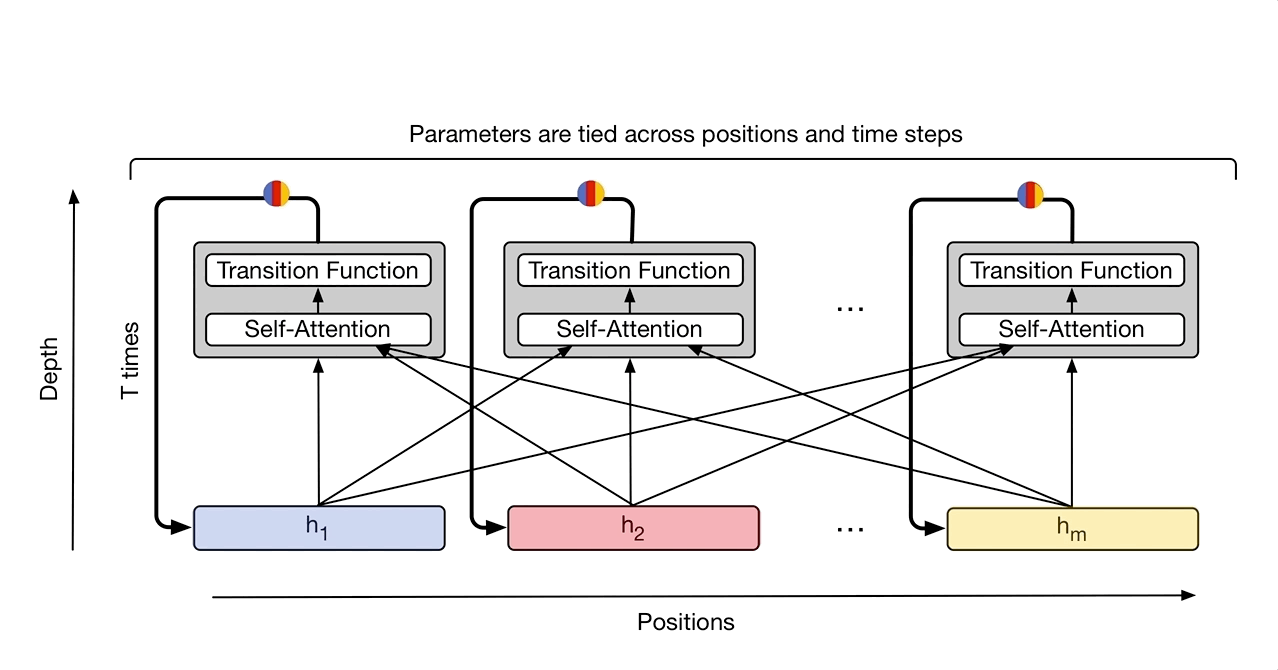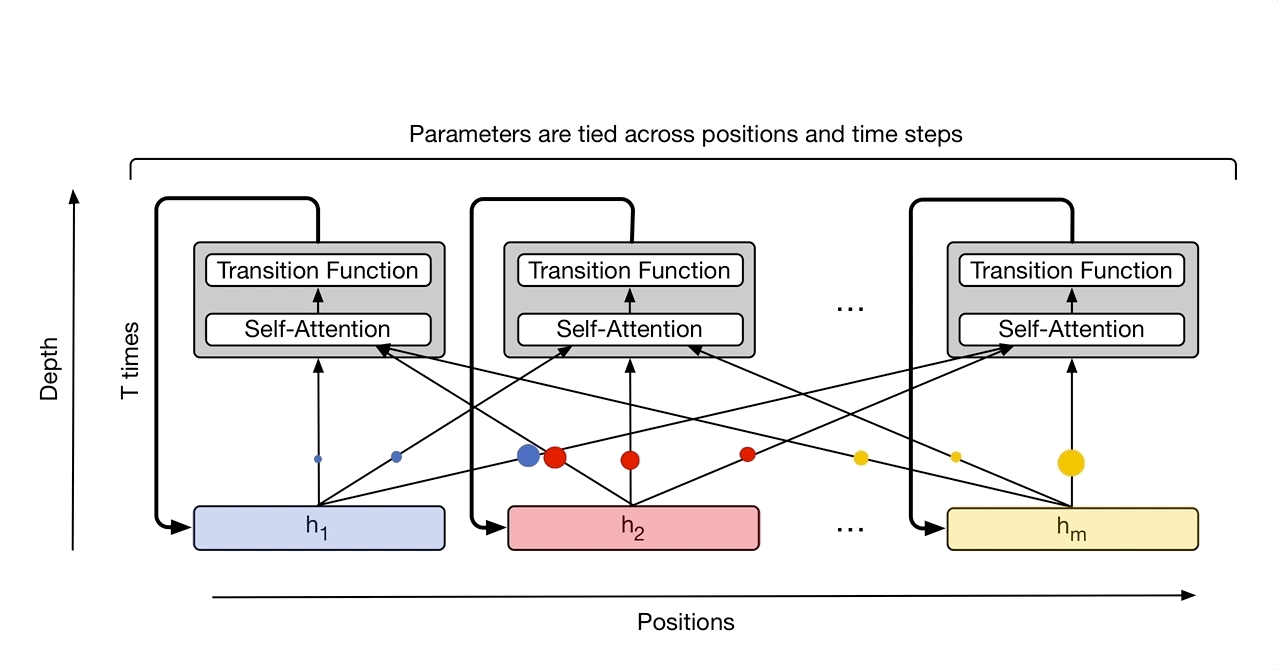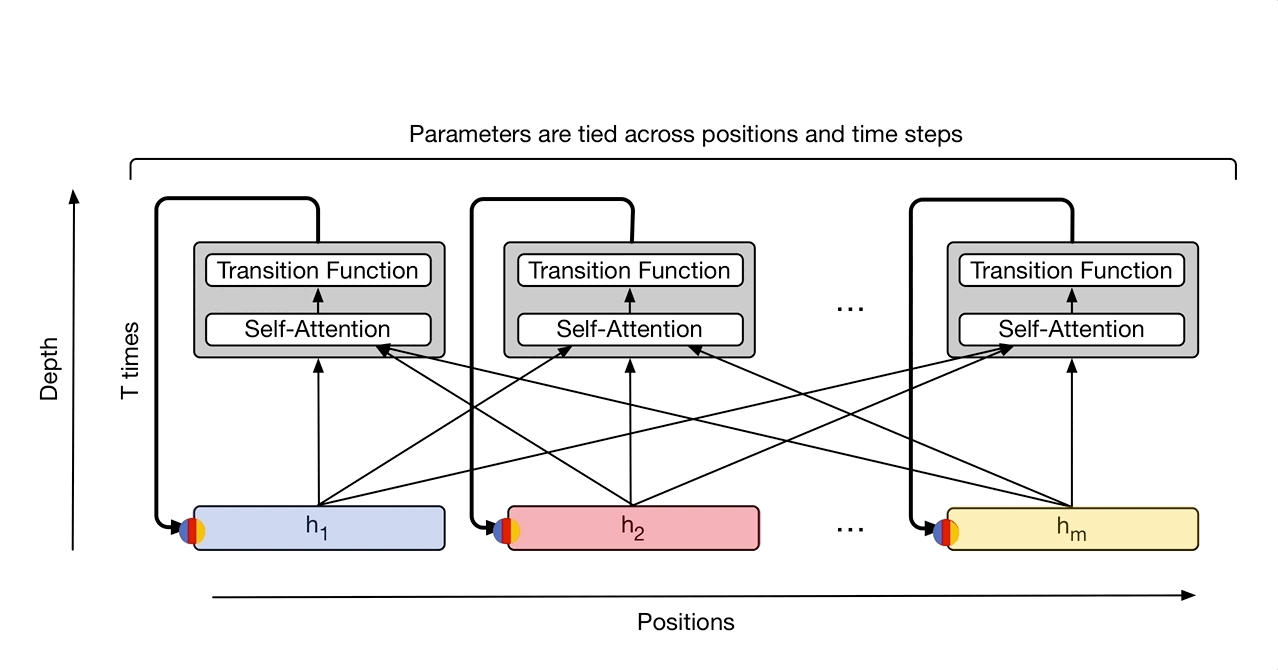
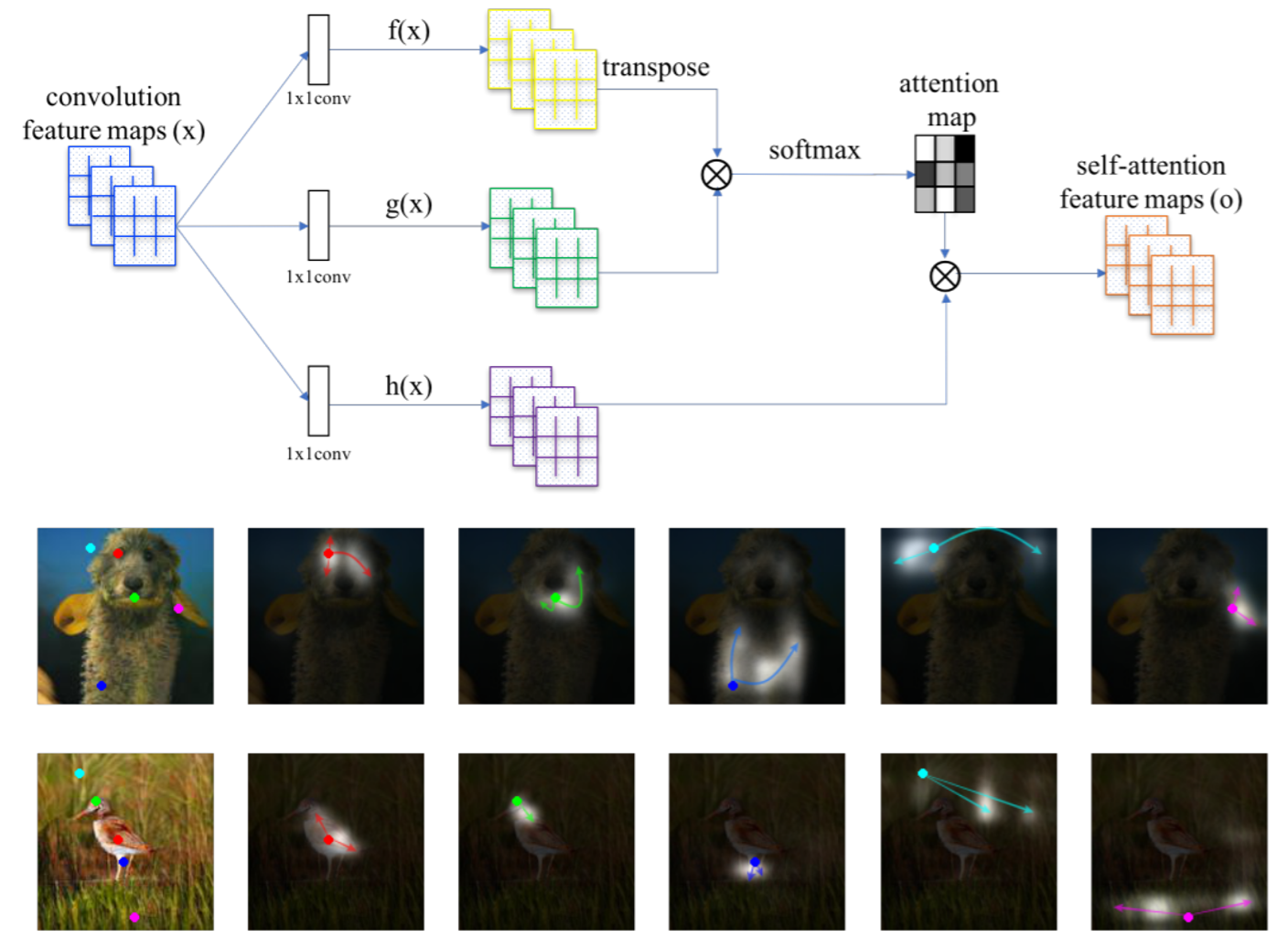
- Self-Attention GAN
也可以用在影像生成上