今天介绍的这篇文章,是哈佛大学在2023年2月份发出的一篇时间序列文章,提出了一种时间序列域自适应框架,能够有效解决跨域的feature和label偏移问题。

论文标题:Domain Adaptation for Time Series Under Feature and Label Shifts
下载地址:https://arxiv.org/pdf/2302.03133v1.pdf
1
Motivation
Domain Adaptation是机器学习领域广泛研究的一个课题,我在之前的很多文章中,都介绍过Domain Adaptation的相关工作(感兴趣的同学可以参考Domain Adaptation:缺少有监督数据场景下的迁移学习利器)。
在时间序列场景中,不同的数据集,数据分布存在很大的差异,主要体现在特征上的差异和label上的差异。例如在healthcare的数据集中,每个人的健康指标序列都有很大差异,我们希望能建立一个强泛化的模型,同时建模这些分布差异巨大的序列,而不希望每个人的序列单独建立一个模型。这个时候,Domain Adaptation的思路就非常合适:挖掘不同序列之间的共性信息,利用这些共性信息做下游的分类或预测任务。
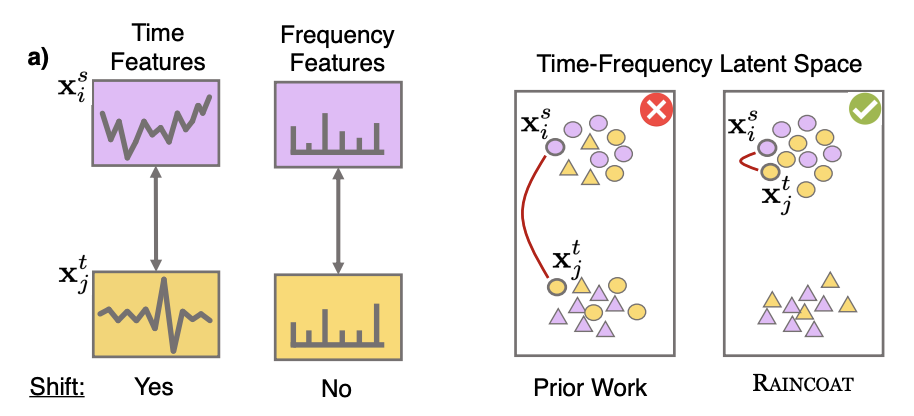
本文利用Domain Adaptation建立时间序列模型,核心是同时考虑时域特征和频域特征,最大限度寻找不同domain序列的共性。之前的工作集中在时间特征的维度提取不同domain的共性,而忽略了频域维度特征的共性,而频域有时会帮助我们挖掘到两个domain的共性信息。例如下图中,两个序列虽然在时域上分布差异很大,但是在频域上的分布是近似的。同时,Domain Adaptation的效果随着两个domain共性信息的增加和提升。因此,本文核心是同时考虑频域和时域的特征,挖掘不同domain之间的共性信息。
2
问题定义
本文解决的时间序列问题是,给定Source Domain的多元时间序列以及每个序列的label、Target Domain的多元时间序列但是label未知,两个domain的label集合可能不同。目标是在source domain上训练一个分类模型,能够达成以下2个目的:
分类:对于target domain中label和source domain的label集合中的,能够准确预测出来;
识别:对于target domain中label不在source domain的label集合中的,能识别出来。
3
整体结构
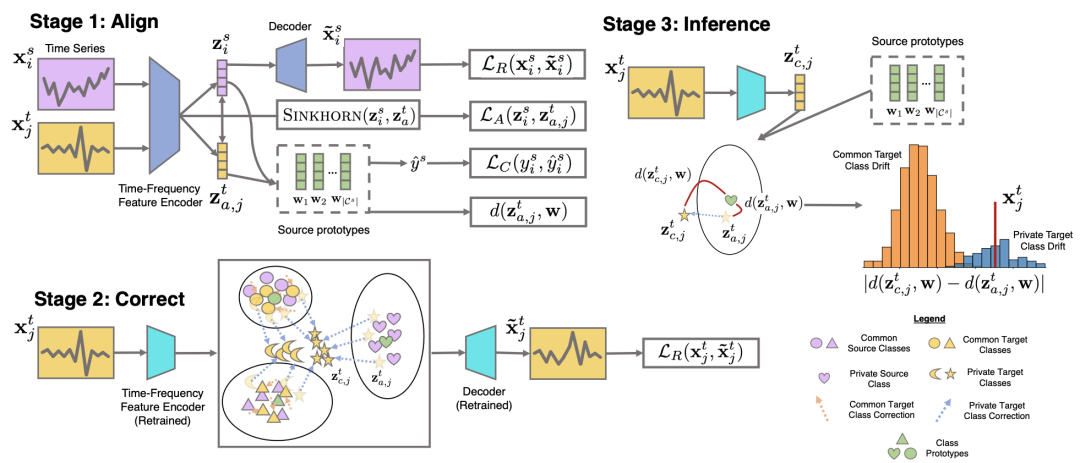
本文提出的模型,核心包含3个模块:时域&频域编码器、分类器、辅助解码器。其中,时域&频域编码器用来提取序列中的时域和频域信息;分类器用来对时间序列分类,实现主任务;辅助解码器用来将生成的表示还原成序列,引导模型生成更富有语义含义的表示。
在上述3个模块基础上,文中提出了Align、Correct、Inference三个核心阶段。在Align阶段,利用Sinkhorn算法对齐两个domain的分布;在Correct阶段,利用Encoder-Decoder的结构对序列进行还原,优化Encoder生成的表示。在Inference阶段,设计一种方法进行分类和识别两个任务。
4
实现细节
Align阶段首先使用Encoder对source和target两个domain的序列编码成向量,然后利用sinkhorn算法对两个域的表示进行对齐。Encoder部分有一个时域编码器和一个频域编码器,两个编码器分别生成两个向量,拼接到一起,作为一个序列的时域&频域表示。其中,时域编码器可以使用任何已有的方法,频域编码器文中采用了离散傅里叶变化+卷积的方式。
接下来,文中利用sinkhorn算法,对两个domain的表示进行对齐。对齐两个分布的方式很多,例如KL散度,以及DA中常用的MMD等。Sinkhorn算法其实是求解OT的一种可导算法,经常被用于对齐,例如NLP中文本匹配的可解释性,就经常使用sinkhorn求解(我在知识星球中的基于OT的NLP可解释性文章中进行过介绍)。文中论证了sinkhorn计算距离由于其他方法。最终,将sinkhorn计算的对齐距离加入到损失函数中,约束Encoder对两个ddomain生成的表示更加接近。
Correct阶段的主要目标是在训练过程中引入一个Decoder做Reconstruction的任务,以此让Encoder对target domain的时间序列生成的表示包含更多的语义信息。这里面一个重要作用是将target domain中不在source domain的label集合中的样本找到。因为最开始使用共享Encoder生成的表示,如果target domain中的某个序列label在source domain的label集合中,它在经过Reconstruction任务修正后的表示不会偏离太远(相同label的样本会聚成簇);而那些不在source domain label集合中的序列,会出现大范围的偏移,利用这个信息,可以实现在Inference阶段对样本类别的判断。
Inference阶段中,核心是利用correction前后的表示识别那些不在source domain的label集合中的序列。文中给每个label生成一个prototype向量,判断当前样本到各个prototype的距离。对于一个序列,看它在correction前后到prototype距离的变化,距离变化大的,就认为是不在source domain label集合中的样本。
模型整体的算法流程如下:

5
实验效果
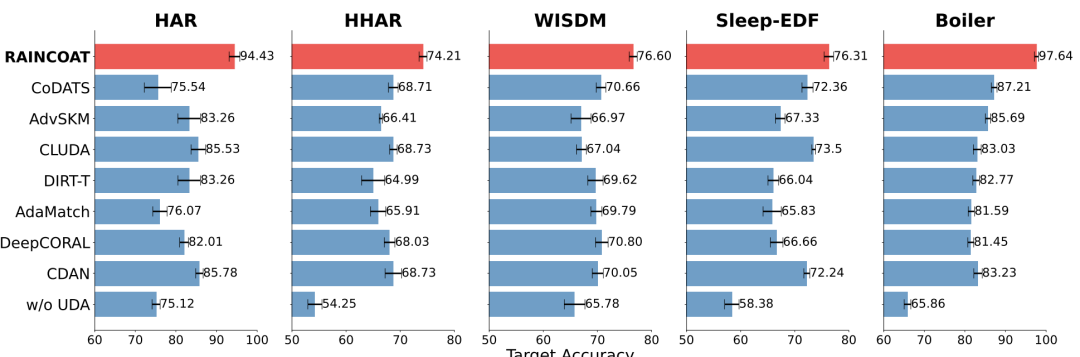
文中的主体实验效果如下,在多个数据集上对比了本文和其他8个Domain Adaptation方法的效果,均取得了非常显著的效果提升。
6
总结
Domain Adaptation在时间序列领域的应用是一个被广泛研究的问题,对于存在多个有数据偏移的小样本数据集,利用好Domain Adaptation可以显著提升在时间序列预测、分类等任务上的效果。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书