结论
Unicode 是 字符集
UTF-8 是 编码规则
字符集:为每一个字符分配唯一的ID(如 SCII 码)
编码规则:将 码位转换为字节序列的规则
背景

老规矩,我们用图文并茂的方式来讲解:
ASCII 这个字符集 由于仅能表示 英文字符,为了能够涵盖更过国家的字符,因此联合推出了 Unicode 这个字符集。
这里明确了 Unicode 是一个字符集的概念,那么继续解释:
既然有了全球统一的字符集,那当然就要有对应的编码规则,最早的编码规则为 UTF-32:
UTF-32 的规则虽然简单,但是缺陷也很明显,假设使用 UTF-32 和 ASCII 分别对一个只有西文字母的文档编码,前者需要花费的空间是后者的四倍(ASCII 每个字符只需要一个字节存储)。
在存储和网络传输中,通常使用更为节省空间的变长编码方式 UTF-8,UTF-8 代表 8 位一组表示 Unicode 字符的格式,使用 1 - 4 个字节来表示字符。这里需要注意的是 UTF-8 不像是 UTF-32那样 一成不变,如果是英文字符,则用一个字节表示,如果是中文字符,则用三个字节表示。
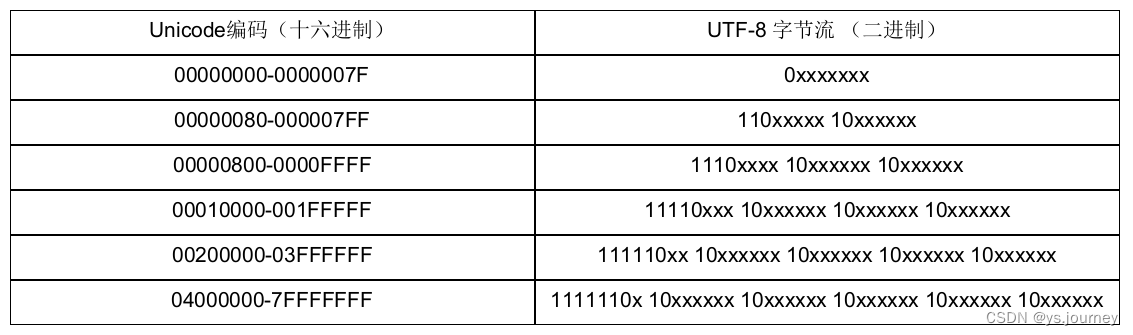
规则
单个字节的字符,字节的第一位为0,(如英文字符,在UTF-8中只占用一个字符)
n个字节的字符(n>1),第一个字节的前 n 位设为1,第 n+1 位设为 0 ,后面字节的前两位都设为 10,其余字节填充该Unicode码
UTF-8为了节省资源,采用变长编码,编码长度从1个字节到6个字节不等,一共有如下情况: