排序在生活中很多,比如网上买东西时候要根据条件进行排序,在编程学习中也是必须学习的,排序的方法有很多,但是效率各有各的差别。
一、插入排序
// 插入排序
void InsertSort(int* a, int n)
{
for (int i = 0; i < n;i++) {
int end = i;
int temp = a[end+1];
while (end >= 0)
{
if (temp < a[end]) {
a[end+1] = a[end];
end--;
}
else {
break;
}
a[end+1] = temp;
}
}
}思路:
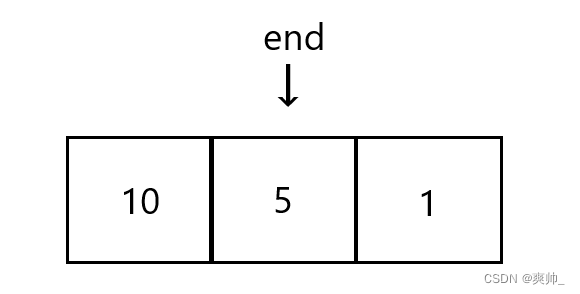
end比end+1大,把 end 对应的数据往后覆盖,end位置往后移动。
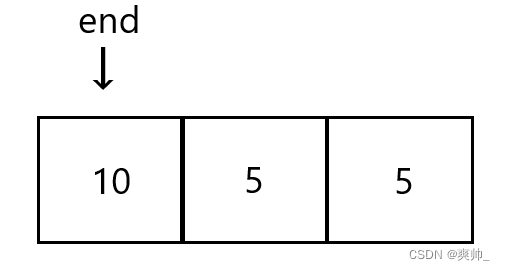
然后继续往前比较

到头了把end+1插入的值插入到头部去。
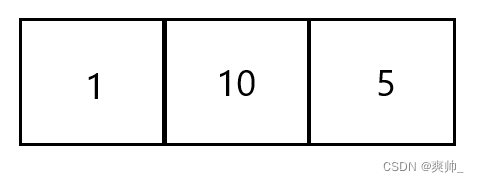
这样一次排序就完成了,多次插入进去就会发现,数组变为了升序的数组。
PS:插入排序的时间复杂度为O(N^2)。但是如果数组有序或者比较接近有序则效率会快很多。
二、希尔排序
希尔排序(Shell's Sort)是插入排序的一种,又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因 D.L.Shell 于 1959 年提出而得名。
思路:
其主要思路是,如果插入排序在接近有序的情况下,效率大大提高,那么可以不可以人为的制造数组有序的情况。
这里定义了一个 gap ,这里gap定义为 3,把数组分为了三组,每个相距gap个距离为一组,对这三个组进行预排序。

int gap = 3;
for (int j = 0; j < gap; j++) {
for (int i = j; i < n - gap; i += gap) {
int end = i;
int temp = a[end+gap];
while (end >= 0)
{
if (temp < a[end]) {
a[end+gap] = a[end];
end -= gap;
}
else {
break;
}
a[end + gap] = temp;
}
}
}会发现每个组的排序都是插入排序,这里代码还可以优化,这里是一个组一个组的排序,导致有三层循环,其实只用使用两层循环。
int gap = 3;
for (int i = 0; i < n - gap; i++) {
int end = i;
int temp = a[end+gap];
while (end >= 0)
{
if (temp < a[end]) {
a[end+gap] = a[end];
end -= gap;
}
else {
break;
}
a[end + gap] = temp;
}
} 这里其实就改了一个 i ++,这里的思路是,不用分组进行预排序,而是排完一组就进入下一组。结果也是一样的,而且非常巧妙。
到这里就完成了一次预排序,这里还要进行多次预排序才行,那么gap怎么选择呢?一般这里选择其最开始等于数组的大小,然后慢慢缩小,直到等于1。
- 排升序,gap越大,排大的数更快的到后面,小的数可以更快到前面,但是越不接近有序。
- 排升序,gap越小,越接近有序的。当gap==1,就是插入排序。
- gap=n(数组长度)
- gap=gap/3+1;(要预排序很多次)
- gap>1时是与排序,gap最后一个等于1是直接插入排序。
代码:
void ShellSort(int* a, int n)
{
int gap = n;
while(gap > 1){
gap = gap/3+1;
for (int i = 0; i < n - gap; i++){
int end = i;
int temp = a[end+gap];
while (end >= 0)
{
if (temp < a[end]) {
a[end+gap] = a[end];
end -= gap;
}
else {
break;
}
a[end + gap] = temp;
}
}
}
}测试:

时间复杂度:
O(N^1.3)
计算gap时+1可以忽略, gap/3/3/3/3/3/...=N,那么预排为 log3N。
for循环里面是2/3*N。
主要是while循环里面该如何计算,其数学计算比较复杂,主要讲解其思路。
1.gap很大的时候,其大概是2N次。
gap很大的时候,跳的很快。
2.gap很小的时候,其大概也是2N次。
gap很小的时候,前面已经预排序过,所以数组接近有序了,所以循环也走的很快。
就是N*log3N(注意这里是推算,不准确,记个O(N^1.3)就行)。
三、堆排序
// 堆排序 建小堆
void AdjustDwon(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child + 1] < a[child]) {
//注意child+1<size要在前面判断,不然越界
child++;
}
if (a[child] < a[parent]) {
swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else {
break;
}
}
}
//小堆建立的降序
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0;i--) { //注意这里是i>=0
AdjustDwon(a, n, i);
}
int size = n - 1;
while (size>0) {
swap(&a[0],&a[size]);
AdjustDwon(a,size,0);//注意这里使用的size
size--;
}
}前面有,不赘述。
堆的介绍:https://blog.csdn.net/weixin_45423515/article/details/124916001?spm=1001.2014.3001.5501
四、冒泡排序
// 冒泡排序
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n-1;i++) {
for (int j = 0; j < n-i-1;j++) {
if (a[j+1]<a[j]) {
swap(&a[j+1],&a[j]);
}
}
}
}非常容易理解的排序,也是最开始学的排序。其思路也非常简单,后面一个前面一个数大就交换。
时间复杂度:
O(N^2)
五、选择排序
// 选择排序
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin<end) {
int max = begin, min = begin;
for (int i = begin ; i <= end;i++) { //这里只有4个数的时候begin+1是错误的
if (a[i] < a[min])
min = i;
if (a[i] > a[max])
max = i;
}
swap(&a[begin], &a[min]);
if (begin == max) {
max = min;
}
swap(&a[end],&a[max]);
begin++;
end--;
}
}其思路也比较简单,遇到小的数就放前面,大的数放后面,非常消耗效率,而且不像插入排序,如果数组接近有序就会提上效率,不管数组有没有序其时间复杂度都是最坏的O(N^2)。
PS:这里要注意,如果begin是最大的数,这里交换后最大的数会换位子,所以这里要判断下。


时间复杂度:
O(N^2)
六、快速排序(递归法)
// 快速排序递归实现
void QuickSort(int* a, int begin, int end)
{
if (begin >= end) {
return;
}
int left = begin , right = end ;
int key = left;
while (left < right ) {
//注意找的是纯小于key的数,所以要用<=,>=
//为了防止一直找不到,要加上left<right防止越界
while (left < right && a[right] => a[key]) { //右边找小
right--;
}
while (left < right && a[left] <= a[key]) { //左边找大
left++;
}
swap(&a[left] , &a[right]); //找到后交换
}
swap(&a[key],&a[left]);
QuickSort(a,begin,left - 1);
QuickSort(a,left + 1,end);
}
思路:
让最左边的数作为一个key(最右边的也可以),然后让数组其余的数比较key,如果比key大放右边,比key小放左边。
两边相互找,找到后交换。找到最后(left和right相遇时)与key进行交换,这样key就到了最合适的位置上。
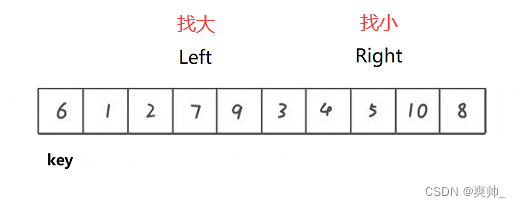


然后以分治的思想,让两边分别再排序。
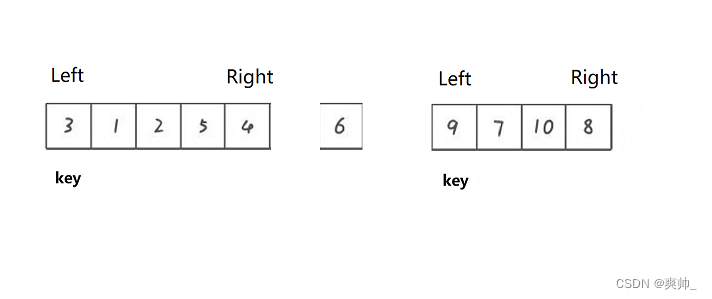
要注意开始从哪边开始查找:
这里要注意如果key选的左边,那么就要让右边开始走(选的右边,左边开始走),其原因是要保证相遇的位置的值,要比key值小。从右边走停下来的值固定是比key小的值,就可以跟key进行交换。
如果从左边开始走,假设遇到的都是小于key的值,到最后遇到right时的位置刚好比key大,再交换,会发现把大的值换到开头去了,这是错误的。



如果从右边开始走,假设遇到的都是比key大的值,right会找小于key的数一直找到跟left相遇,left此时还是key,自己跟自己交换,也说明了其他数都比key大,开头的位置就是最合适的位置。(为什么要从右边开始走的列子有很多,可以只记这一个较简单的列子)

测试:
