调优概述
Spark性能调优(1)
Spark性能调优(2)
调优主要方法
- 开发调优
- 数据本地化调优
- 数据倾斜调优
- shuffle调优
- 资源调优
- JVM调优
1. 开发调优
1.1 对多次使用的RDD进行持久化
Spark中对于一个RDD的执行多次算子的默认原理是这样的:每次你对一个RDD执行一个算子的操作的时候,都会从源头计算一遍(因为RDD是根据finalStage递归往前找到第一个算子开始执行),计算出来那个RDD来,然后对这个RDD执行你的算子操作,这种方式的性能是很差的。

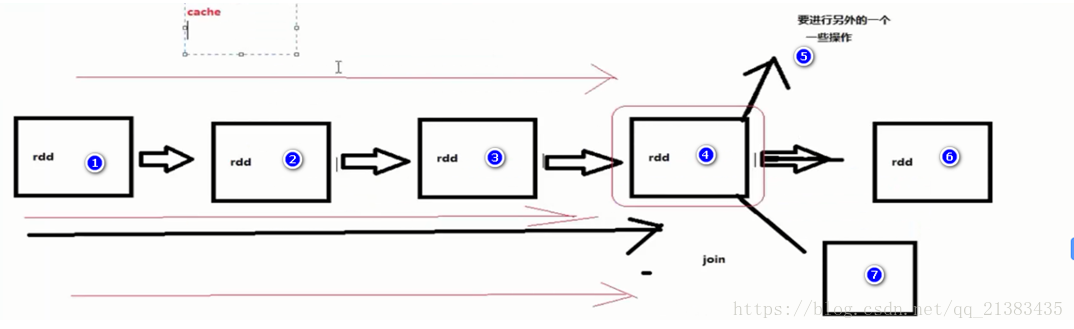
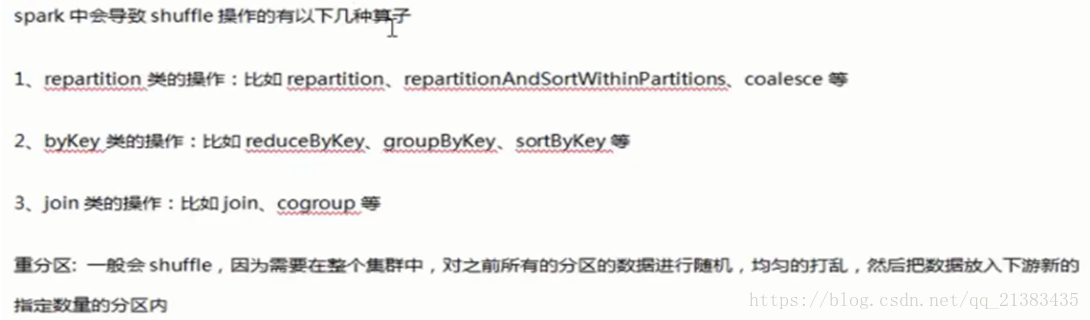
图示 567三个RDD,都要使用4RDD,如果4不缓存,那么计算567的时候,会运行3次123454.
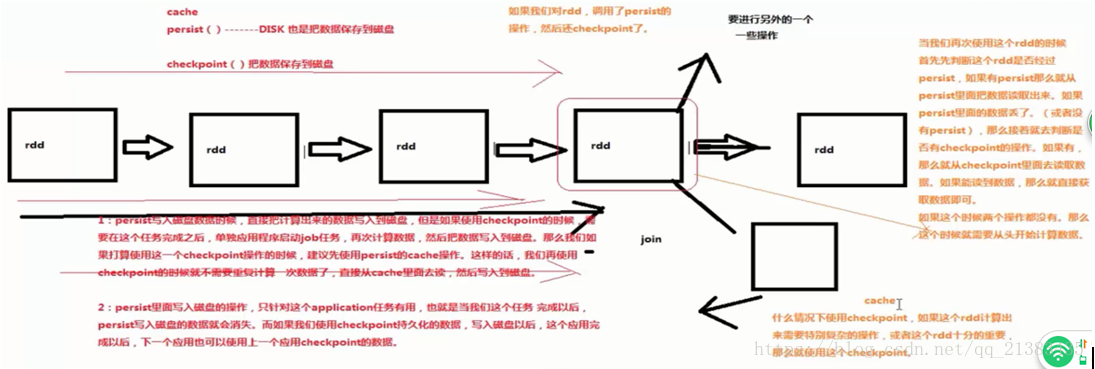
为什么将RDD,持久化放到这里呢?因为读取数据源和shuffle都是最重量级的操作。比如说读取Hbase需要Hbase去扫描表,读取HDFS,也需要文件读取操作,这些都是费时间的操作,所以能不多次读取就不多次读取。
1.2 避免创建重复的RDD


1.3 尽可能复用同一个RDD

扫描二维码关注公众号,回复:
1492598 查看本文章