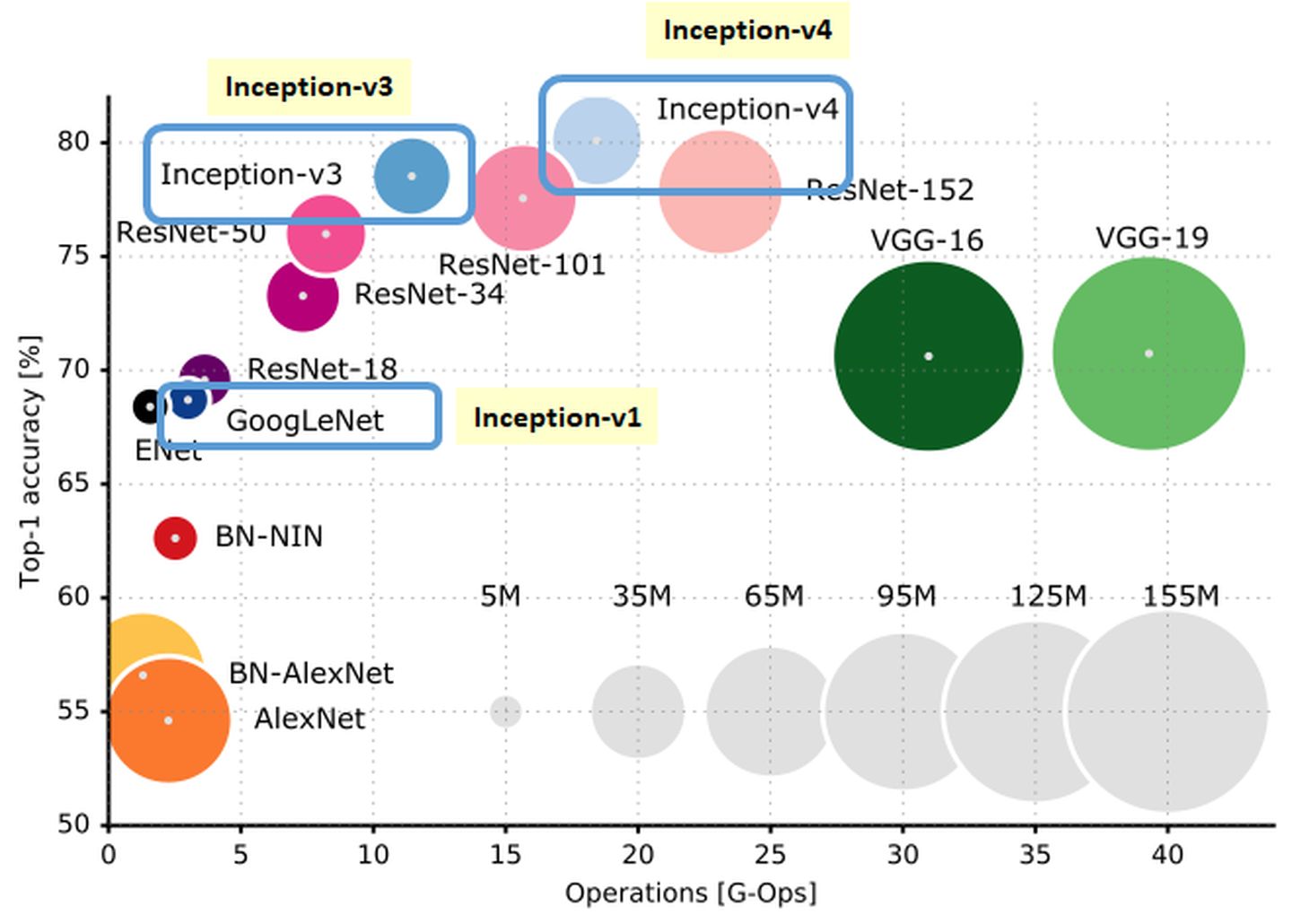
PyTorch-Networks: 包含了分类、检测以及姿态估计等网络的pytorch代码
caffe-model-zoo: AlexNet、VGGNet、GooLeNet、ResNet等网络含预训练权重
caffe-model: 不同网络的性能对比,仅含网络结构,不含权重

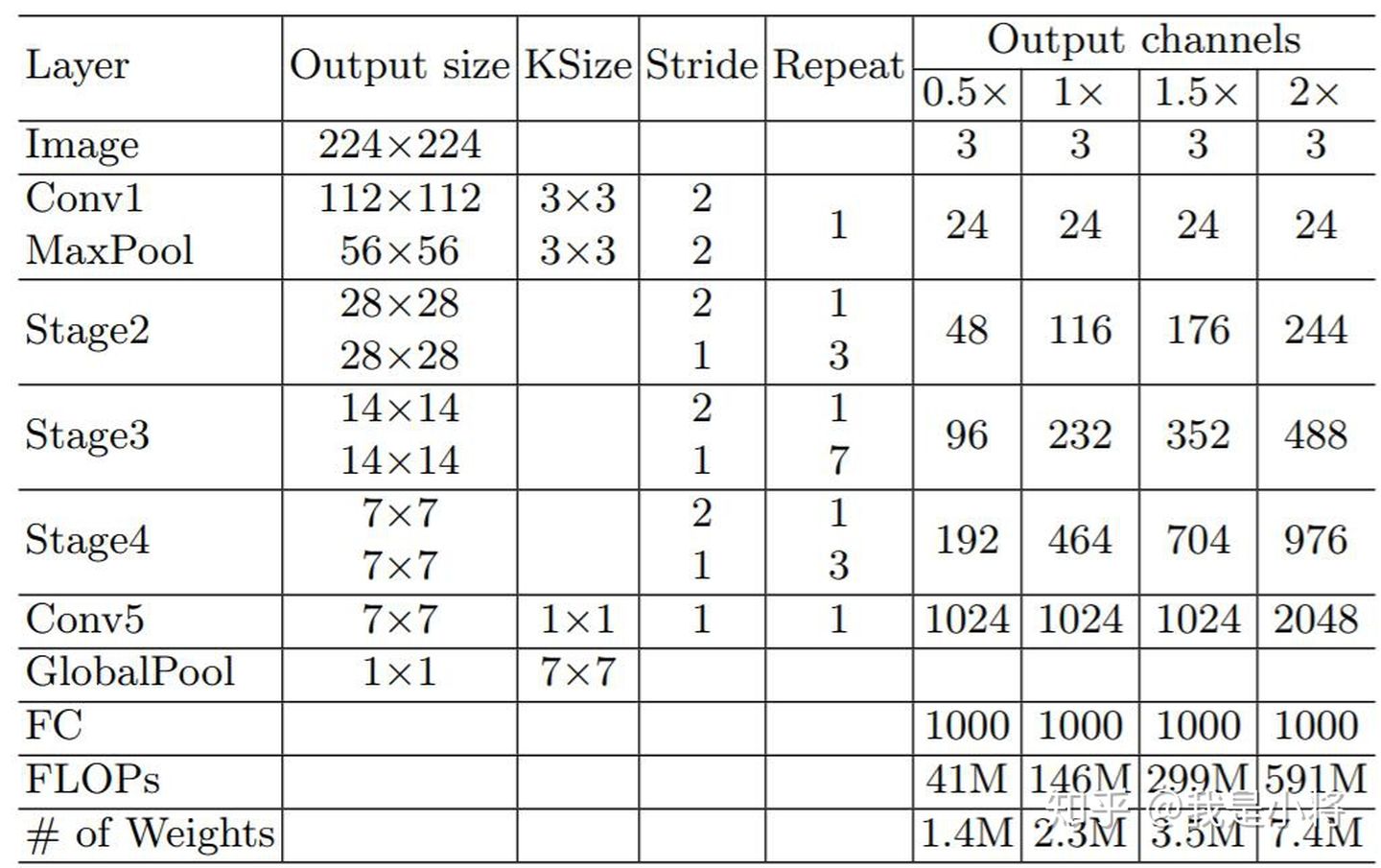
DWConv depthwise conv

如在上图中一张10x10像素、三通道彩色输入图片(shape为3x10x10), Depthwise Convolution首先经过第一次逐通道卷积运算(shape为3x3x3), 然后再进行逐点卷积(shape 为3x1x1x16), 那么总的参数量为27+48 =75, 相比于常规卷积(3x3x3x16) 减少了83%的参数量
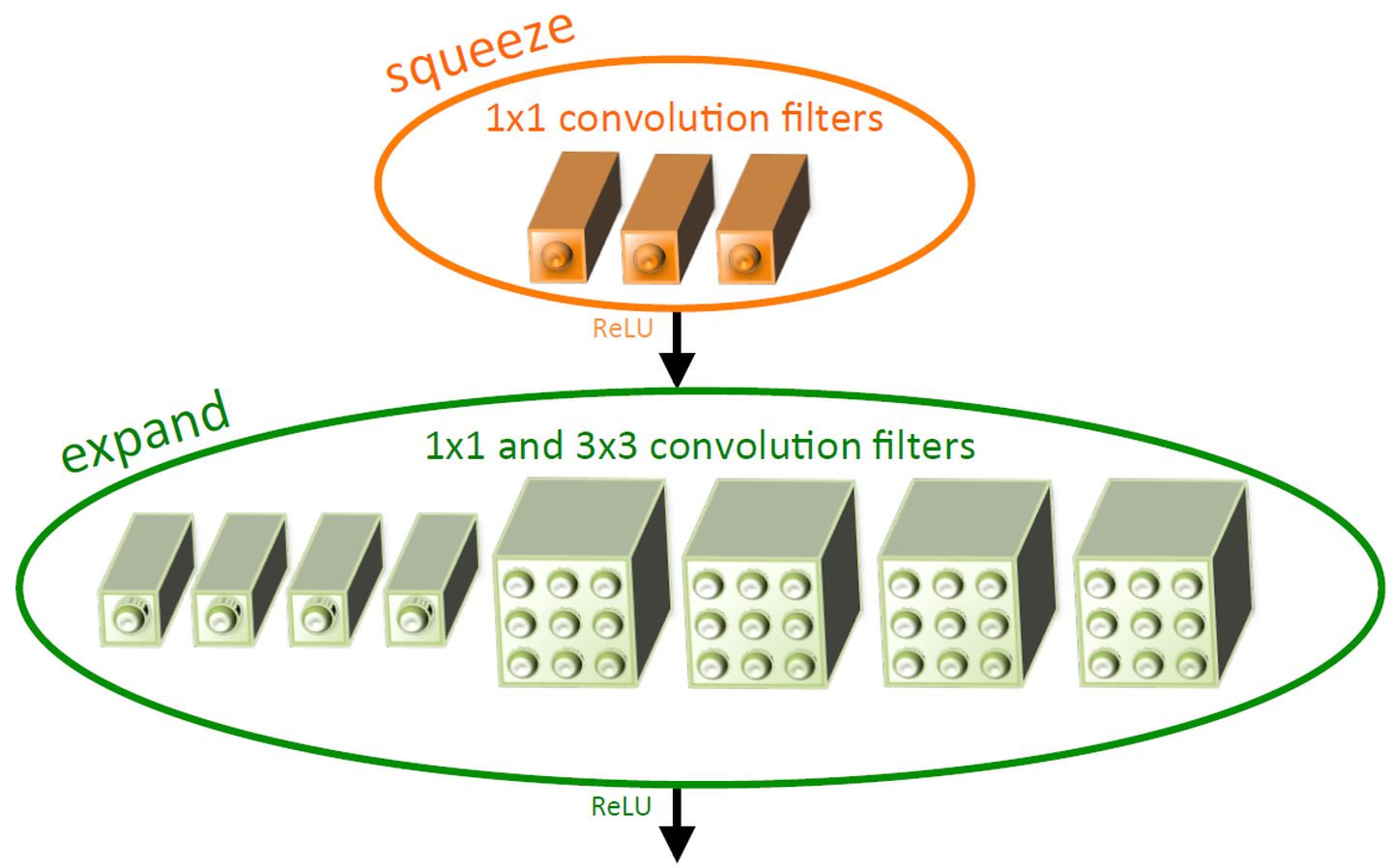
CNN模型之ShuffleNetInverted residual block
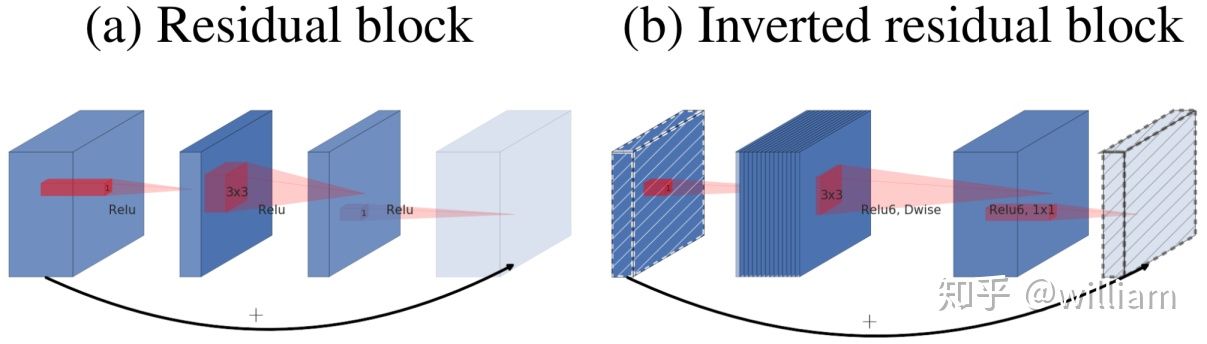
Inverted residual block来源于Mobilenet, 传统的残差模块, 先用1x1卷积将输入的feature map的维度降低, 然后进行3x3的卷积操作, 最后再用1x1的卷积将维度变大. 而倒置残差模块先用1x1卷积将输入的feature map维度变大, 然后用3x3 depthwise convolution方式做卷积运算, 最后使用1x1的卷积运算将其维度缩小. 注意, 在Mobilenet V2中, 1x1卷积运算后, 不再使用ReLU6激活函数, 而是使用线性激活函数, 以保留更多特征信息, 保证模型的表达能力
基本单元
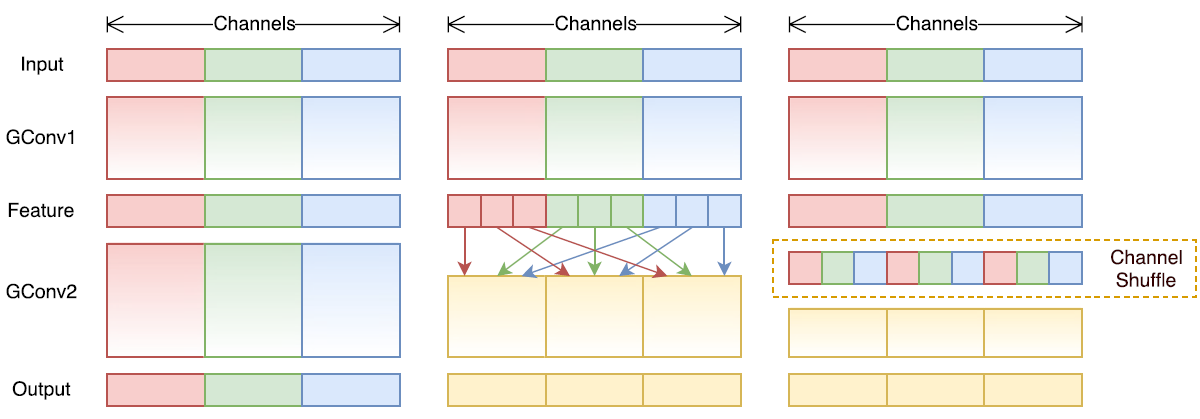
channel shuffle实现:假定将输入层分为g组,总通道数为n,首先你将通道那个维度拆分为 (g,n) 两个维度,然后将这两个维度转置变成 (n,g) ,最后重新reshape成一个维度。仅需要简单的维度操作和转置就可以实现均匀的shuffle
def shuffle_channels(x, groups):
"""shuffle channels of a 4-D Tensor"""
batch_size, channels, height, width = x.size()
assert channels % groups == 0
channels_per_group = channels // groups
# split into groups
x = x.view(batch_size, groups, channels_per_group,
height, width)
# transpose 1, 2 axis
x = x.transpose(1, 2).contiguous()
# reshape into orignal
x = x.view(batch_size, channels, height, width)
return x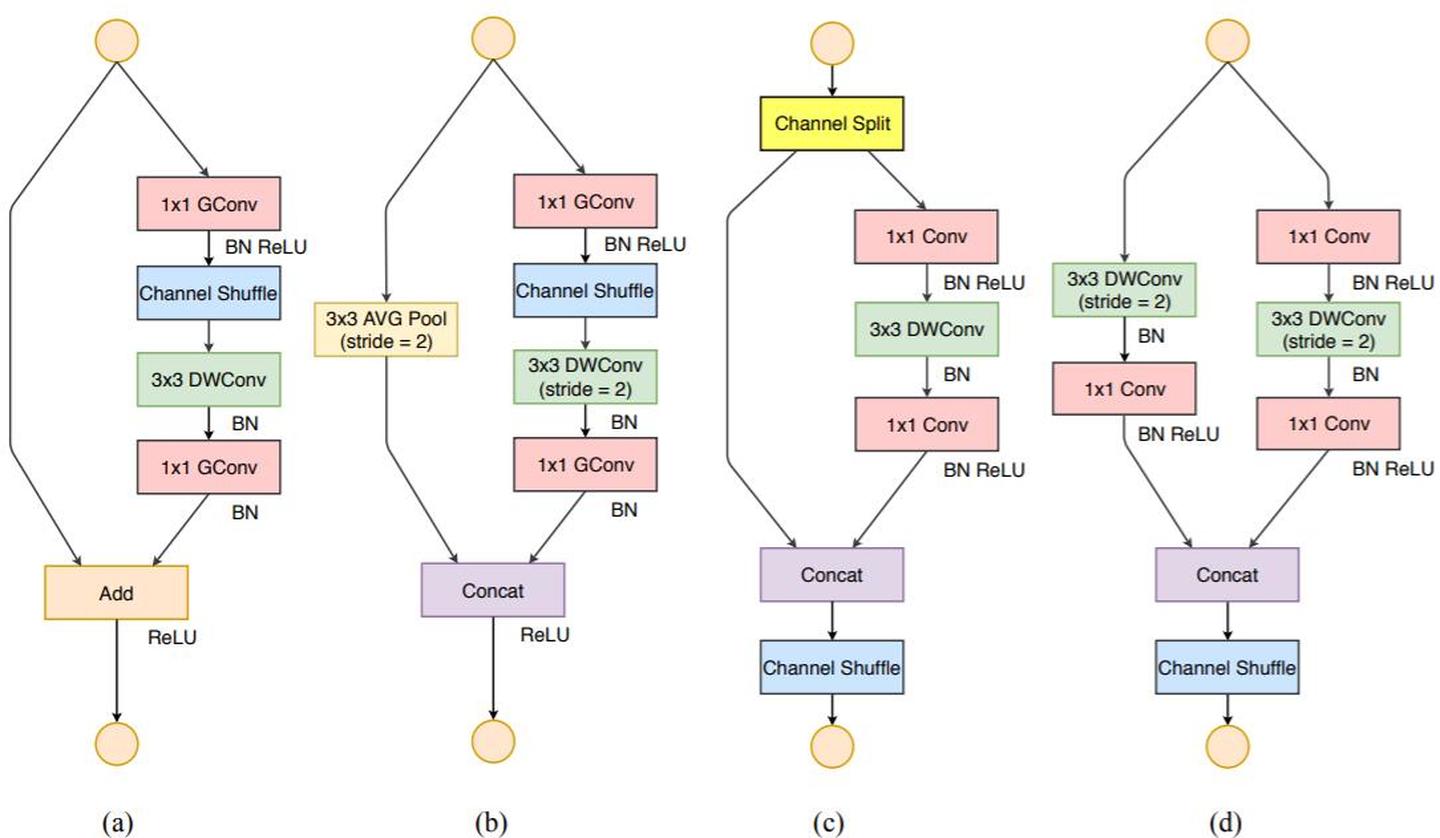
- 同等通道大小最小化内存访问量
- 过量使用组卷积会增加MAC
- 网络碎片化会降低并行度
- 不能忽略元素级操作
指导准则总结如下
- 1x1卷积进行平衡输入和输出的通道大小;
- 组卷积要谨慎使用,注意分组数;
- 避免网络的碎片化;
- 减少元素级运算。

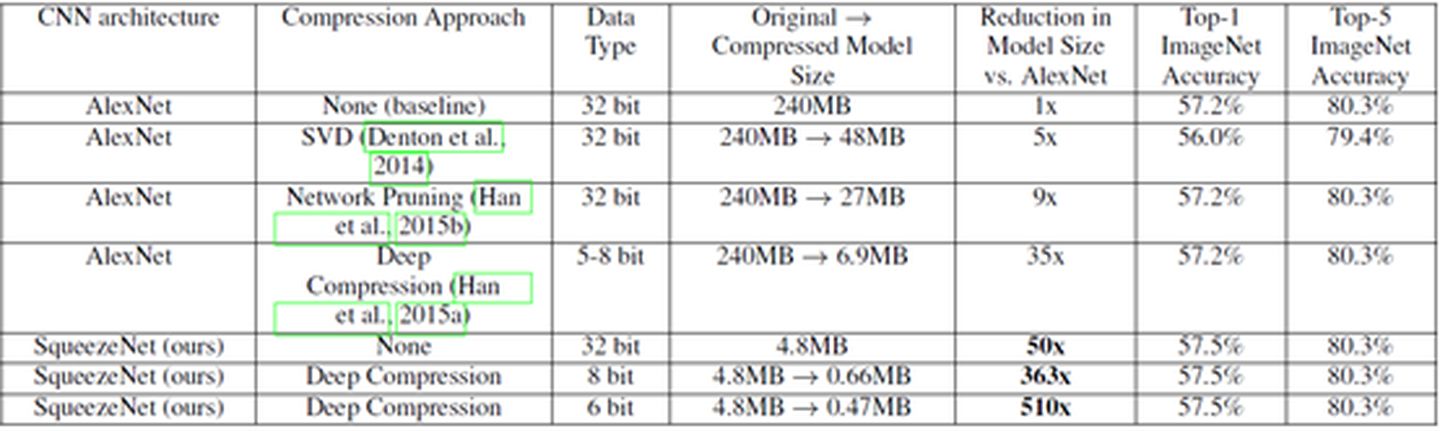
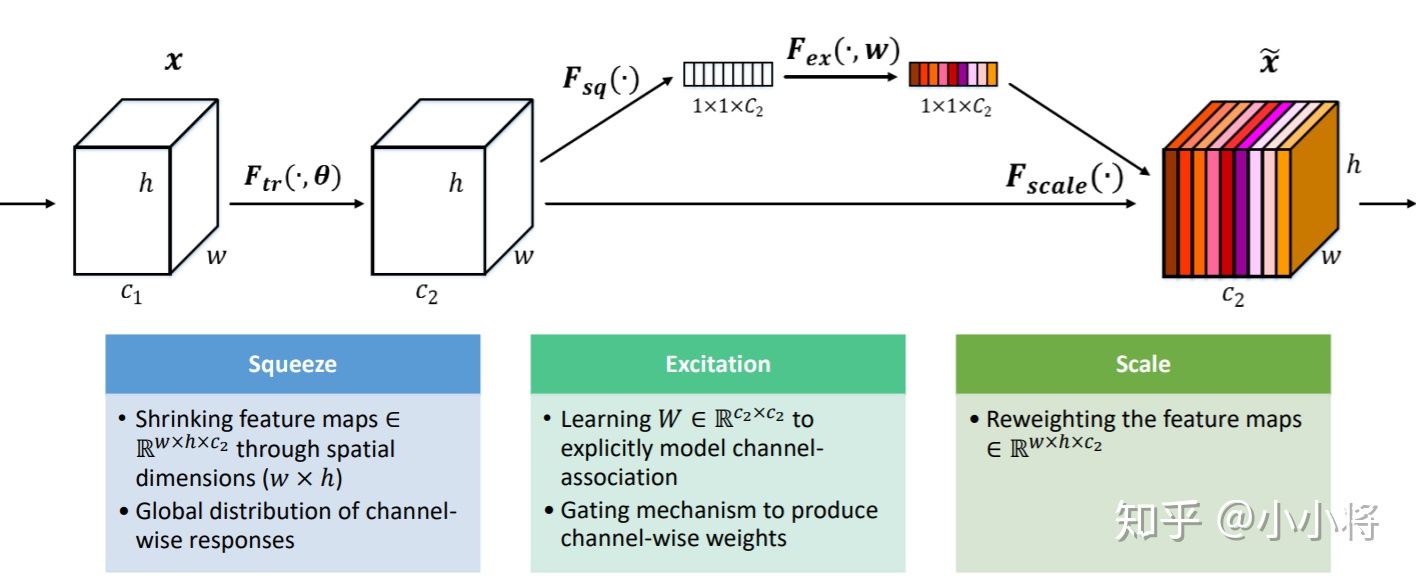
SENet网络的创新点在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度. SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)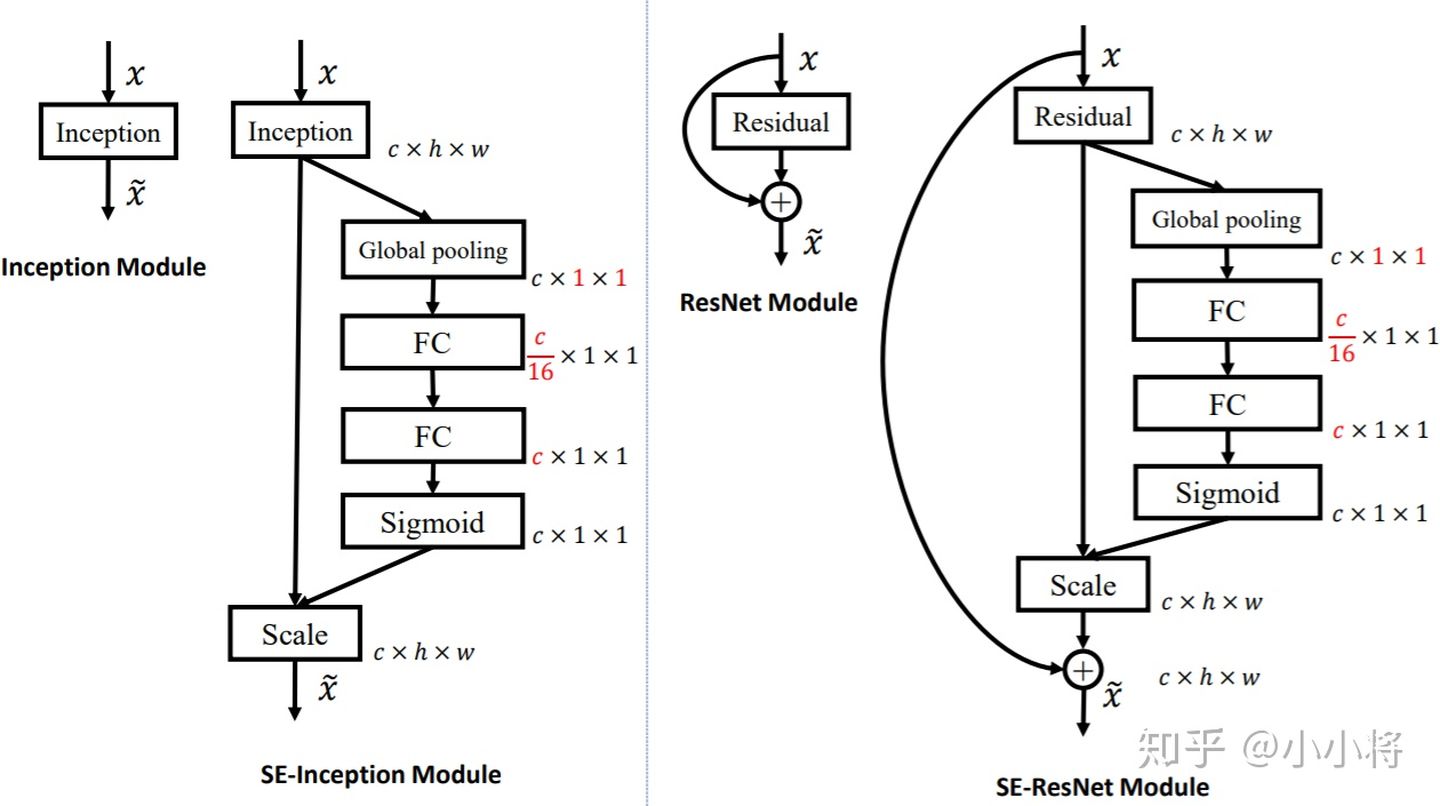
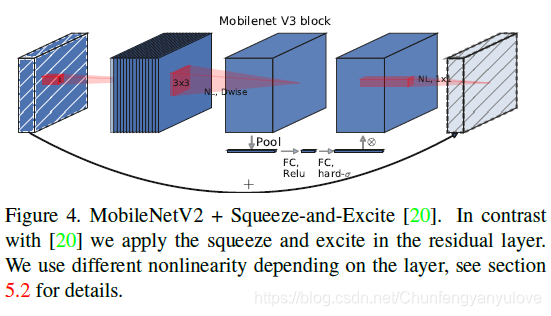
在bottlenet结构中加入了SE结构,并且放在了depthwise filter之后. 因为SE结构会消耗一定的时间,所以作者在含有SE的结构中,将expansion layer的channel变为原来的1/4,这样作者发现,即提高了精度,同时还没有增加时间消耗。并且SE结构放在了depthwise之后。
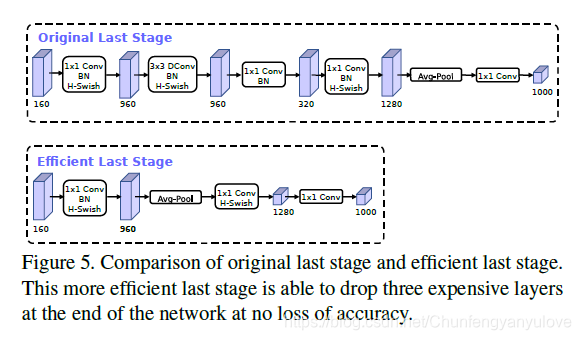
在mobilenetv2中,在avg pooling之前,存在一个1x1的卷积层,目的是提高特征图的维度,更有利于结构的预测,但是这其实带来了一定的计算量了,所以这里作者修改了,将其放在avg pooling的后面,首先利用avg pooling将特征图大小由7x7降到了1x1,降到1x1后,然后再利用1x1提高维度,这样就减少了7x7=49倍的计算量。并且为了进一步的降低计算量,作者直接去掉了前面纺锤型卷积的3x3以及1x1卷积,进一步减少了计算量,就变成了如下图第二行所示的结构,作者将其中的3x3以及1x1去掉后,精度并没有得到损失。这里降低了大约15ms的速度

在VGG网络的Block块中加入了Identity和残差分支,相当于把ResNet网络中的精华应用 到VGG网络中.模型推理阶段,通过Op融合策略将所有的网络层都转换为Conv3*3,便于模型的部署与加速。 网络训练和网络推理阶段使用不同的网络架构,训练阶段更关注精度,推理阶段更关注速度, 是一种提升模型部署速度的方案

首先通过将残差块中的卷积层和BN层进行融合, 将融合后的卷积层转换为Conv3*3,合并残差分支中的Conv3*3

深入浅出Yolo系列之Yolov3&Yolov4核心基础知识完整讲解
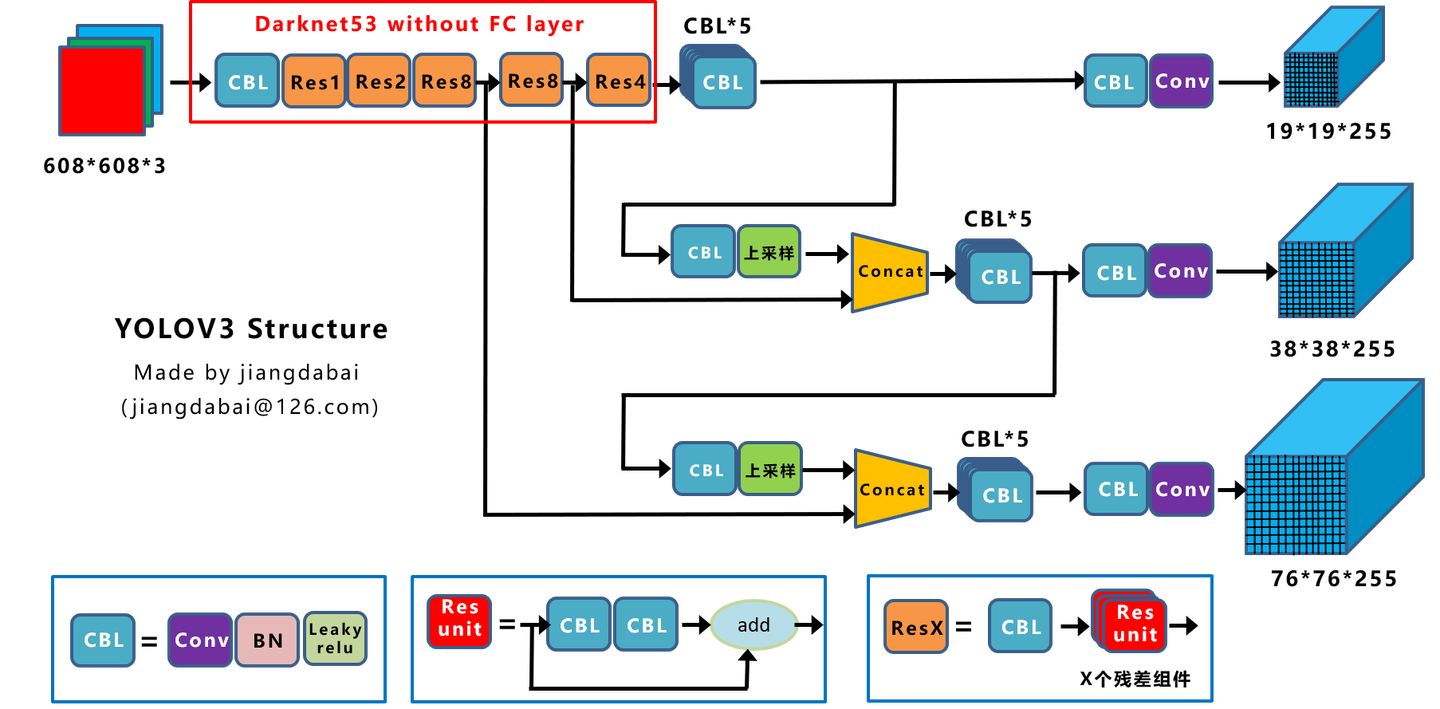
上图三个蓝色方框内表示Yolov3的三个基本组件:
- CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
- ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
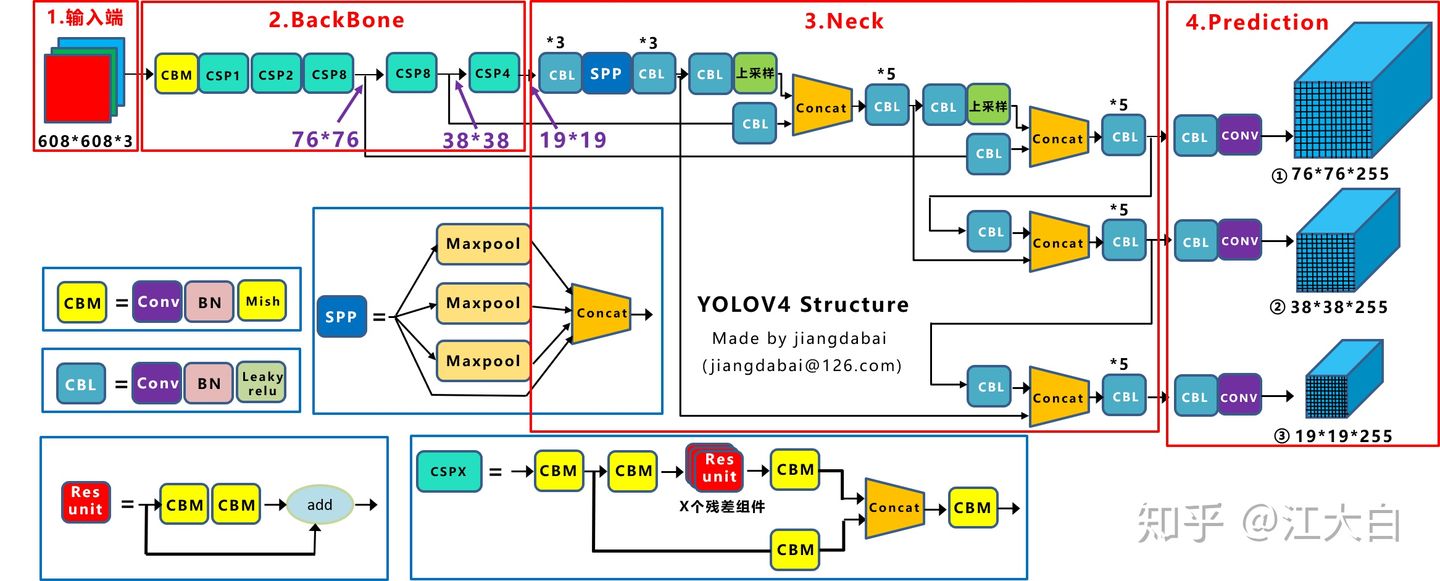
- 输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
- BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
- Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
- Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
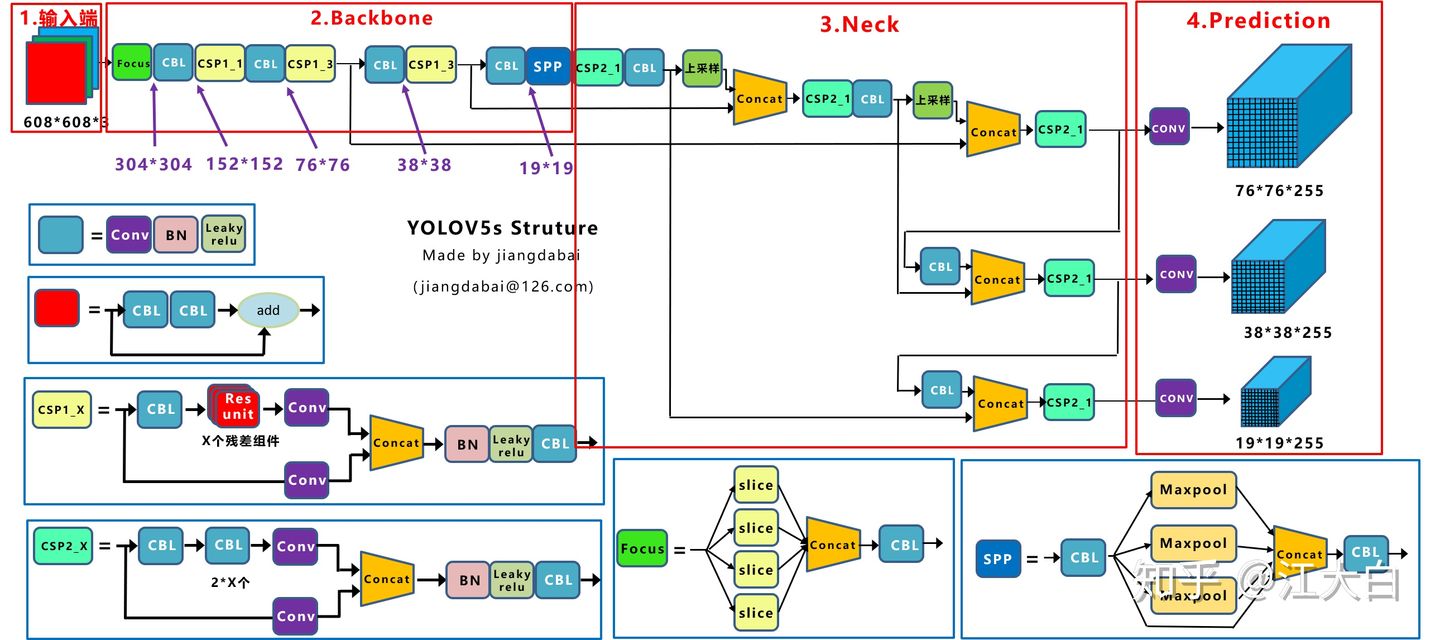
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
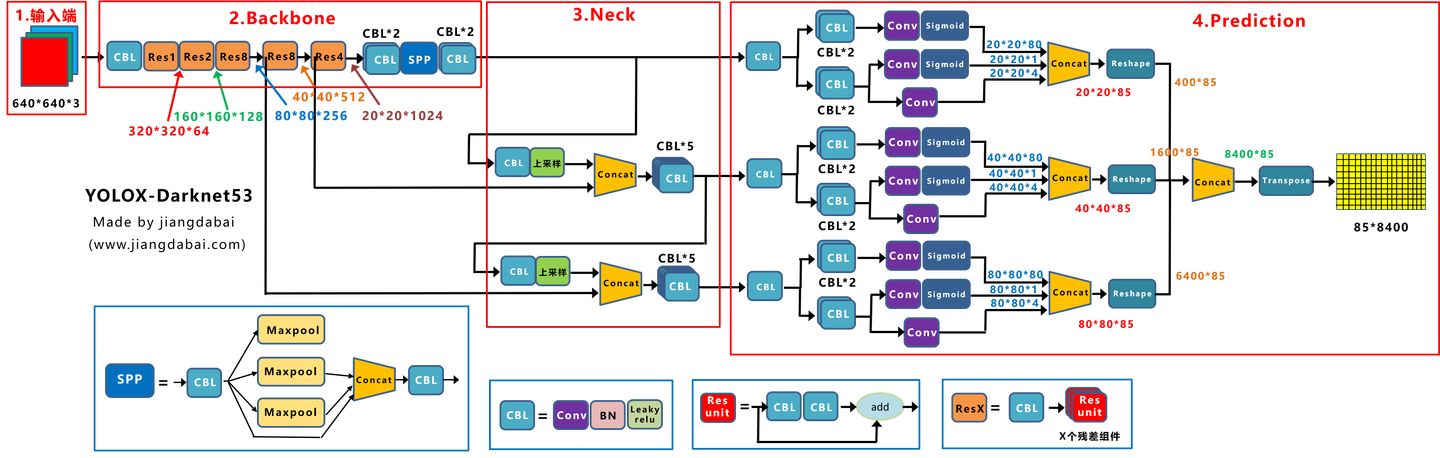
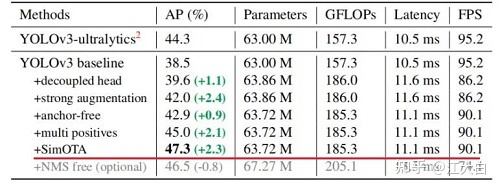
1. 输入端:Strong augmentation数据增强
2. BackBone主干网络:主干网络没有什么变化,还是Darknet53。
3. Neck:没有什么变化,Yolov3 baseline的Neck层还是FPN结构。
4. Prediction:Decoupled Head、End-to-End YOLO、Anchor-free、Multi positives

backbone分成4个stage,每个stage分成蓝色框和橙色框两部分。其中蓝色框部分是每个stage的基本结构,由多个branch组成,HRNet中stage1蓝色框使用的是BottleNeck,stage2&3&4蓝色框使用的是BasicBlock。其中橙色框部分是每个stage的过渡结构,HRNet中stage1橙色框是一个TransitionLayer,stage2&3橙色框是一个FuseLayer和一个TransitionLayer的叠加,stage4橙色框是一个FuseLayer