文献阅读(50)—— Transformer 用于肺癌诊断预测
文章目录
Time-distance vision transformers in lung cancer diagnosis from longitudinal computed tomography

这一篇也是一篇刚出来的文章,觉得还是有必要精读的。后面几天会更新一下最近看的Transformer的文章
先验知识/知识拓展
- 核心任务:使用纵向数据对肺癌CT数据分类
文章结构
- 摘要
- introduction
- related work
- method★
- experiments and results
- conclusions
背景
提出问题:
纵向的医学数据在采集的过程中多数不是等间隔的,可能存在相隔时间很久,不同个体相同时间内的采样次数也是不同的。虽然自注意力机制是一种将时间序列和图像有效结合的学习方法,但是在解释稀疏,不规则采样空间特征之间的时间距离方面尚未被探索。针对这个问题,作者提出两个module来解决此问题:
文章方法
1. 文章核心网络结构
作者在Transformer的基础上增加了两个小模块提升性能的同时增加模型的可解释性。
- 利用连续时间的embedding向量(Time Encoding ViT)
- 使用一个是temporal emphasis model权衡自注意力机制(Time Aware ViT)
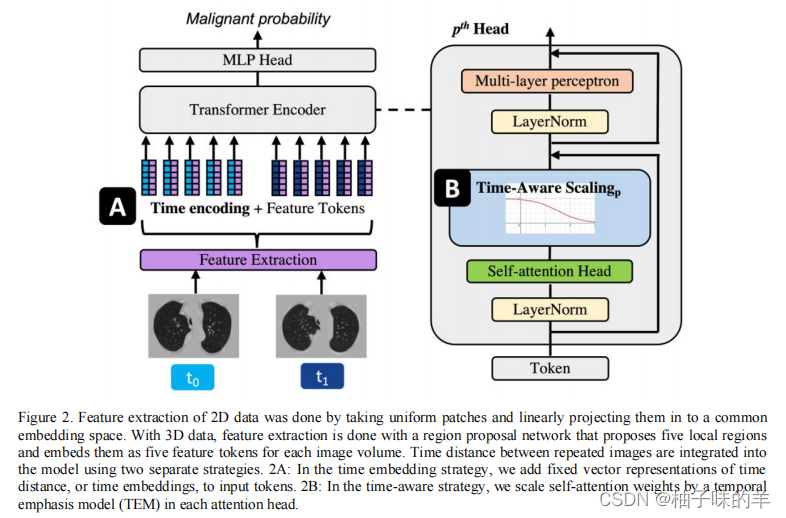
2. Time Encoding ViT (TeViT)
将每张图片的时间encoding为一个和图像特征等长的向量共同作为输入特征。其中rt是最后一个时间和现在时间点差值(两者的时间间隔)
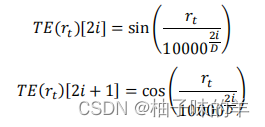
3. Time Aware ViT(TaViT)
TaViT是为了学习一个temporal emphasis model(TEM)来衡量每个头部的自注意力机制的权重。其中的R就是TaViT的核心,是时间i和时间j之间的时间间隔,把他们转换为非负值(越接近现在时间点的CT影响越大)
转化过程
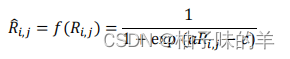
普通的注意力机制
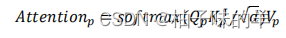
改进后的
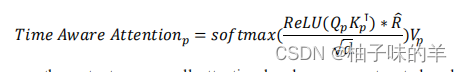
文章结果
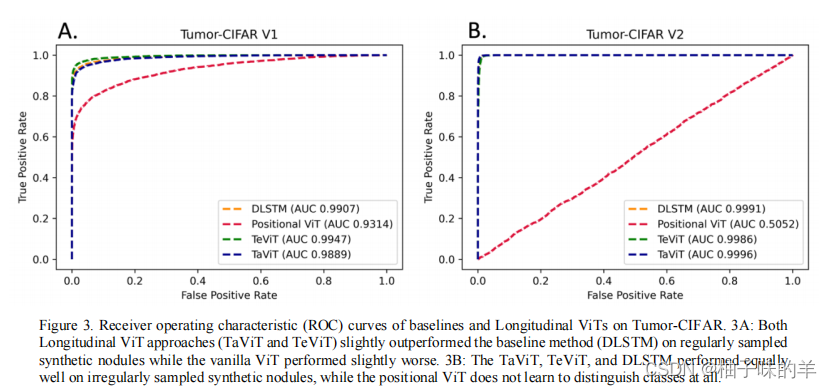
1. 在Tumor-CIFAR 上验证
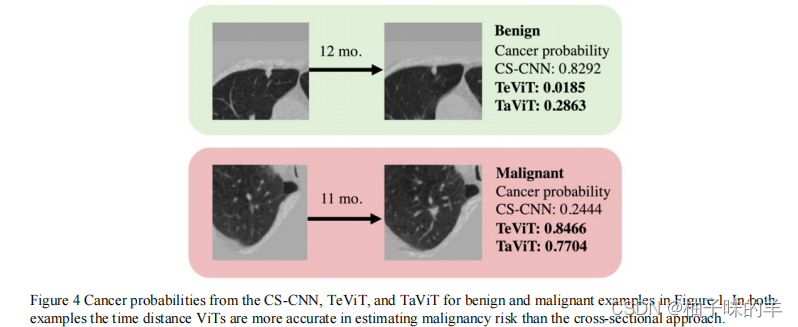
2. 在NLST上验证
将CS-CNN,TeViT,和TaViT对比
总结
1. 文章优点
- 提出了两个精妙的trick,将纵向数据中的时间作为其中的考虑因素,将时间encoding和feature token一起作为transformer的输入,就可以考虑每一张照片的时间
- 之后在attention的部分,有效的结合之前的ct信息,根据现在时间和时间的时间差值对attention机制中的queue,key 和value进行权重加持,因为时间间隔越久越不重要。
- 很巧妙,最近看到很多文章在考虑时间的时候都是加一个scale
2. 文章不足
可借鉴点/学习点?
文章写的还是很容易读懂的,这种思想值得借鉴。