这本项目继承于https://github.com/logpai/Drain3
在此项目的基础上进行了改进,目前代码在PR阶段,感兴趣的可以从PR上拉取:
前言:
本项目继承于https://github.com/logpai/Drain3
在此项目的基础上进行了改进,目前代码在PR阶段,感兴趣的可以从PR上拉取:
更多信息可以进入该开源项目了解。
下面直接就现在代码成果层面介绍该算法的原理和使用方式。
一、算法介绍
日志记录了系统运行时的信息,已被服务提供者和用户广泛应用于Web服务管理中。
一个典型的基于日志分析的 Web 服务管理过程是首先解析原始日志消息,因为它们的格式是非结构化的;然后应用数据挖掘模型提取关键系统行为信息,辅助Web服务管理。
现有的日志解析方法大多侧重于日志的离线、批处理。然而,随着日志量的迅速增加,离线日志解析方法的模型训练(即在日志收集后使用所有现有日志)变得非常耗时。
针对这个问题,我们提出了一种在线日志解析方法,及时地解析日志。
日志分析的用处:
1、数据分析人员大多数数据挖掘模型都需要结构化输入(例如,事件列表或矩阵)。但是,原始日志消息通常是非结构化的,因为允许开发人员在源代码中编写自由文本日志消息。因此,日志分析的第一步是日志解析,将非结构化日志消息转换为结构化事件。
2、传统上,日志解析严重依赖于正则表达式 ,这些正则表达式由开发人员手动设计和维护。但是,这种手动方式不适用于现代服务生成的日志,原因有以下三个。
(1)首先,日志量在快速增长,这使得手动方法望而却步。
(2)其次,随着开源平台(例如 Github)和 Web 服务变得流行,一个系统通常由全球数百名开发人员编写的组件组成 [3]。因此,负责正则表达式的人可能不知道最初的日志记录目的,这使得手动管理更加困难。
(3)第三,现代系统中的日志语句更新频繁(例如,每月有数百条新的日志语句)。为了维护正确的正则表达式集,开发人员需要定期检查所有的日志记录语句,既繁琐又容易出错。
我们提出的方法不需要源代码或原始日志消息以外的任何信息。可以自动从原始日志消息中提取日志模板,并将它们拆分为不相交的日志组。它采用固定深度的解析树来指导日志组搜索过程,有效地避免了构建非常深和不平衡的树。达成日志的更好的聚类效果。
3、在日志解析树的构建过程中,起初的设计着基于一些固定的规则来划分树的分支。例如按照日志的长度数值,在向下比较这个分支下的日志模板事件的相似度,且计算日志事件相似度的公式设计的也比较机械,在日志事件的解析聚类中严重受到影响,使得事件的聚类不够紧密。明明两个日志出自同一事件触发引起,但是因为长度的原因而别分成两个事件。我们的方法中设计更加合适规则,来增强事件解析树的聚类能力。
二、数据说明

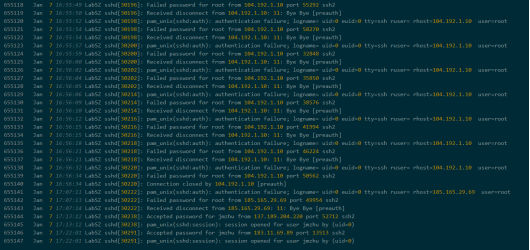
12月10号到1月7号的,655147条ssh服务日志信息,来源IBM Cloud的数据中心的网络基础设施中的事件。IBM Cloud基于位于不同地区和大陆的许多数据中心。在每个数据中心(DC),数千个网络设备都会产生大量的syslog事件。
三、算法内容
一种基于固定深度树的日志解析方法,简单点你可以认为成一种使用分类树的方式给日志文本聚类的过程。当新的原始日志消息到达时,算法会根据领域知识通过简单的正则表达式对其进行预处理。然后我们按照编码在树内部节点中的特殊设计规则搜索日志组(即树的叶节点)。如果找到合适的日志组,则日志消息将与存储在该日志组中的日志事件匹配。否则,将根据日志消息创建一个新的日志组。下面,我们首先介绍固定深度树(即解析树)的结构。和算法流程。
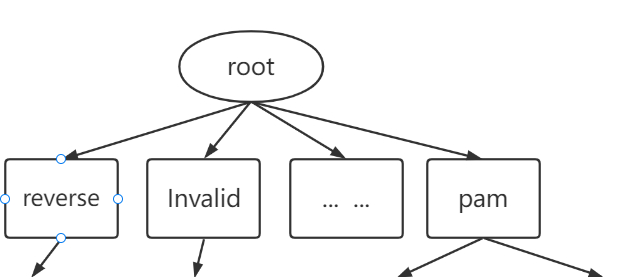
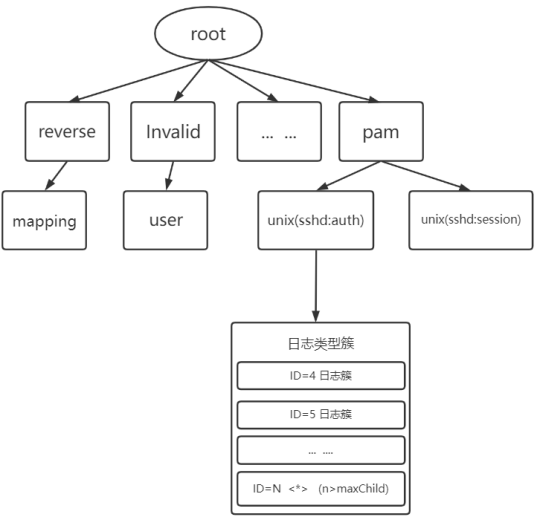
整体树状结构
当原始日志消息到达时,在线日志解析器需要为其搜索最合适的日志组,或者创建一个新的日志组。在这个过程中,一个简单的解决方案是将原始日志消息与存储在每个日志组中的日志事件一一进行比较。但是,这种解决方案非常慢,因为日志组的数量在解析中迅速增加。为了加速这个过程,我们设计了一个固定深度的解析树来指导日志组搜索,它有效地限制了原始日志消息需要比较的日志组的数量。
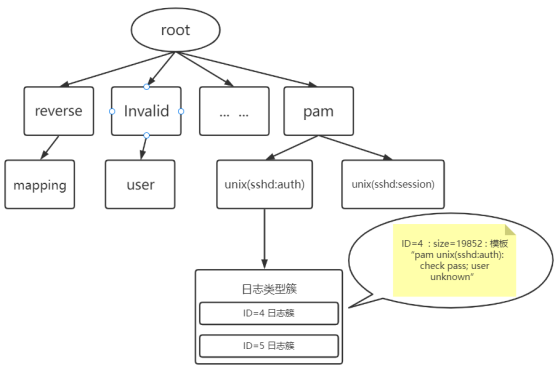
解析树如图所示。根节点位于解析树的顶层;底层包含叶节点;树中的其他节点是内部节点。
根节点和内部节点编码专门设计的规则来指导搜索过程。它们不包含任何日志组。解析树中的每条路径都以一个叶子节点结束,该叶子节点存储了一个日志组列表,为了简单起见,我们在这里只绘制一个叶子节点。每个日志组有两部分:日志事件和日志 ID。日志事件是最能描述该组中的日志消息的模板,它由日志消息的常量部分组成。 Log IDs 记录了该组中日志消息的 ID。解析树的一种特殊设计是所有叶节点的深度相同,并且由预定义的参数深度固定。例如,图中叶子节点的深度固定为 3。该参数限制了搜索过程中访问的节点数,从而大大提高了其效率。此外,为了避免树分支爆炸,我们使用了一个参数 maxChild,它限制了节点的最大子节点数。下面,为了清楚起见,我们将第 n 层节点定义为深度为 n 的节点。此外,除非另有说明,我们以图中的解析树为例进行说明。
程序中文本形式打印树结构示例:
Prefix Tree:
<root>
<reverse>
"mapping" (cluster_count=1)
ID=1: size=18909: reverse mapping checking getaddrinfo for <:*:> [<:IP:>] failed - POSSIBLE BREAK-IN ATTEMPT!
<Invalid>
"user" (cluster_count=1)
ID=2: size=14594: Invalid user <:*:> <:*:> from <:IP:>
<input>
"userauth" (cluster_count=1)
ID=3: size=14594: input userauth request: invalid user <:*:> <:*:> [preauth]
<pam>
"unix(sshd:auth):" (cluster_count=2)
ID=4: size=19852: pam unix(sshd:auth): check pass; user unknown
ID=5:size=155057:pamunix(sshd:auth):logname=uid=<:NUM:>euid=<:NUM:>
"unix(sshd:session):" (cluster_count=1)
ID=17: size=364: pam unix(sshd:session): session <:*:> for user <:*:> <:*:> <:*:>
...
领域知识预处理(步骤一)
对文本信息中一些明现可以看出来是模板中的变量的部分进行预处理可以提高解析精度。因此,在使用解析树之前,我们会在原始日志消息到达时对其进行预处理。具体来说,用户提供基于领域知识的简单正则表达式,这些表达式代表常用变量,例如IP地址和块ID。例如,消息
request 0xefef23 from 127.0.0.1 handled in 23ms
可以被屏蔽为
request from <ip> handled in <num> ms
此步骤中使用的正则表达式通常非常简单,因为它们用于匹配标记而不是日志消息。此外,一个数据集通常只需要几个这样的正则表达式。大部分日志消息通常是识别诸如十进制数、十六进制数、ip、电子邮件地址等结构,并使用通配符替换这些结构的过程。
如图是ssh数据集中,预处理中使用的正则匹配模型。

图示的高亮区域的日志,经过预处理后变成:
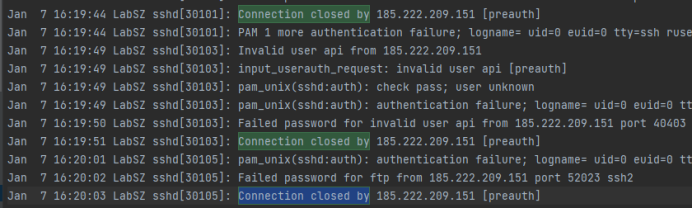

Connection closed by <:IP:> [preauth]
经过预处理的日志信息,可以提高解析树的聚合能力。
按日志第一个词搜索(步骤二)
从带有预处理日志消息的解析树的根节点开始。解析树中的第 1 层节点表示日志组,其日志消息具有不同的日志消息首单词。在此步骤中,Drain 根据预处理后的日志消息的日志消息首单词选择到第 1 层节点的路径。例如,对于日志消息“pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=173.234.31.186 ”,Drain 遍历到图中的内部节点pam。这是基于具有相同日志事件的日志消息可能具有相同的日志消息首单词的假设。因为虽然日志文本信息是非结构的,但是基于其固定的使用场景,一般首字母都是大家形成了一般统一认识了的,(比如web应用系统的日志一般开头是info、error、warring等)可以通过简化的后处理来处理。
按接下来的标记词搜索(步骤三)
在此步骤中,从步骤 2 中搜索到的第 1 层节点遍历到叶节点。此步骤基于日志消息接下来词也可能是常用词的假设(一般前几个词的描述模式都是一定的)。具体来说,通过日志消息开始位置的标记来选择下一个内部节点。例如,对于日志消息“pam unix(sshd:auth): check pass; user unknown”,从第一层节点“pam ”遍历到第二层节点“unix(sshd:auth)”,因为日志消息的第一个位置的令牌是“pam ” ,然后会遍历到与内部节点“unix(sshd:auth)”链接的叶子节点,然后进行第 4 步。在实践中,可以考虑更多具有更大深度设置。请注意,如果深度为 2,则仅考虑步骤 2 使用的第一层。
在某些情况下,日志消息可能以参数开头,例如“120 bytes received”。这些类型的日志消息可能导致解析树中的分支爆炸,因为每个参数(例如,120)都将被编码在一个内部节点中。为了避免分支爆炸,我们在这一步只考虑不包含数字的标记。如果令牌包含数字,它将匹配一个特殊的内部节点“<>”。例如,对于上面的日志消息,Drain 将遍历内部节点“<>”而不是“120”。
此外,我们还定义了一个参数 maxChild,它限制了节点的最大子节点数。如果一个节点已经有 maxChild 子节点,则任何不匹配的标记都将匹配其所有子节点中的特殊内部节点“<*>”。
按日志相似度匹配日志簇(步骤四)
在这一步之前,已经遍历到一个叶子节点,其中包含一个日志组列表。这些日志组中的日志消息符合路径上内部节点中编码的规则。例如,图中的日志组具有日志事件“pam unix(sshd:auth): check pass; user unknown”,其中首单词“pam”,和第二个特征词”unix(sshd:auth)“。对应了两个节点。
在此步骤中,Drain 从日志组列表中选择最合适的日志簇。我们计算每个日志簇的日志消息模板和日志事件之间的相似度, 相似度定义如下:
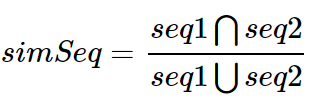
杰卡德系数,英文叫做 Jaccard index, 又称为 Jaccard 相似系数,用于比较有限样本集之间的相似性与差异性。Jaccard 系数值越大,样本相似度越高。 实际上它的计算方式非常简单,就是两个样本的交集除以并集得到的数值,当两个样本完全一致时,结果为 1,当两个样本完全不同时,结果为 0。 算法非常简单,就是交集除以并集。
其中 seq1 和 seq2 分别代表日志模板和日志事件
在找到具有最大 simSeq 的日志组后,我们将其与预先定义的相似度阈值 st 进行比较。如果 simSeq ≥ st,则 Drain 将该组作为最合适的日志组返回。否则,Drain 会返回一个标志(例如 Python 中的 None)以指示没有合适的日志组。
更新解析树(步骤五)
如果第 4 步返回了合适的日志组,会将当前日志消息的日志 ID 添加到返回的日志组中的日志 ID 中。此外,返回的日志组中的日志事件将被更新。具体来说,会扫描日志消息和日志事件相同位置,以日志模板和日志信息中较长的句子作为新的日志模板,同时比较新模板比旧模板多出来信息部分的位置,和相同信息的位置(也就是新模板和就模板差异的位置)。我们在日志模板中通过通配符(即 )更新该差异位置中的标记。并将模板簇的size加一。
例如:
起始,模板为:pam unix(sshd:auth): authentication failure; logname= uid=<:NUM:> euid=<:NUM:> tty=ssh ruser= <::>
在一次更新解析树的过程中匹配到了这条日志信息:pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= r host=173.234.31.186
则新的模板跟新为:pam unix(sshd:auth): authentication failure; logname= uid=<:NUM:> euid=<:NUM:> tty=ssh ruser= <::> <::>
如果 Drain 找不到合适的日志组,它会根据当前的日志消息创建一个新的日志组,其中 ID 仅包含日志消息的 ID,而 日志模板正是该日志消息。然后,将使用新的日志组更新解析树。
四、输出结果
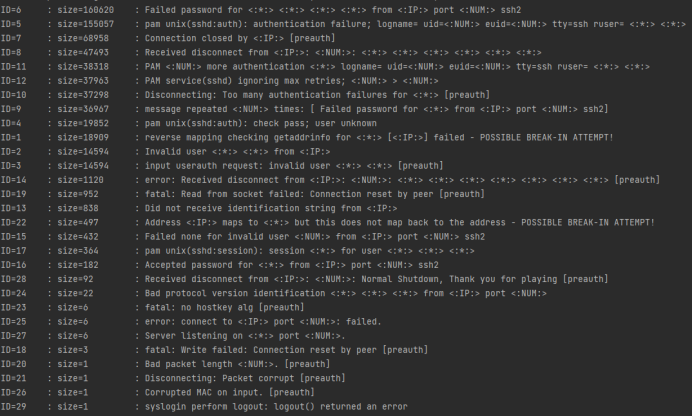
在65万条云服务器的日志信息中解析出29条日志模板。
模板之间互相独立,没有交叉,效果显著。
关于为改进前的Drain的使用方法资料可以查看我这边博客: