
监督学习:找到一条区分正负样本的决策边界

无监督学习是这样的,没有标签
第一个无监督算法——聚类
k-means算法
随机选取两个点,作为第一次迭代的聚类中心
根据离两个源点的远近自动划分两个类
在每个类中,求所有点的平均位置,设置为下一轮的聚类中心
开始下一次迭代
算法核心是找到聚类中心K,使类中所有点离K的距离平方和最小
突发情况,某一个类没有一个点
重新初始化聚类中心:当出现某个聚类中心没有对应数据点时,可以重新初始化聚类中心,使其随机分布在数据空间中的其他位置。这种方法可能会导致算法收敛速度变慢或者陷入局部最优解。
删除该聚类中心:当出现某个聚类中心没有对应数据点时,可以考虑将该聚类中心从聚类中心集合中删除,并重新调整聚类。这种方法可能会导致聚类数目减少,但是可以避免出现除以0的错误。
优化目标

两组变量:c和μ
点i属于簇(类)ci,第j个点的聚类中心是μj
最小化函数J关于变量c
最小化函数J关于μ
然后迭代
随机初始化
1,多次进行聚类中心的初始化,选择J函数最小的一组
选择聚类数量
肘部法则
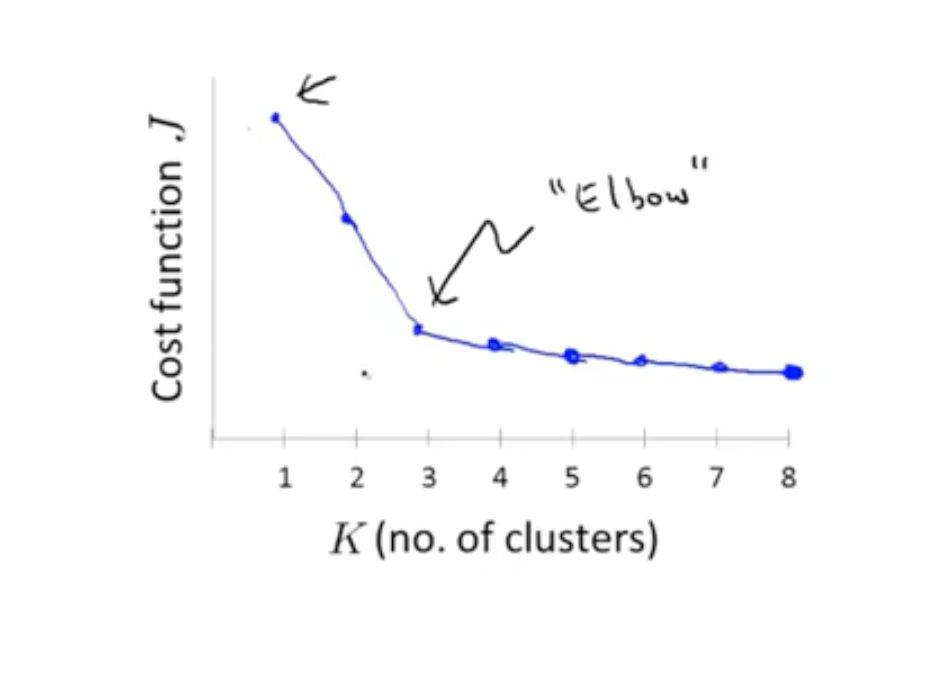
随着类数量增加,J函数值不断减小,类似于肘关节的点对应的类的数量最合适