关于计算机算法发展至今,已有很多不同的分类,目前运用最多是泛化群智能优化算法。譬如:粒子群优化算法(PSO)、鲸鱼优化算法(WOA)、灰狼优化算法(GWO)、蜻蜓优化算法(DA)、宇宙优化算法(MVO)、飞蛾扑火优化算法(MFO)、蚱蜢优化算法等。
关于这些算法的具体讲解,我们都可以在不同的学习网站上浏览到,如:CSDN、知乎等。对于具体算法的讲解,我这里不做赘述,想在这里叙述一下这些算法的共同规律,以便帮助同学对这部分内容有更好的理解。
群智能优化算法的共同点:
1、随机初始化
function X=initialization(SearchAgents_no,dim,ub,lb)%SearchAgents_no为种群数量;dim为解决问题的维度;ub变量上界;lb变量下界
Boundary_no= size(ub,2); % numnber of boundaries
% If the boundaries of all variables are equal and user enter a signle
% number for both ub and lb
if Boundary_no==1
X=rand(SearchAgents_no,dim).*(ub-lb)+lb;
end
% If each variable has a different lb and ub
if Boundary_no>1
for i=1:dim
ub_i=ub(i);
lb_i=lb(i);
X(:,i)=rand(SearchAgents_no,1).*(ub_i-lb_i)+lb_i;
end
end对于一个我们要解决的问题,首先要清楚解决问题的维度,可以粗浅理解为几个X,例如我们有两个X(X1,X2),则我们要解决的问题的维度即为2,在源代码中,我们要规定变量X的范围,不同的X可以有不同的范围,当然根据实际问题,所有变量(X1,X2,......,Xn)的范围也可一致。在上面代码中所呈现的就是lb与ub,在上面的代码中,群数量被规定为SearchAgents_no,一般原始算法中的种群数量为30,则随机初始化过程的结果,可以理解为30行,n列(解决问题的维度为n)的矩阵。
在设置过程中,还有一个重要的参数---最大迭代次数,即为Max_iteration。算法的终止条件有两个,一个为收敛精度(在一定时间内,收敛下降度没有超过设置阈值,其实就是已经差不多最优了,没有必要继续进行下去了。);另一个就是最大迭代次数,一般算法中均以此作为最后的迭代终止条件。具体的数值可以根据相应的参考文献,参照设置。
对于一个具体问题,问题的维度(dim),变量的上下边界,种群数量可以根据实际情况设置,在原始代码提出的时候,会有一系列的测试函数来进行验证。、
[lb,ub,dim,fobj]=Get_Functions_details(Function_name);上面的代码即为从测试函数中提取维度、变量上下边界,和目标函数。关于目标函数,在下面的内容中具体阐述。
2、算法的具体过程
在算法进入迭代循环之前,也就是不断寻优过程之前,会对之前随机化初始矩阵进行适应度计算,如果种群数量为30,则有30个适应度值,通过比较它们的大小,将最小(或最大,一般为最小)作为初始的最佳适应度值,进入后续的迭代寻优中进行计算。
for i=1:size(Positions,1)
Fitness(1,i)=fobj(Positions(i,:));
end上面的代码展示的就是,在迭代寻优之前,对所有种群进行适应度值的计算。
值得一提的是适应度值的概念,可以简单理解为每个种群(每个行向量)通过目标函数公式,计算后数值的大小。
2.1 全局探索与局部开发
全局探索和局部开发两个阶段决定着算法的搜寻质量,两者互联互通,先进行全局大范围的搜索,在进行到一定阶段后,再执行小范围(局部)的精确寻优。至于具体如何进行全局搜索和局部开发,每种算法的逻辑思路不同,可结合代码具体分析。全局探索和局部开发之间存在一个过渡,即算法执行到何时,由全局探索转向局部开发。这个过渡阶段,几乎存在于每个算法逻辑之中。这里以HHO(哈里斯鹰)算法和SSA(樽海鞘)算法为例进行介绍。
在HHO算法中,猎物的能量被用来完成这个过渡过程,它的模型如下所示:
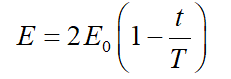
上式中,E 代表猎物的逃逸能量, E0 表示能量强度的初始状态。T为最大迭代次数,t为算法实际迭代次数,作为常规HHO的停止准则。
在SSA算法中,
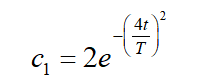
上式中,t代表当前迭代,T表示迭代的最大数。 ![]() 参数具有重要作用,可以在探索和开发趋势之间建立一个适当的平衡。
参数具有重要作用,可以在探索和开发趋势之间建立一个适当的平衡。
以上就是两种算法由全局探索向局部开发阶段过渡的具体表现形式。不同的算法依据逻辑的不同,过渡形式也不尽相同。
至于说全局探索和局部开发的具体实现,各种算法就是八仙过海各显神通了。目前大多数泛化群智能算法都是依据生物的觅食或者生存/生活规律总结而来的。大家可以参考各种算法的原始论文,里面有详细解读。这里简单举例樽海鞘算法。
while l<Max_iter+1/设置的最大迭代限制
c1 = 2*exp(-(4*l/Max_iter)^2); % Eq. (3.2) in the paper/全局探索和局部开发过渡
for i=1:size(SalpPositions,1)
SalpPositions= SalpPositions';
if i<=N/2 /这里根据樽海鞘的觅食特性将种群分为两类,分别为领导者和追随者,首先进行领导者的位置更新。
for j=1:1:dim
c2=rand();
c3=rand();
%%%%%%%%%%%%% % Eq. (3.1) in the paper %%%%%%%%%%%%%%
if c3<0.5
SalpPositions(j,i)=FoodPosition(j)+c1*((ub(j)-lb(j))*c2+lb(j));
else
SalpPositions(j,i)=FoodPosition(j)-c1*((ub(j)-lb(j))*c2+lb(j));
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
end
elseif i>N/2 && i<N+1 /再次进行追随者的位置更新。
point1=SalpPositions(:,i-1);
point2=SalpPositions(:,i);
SalpPositions(:,i)=(point2+point1)/2; % % Eq. (3.4) in the paper
end
SalpPositions= SalpPositions';
end
for i=1:size(SalpPositions,1) /更新完成后,进行边界条件的限制界定。
Tp=SalpPositions(i,:)>ub';Tm=SalpPositions(i,:)<lb';SalpPositions(i,:)=(SalpPositions(i,:).*(~(Tp+Tm)))+ub'.*Tp+lb'.*Tm;
SalpFitness(1,i)=fobj(SalpPositions(i,:));
if SalpFitness(1,i)<FoodFitness
FoodPosition=SalpPositions(i,:);
FoodFitness=SalpFitness(1,i);
end
end
Convergence_curve(l)=FoodFitness;/将得到的个体的适应度值进行储存,放置在收敛曲线中
l = l + 1;/标记迭代次数,迭代累计。
end当执行while的循环中,个体的适应度值不断进行比较。迭代完成后,得出最佳的适应度值。
到这里,算法的整个流程大体清楚,主要参数和流程如上所述。
上面有提到过目标函数问题。针对不同的实际问题,自然目标函数的设置不一样,需要自行编写相关程序。为了方便对算法性能进行测试,已有相关学者编写了标准测试函数。
function [lb,ub,dim,fobj] = Get_Functions_details(F)
switch F
case 'F1'
fobj = @F1;
lb=-100;
ub=100;
dim=30;
case 'F2'
fobj = @F2;
lb=-10;
ub=10;
dim=10;
case 'F3'
fobj = @F3;
lb=-100;
ub=100;
dim=10;
end
end
% F1
function o = F1(x)
o=sum(x.^2);
end
% F2
function o = F2(x)
o=sum(abs(x))+prod(abs(x));
end
% F3
function o = F3(x)
dim=size(x,2);
o=0;
for i=1:dim
o=o+sum(x(1:i))^2;
end
end上面展示的是F1到F3,三个标准测试函数。可以看到在Get_Functions_details中,我们读取了函数的边界、维度、目标函数,这里的目标函数运用了@的技巧,具体的函数形式也以 function o = F(x) 的形式给出。
大概的算法流程基本如此,有需要一些算法程序,或者不懂的可以私信讨论,一起学习。