问题描述

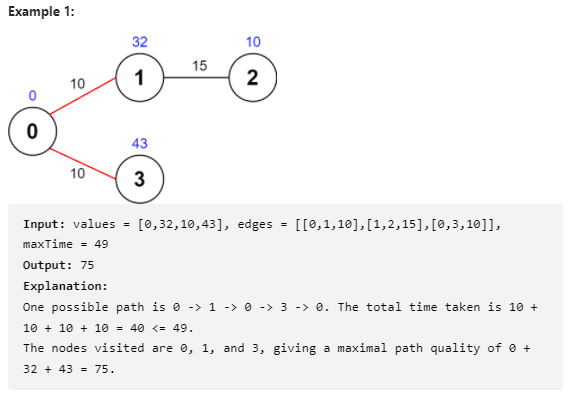
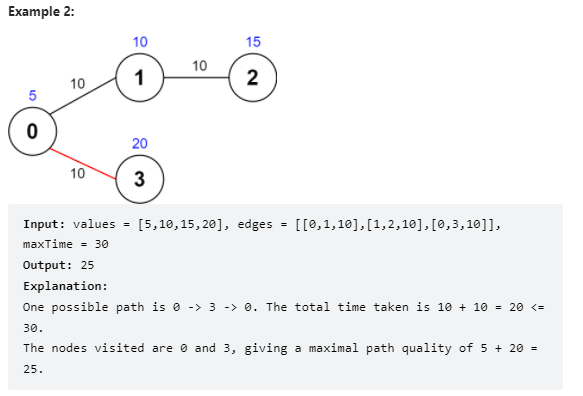
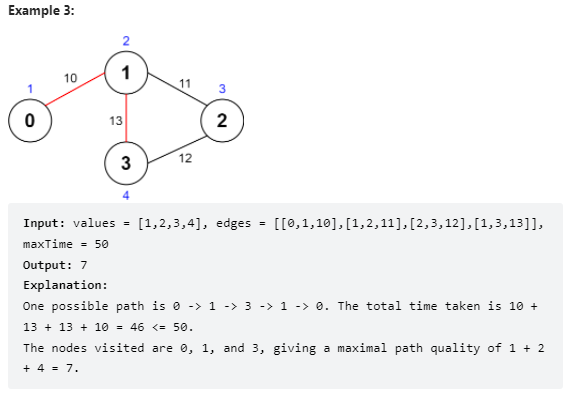
思路与代码
本体参考官方题解,通过深度优先搜索解决:
LeetCode 2065 官方题解
注意两件事情:
- 当重复到达某一节点时,不能重复获取价值;
- 若起点为孤立点,直接返回。
代码如下:
class Solution:
def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:
# node to (node, time) list dictionary
dict_node_edge = {
}
for i, j, t in edges:
if i not in dict_node_edge.keys():
dict_node_edge[i] = [(j, t)]
else:
dict_node_edge[i].append((j, t))
if j not in dict_node_edge.keys():
dict_node_edge[j] = [(i, t)]
else:
dict_node_edge[j].append((i, t))
set_node_visit = {
0}
ans = 0
def dfs(node: int, time: int, value: int) -> None:
nonlocal ans
if node == 0:
ans = max(ans, value)
if node not in dict_node_edge.keys():
return
for node_next, time_cost in dict_node_edge[node]:
if time + time_cost <= maxTime:
if node_next not in set_node_visit:
set_node_visit.add(node_next)
dfs(node=node_next, time=time + time_cost, value=value + values[node_next])
set_node_visit.remove(node_next)
else:
dfs(node=node_next, time=time + time_cost, value=value)
dfs(node=0, time=0, value=values[0])
return ans
其中,若 dict_node_edge 字典使用 defaultdict 类型,则可以利用其特性,不必对起点为孤立点的情况进行特殊处理,如官方题解所示:
class Solution:
def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:
g = defaultdict(list)
for x, y, z in edges:
g[x].append((y, z))
g[y].append((x, z))
visited = {
0}
ans = 0
def dfs(u: int, time: int, value: int) -> None:
if u == 0:
nonlocal ans
ans = max(ans, value)
for v, dist in g[u]:
if time + dist <= maxTime:
if v not in visited:
visited.add(v)
dfs(v, time + dist, value + values[v])
visited.discard(v)
else:
dfs(v, time + dist, value)
dfs(0, 0, values[0])
return ans
但依笔者平时的代码习惯,通常会避免 defaultdict 产生意想不到的 key 的副作用,因此不使用该类型。
笔者代码的运行效果如下:
引申思考
本题的思路,也可用于解决网格地图的路径问题,即各网格点到达的成本或收益各不相同的情况,此时无法通过原始 A* 算法解决,只能使用本题方法进行搜索。但该问题本质上搜索空间过大,很难完成较大区域内的最优寻路。