文章目录
Hash table,作为一个重要的用于集合(collection)的数据结构,并不是 C++ 标准库第一版的一部分。它们并不是原始 STL 的一部分,标准委员会认为,将它们纳入 C++98 的提案太晚呈现了(在某个时间点你必须停止引入特性,把专注力和焦点放在细节上面,否则永远无法结束工作。)然而,自 TR1 起,带有 hash table 特性的容器终于走入了 C++ 标准。
尽管如此,早在 TR1 之前,C++ 社群就已经出现若干可用的 hash table 实现。这些程序库通常会提供四种 hash table:hash_set、hash_multiset、hash_map 和 hash_multimap。那些 hash table 如今被略微不同地实现出来。TR1 引入了一个以 hash table 为基础的容器群,这些标准化的 class 所提供的特性结合原有实现,但又不完全吻合其中任何一个。为了避免名称冲突,它们选择不一样的 class 名称。最终决议是,提供所有原本已存在的那些 associative 容器,但改而带着前缀 unordered_。这也显示它和其他 associative 容器之间的最重要差异:“以 hash table 为基础”的容器,其内的元素没有清晰明确的次序。
严格地说,C++ 标准库称呼 unordered 容器为 unordered associative 容器。然而当我指称它们时,我只说 unordered 容器。如果我说 associative 容器,我指的是旧式 associative 容器,也就是自 C++98 开始提供并被实现为 binary tree 的那些:set、 multiset、map 和 multimap。
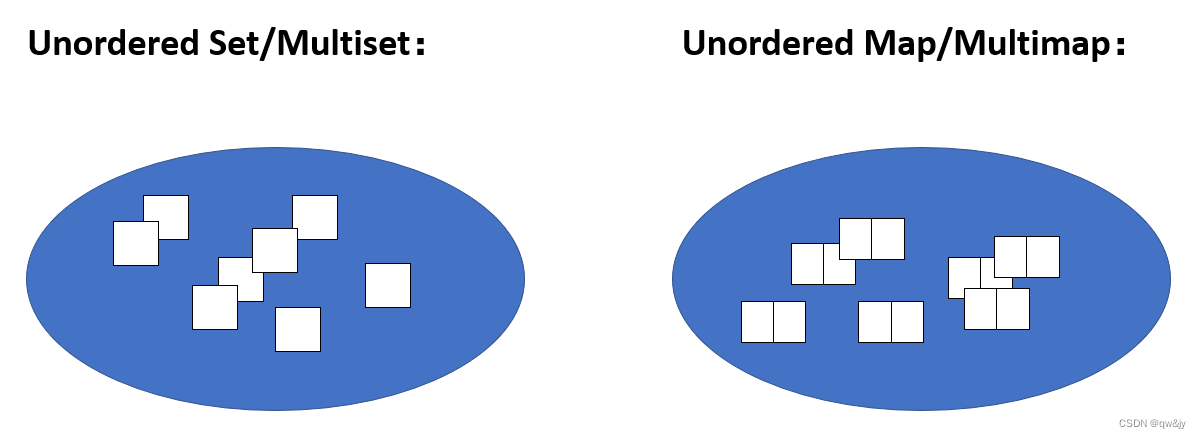
概念上,unordered 容器以一种随意顺序(如上图所示)包含你安插进去的所有元素。也就是说,你可以把这个容器想成一个袋子(bag):你可以放元素进去,但当你打开袋子对所有元素做某些事,你是以一种随机的次序来访问它们。所以,相比于(multi)set 和(multi)map,这里不需要排序准则;相比于 sequence 容器,你没有语义可用来放元素到某个特定位置。
就像各个 associative 容器那样,这里的个别 class 也互不相同:
- Unordered set 和 multiset 存放的是某特定类型的个别 value,而 unordered map 和 multimap 存放的元素都是 key/value pair,其中 key 被用来作为“存放和查找某特定元素(包含相应的 value)”的依据。
- Unordered set 和 map 都不允许元素重复,而 unordered multiset 和 multimap 都允许。
欲使用一个 unordered set 或 unordered multiset,你必须首先包含头文件 <unordered_set>。
欲使用一个 unordered map 或 multimap,你必须首先包含头文件 <unordered_map> :
#include <unordered_set>
#include <unordered_map>
在那里,上述四种类型分别被定义为 namespace std 内的 class template:
namespace std {
template <typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<T> >
class unordered_set;
template <typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<T> >
class unordered multiset;
template <typename Key,typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<pair<const Key,T> > >
class unordered map;
template <typename Key, typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<pair<const Key,T> > >
class unordered_ multimap;
}
一个 unordered set 或 unordered multiset 的元素类型,可以是任意指派的 T,只要它是可比的(comparable)。
对于 unordered map 和 unordered multimap,第一个 template 参数是元素的 key 类型,第二个 template 参数是元素的 value 类型。一个 unordered map 或 unordered multimap 的元素可拥有任何类型的 Key 和 T,只要它们满足以下两个条件:
- Key 和 value 都必须可被复制或可被搬移(copyable or movable)。
- Key 必须可被“等价准则”拿来比较(comparable with the equivalence criterion)。
注意,元素类型(value_type)是个 pair<const Key , T>。
可有可无的第二或第三 template 参数用来定义 hash function。如果没有指明使用哪个 hash function,就使用默认的 hash<>,这是个 function object,定义于 ,可用于所有整数类型、浮点数类型、pointer、 string 及若干特殊类型。至于其他 value 类型,你必须传入你自己的hash function。
可有可无的第三或第四 template 参数用来定义等价准则(equivalence criterion):这是一个 predicate(判断式),用来查找元素。它用来判断“两个 value 是否相等”。如果没有指定,就使用默认的 equal_to<>,它会以 operator == 比较两个元素。
可有可无的第四或第五 template 参数用来定义内存模型。默认的内存模型(memory model)是 allocator,由 C++ 标准库提供。
Unordered 容器的能力
所有标准化 unordered container class 都以 hash table 为基础。尽管如此,仍允许种种实现选择。通常 C++ 标准库并不指明所有实现细节,这样才能允许种种可能的选择,但 unordered 容器仍有若干被具体指明的性质,基于以下假设:
- 这些hash table使用chaining做法,于是一个hash code将被关联至一个linked list(此技术又称为open hashing或closed addressing,请不要和open addressing或closed hashing混淆)。
- 上述那些linked list是单链或双链,取决于实现。C++ standard 只保证它们的iterator“至少”是forward iterator。
- 关于rehashing(重新散列),有各式各样的实现策略:
传统做法是,在单一insert或erase动作出现时,有时会发生一次内部数据重新组织。
所谓递进式(incremental hashing)做法是,渐进改变bucket或slot的数量,这对即时(real-time))环境特别有用,因为在其中“突然放大 hash table”的代价也许太高。
Unordered 容器允许上述二种策略。
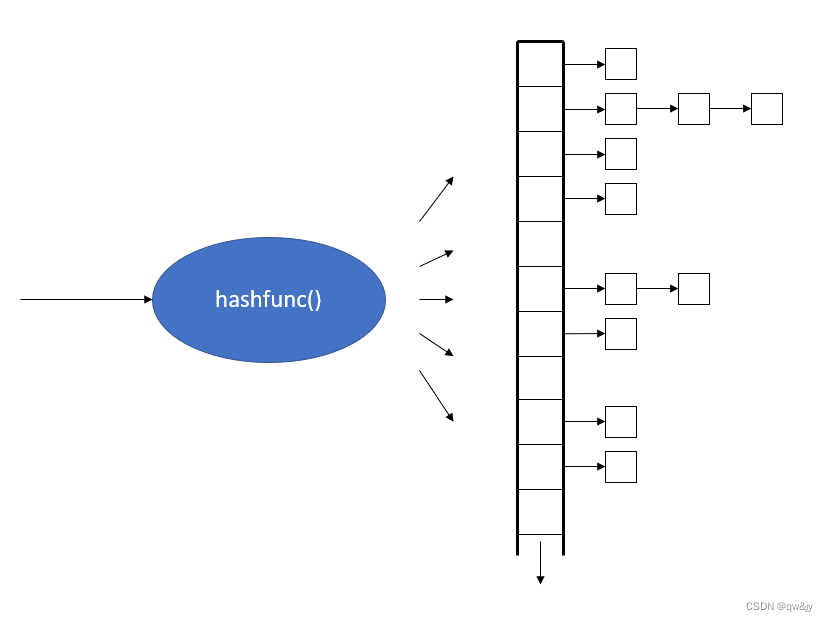
下图显示了 unordered set 或 unordered multiset 的典型内部布局,依据 C++ 标准库给予的最低保证。对于每个将被存放的 value,hash function 会把它映射至 hash table 内某个 bucket(slot)中。每个 bucket 管理一个单向 linked list,内含所有“会造成 hash function 产出相同数值”的元素。
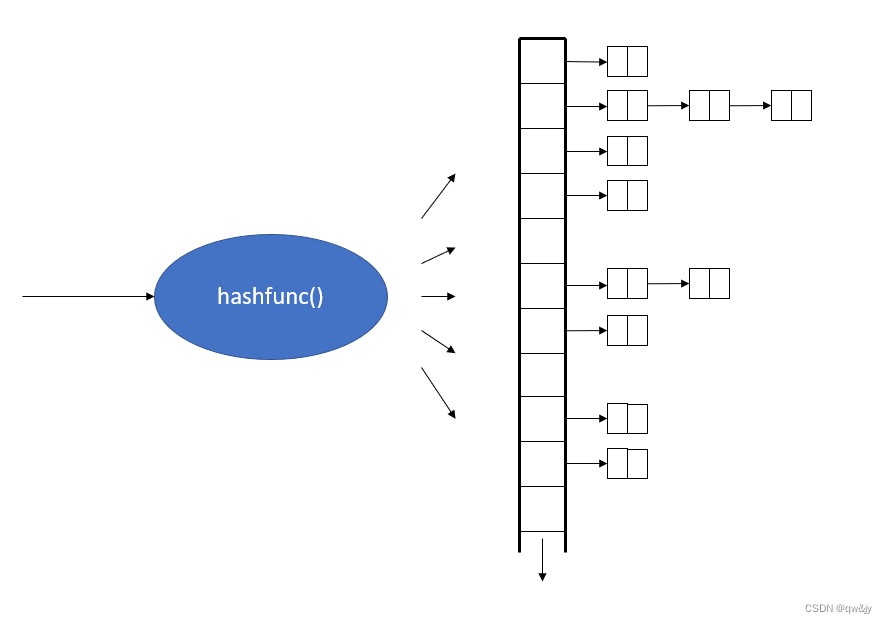
下图显示了 unordered map 或 unordered multimap 的典型内部布局,依据 C++ 标准库给予的最低保证。对于每个将被存放的元素(一个 key/value pair),hash function 会把 key 映射至 hash table 内的某个 bucket(slot)中。每个 bucket 管理一个单向 linked list,内含所有“会造成 hash function 产出相同数值”的元素。
内部使用 hash table,其主要优点是,它惊人的运行期行为。假设拥有良好的 hashing 策略,并且有良好的实现,你可以保证在安插、删除、查找元素时获得摊提(amortized)常量时间(之所以是摊提的,因为偶尔发生的 rehashing 可能是个大型操作,带着线性复杂度)。
Unordered 容器的几乎所有操作—包括拷贝构造(copy construction)和赋值(assignment),元素的安插和寻找,以及等价比较——的预期行为,都取决于 hash function 的质量。如果 hash function 对不同的元素竟产生相等数值(当一个允许元素重复的 unordered 容器带有等价的 value 或 key,这也会发生), hash table 的任何操作都会导致低下的执行效率。这个缺点不完全是由于数据结构本身,也因为客户对此没有足够的意识。
Unordered 容器比起寻常的 associative 容器,也有若干缺点:
- Unordered 容器不提供 operator<、>、<= 和 >= 用以安排布置(order)这些容器的多重实例(multiple instance)。然而提供了 == 和 !=(自从 C++11)。
- 不提供 lower_bound() 和 upper_bound()。
- 由于 iterator 只保证至少是个 forward iterator,因此反向 iterator 包括 rbegin()、rend()、crbegin() 和 crend() 都不提供,你不能够使用那种要求获得 bidirectional iterator 的算法(或说至少这么做不具移植性)。
由于元素的(key)value 具体关系到元素的位置——这里指的是 bucket entry——你不可以直接改动元素的(key)value。因此,很像 associative 容器那样,欲改动一个元素的 value,你必须先移除拥有旧 value 的元素,然后安插一个拥有新 value 的新元素。这个接口反映出以下行为:
- Unordered 容器不提供“直接元素访问操作”。
- 通过 iterator 进行的间接访问有其束缚:从 iterator 的角度观之,元素的(key)value 是常量。
身为一个程序员,你可以指定若干会影响 hash table 行为的参数:
- 你可以指定 bucket 的最小数量。
- 你可以(并且有时候必须)提供你自己的 hash function。
- 你可以(并且有时候必须)提供你自己的等价准则(equivalence criterion):它必须是个 predicate (判断式),用来在 bucket list 的所有数据项中找出准确的元素。
- 你可以指定一个最大负载系数(maximum load factor),一旦超过就会自动 rehashing。
- 你可以强迫 rehashing。
但是你不能够影响以下行为:
- 成长系数(growth factor),那是“自动 rehashing”时用来成长或缩小 list of buckets 的系数。
- 最小负载系数(minimum load factor),用来强制进行 rehashing(当容器中的元素个数缩减)。
注意,rehashing 只可能发生在以下调用之后:insert()、 rehash()、reserve() 或 clear()。这是以下保证的自然结果:erase() 绝不会造成指向元素的 iterator、reference 和 pointer 失效。因此,如果你删除数百个元素,bucket 的大小并不会改变。但如果你在那之后安插一个元素,bucket 的大小就有可能缩小。
也请注意,在那些支持等价(equivalent)key 的容器内,也就是说在 unordered multiset 和 multimap 内,带有等价 key 的元素将会被相邻排列(当你逐一迭代容器的元素时)。Rehashing 以及其他“可能于内部改变元素次序”的操作,都会维持“带有等价 key”的元素的相对次序。
创建、复制和销毁
下表列出了可使用这些构造函数和析构函数的所有可能的 Unord 类型。
| Unord | 效果 |
|---|---|
| unordered_set | 一个 unordered set,使用 hash<>作为默认的hash函数,使用 equal_to<>(operator ==) 作为默认的比较函数 |
| unordered_set<Elem ,Hash> | 一个 unordered set,使用 Hash 作为默认的hash函数,使用 equal_to<>(operator ==) 作为默认的比较函数 |
| unordered_set<Elem, Hash , Cmp> | —个 unordered set,使用 Hash 作为默认的 hash 函数,使用 Cmp 作为默认的比较函数 |
| unordered_multiset | —个 unordered multiset,使用 hash<> 作为默认的 hash 函数,使用 equal_to<>( operator==) 作为默认的比较函数 |
| unordered_multiset<Elem, Hash> | 一个 unordered multiset,使用 Hash 作为默认的 hash 函数,使用 equal_to<> (operator==) 作为默认的比较函数 |
| unordered_multiset<Elem, Hash , Cmp> | 一个 unordered multiset,使用 Hash 作为默认的 hash 函数,使用 Cmp 作为默认的比较函数 |
| unordered_map<Key , T> | 一个 unordered map,使用 hash<> 作为默认的hash函数,使用 equal_to<> (operator ==) 作为默认的比较函数 |
| unordered_map<Key , T, Hash> | 一个 unordered map,使用 Hash 作为默认的 hash 函数,使用 equal_to<> (operator ==) 作为默认的比较函数 |
| unordered_map<Key , T, Hash, Cmp> | —个 unordered map,使用 Hash 作为默认的 hash 函数,使用 Cmp 作为默认的比较函数 |
| unordered_multimap<Key , T> | —个 unordered multimap,使用 hash<> 作为默认的 hash 函数,使用equal_to<>( operator ==) 作为默认的比较函数 |
| unordered_multimap<Key , T, Hash> | 一个 unordered multimap,使用 Hash 作为默认的 hash 函数,使用 equal_to<>(operator==)作为默认的比较函数 |
| unordered_multimap<Key , T,Hash , Cmp> | 一个 unordered multimap,使用 Hash 作为默认的 hash 函数,使用 Cmp 作为默认的比较函数 |
下表列出了unordered associative容器的构造函数和析构函数。
| 操作 | 效果 |
|---|---|
| Unord c | Default 构造函数,建立一个 empty unordered 容器,不含任何元素 |
| Unord c(bnum) | 建立一个 empty unordered 容器,内部使用至少 bnum 个 bucket |
| Unord c(bnum , hf) | 建立一个 empty unordered 容器,内部使用至少 bnum 个 bucket 并以 hf 作为 hash function |
| Unord c(bnum, hf, cmp) | 建立一个 empty unordered 容器,内部使用至少 bnum 个 bucket,以 hf 为 hash function,并以 cmp 作为 predicate 用来鉴定等价 value |
| Unord c(c2) | Copy 构造函数,建立某个 unordered 容器的拷贝,类型相同(所有元素都被复制一份) |
| Unord c = c2 | Copy 构造函数,建立某个 unordered 容器的拷贝,类型相同(所有元素都被复制一份) |
| Unord c(rv) | Move constructor; creates an unordered container,taking the contents of the rvalue rv (since C++11) |
| Unord c = rv | Move constructor; creates an unordered container,taking the contents of the rvalue rv (since C++11) |
| Unord c(beg , end) | 建立一个 unordered 容器,以区间 [beg, end) 内的元素为初值 |
| Unord c(beg , end , bnum) | 建立一个 unordered 容器,以区间 [beg, end) 内的元素为初值,内部使用至少 bnum 个 bucket |
| Unord c(beg , end , bnum , hf) | 建立一个 unordered 容器,以区间 [beg, end) 内的元素为初值,内部使用至少 bnum 个 bucket,C 以 hf 为 hashfunction |
| Unord c(beg , end , bnum , hf , cmp) | 建立一个 unordered 容器,以区间 [beg, end) 内的元素为初值,内部使用至少 bnum 个 bucket,以 hf 为 hashfunction,并以 cmp 作为 predicate 用来鉴定等价 value |
| Unord c(initlist) | 建立一个 unordered 容器,以初值列 initlist 中的元素为初值 |
| Unord c = initlist | 建立一个 unordered 容器,以初值列 initlist 中的元素为初值 |
| c.~Unord () | 销毁所有元素并释放内存 |
关于构建,有很多种实参传递形式。一方面,你可以传递众多 value 成为初始元素:
- 来自一个相同类型的既有容器(copy constructor)。
- 来自一个区间 [begin, end) 的所有元素。
- 来自一个初值列内的所有元素。
另一方面,你可以传递若干实参,用来影响 unordered 容器的行为:
- Hash 函数(不是作为 template 实参,就是作为构造函数实参)。
- 等价准则(equivalence criterion)(不是作为 template 实参,就是作为构造函数实参)。
- Bucket的最初数量(作为构造函数实参)。
注意,你不可以指定最大负载系数(maximum load factor)成为类型的部分,或是通过一个构造函数实参指定它,虽然这是你可能经常想要初始设定的东西。欲指定最大负载系数,你必须在构建后立刻调用一个成员函数(见布局操作表):
std::unordered_set<std::string> coll;
coll.max_load_factor(0.7);
传递给 max_load_factor() 的实参必须是个 float。通常 0.7~0.8 是速度和内存消耗量之间一个不错的折中。注意,默认的最大负载系数是 1.0,意思是通常碰撞(collision)会在 rehash 之前发生。基于此,如果你很重视速度,应该总是明确地设置最大负载系数。
布局操作
Unordered容器也提供了一些用来查询及影响内部布局的操作函数。下表列出了这些函数。
| 操作 | 效果 |
|---|---|
| c.hash_function() | 返回 hash 函数 |
| c.key_eq() | 返回“相等性判断式”(equivalence predicate) |
| c.bucket_count() | 返回当前的 bucket 个数 |
| c.max_bucket_count() | 返回 bucket 的最大可能数量 |
| c.load_factor() | 返回当前的负载系数(load factor) |
| c.max_load_factor() | 返回当前的最大负载系数(maximum load factor) |
| c.max_load_factor(val) | 设定最大负载系数(maximum load factor)为 val |
| c.rehash(bnum) | 将容器 rehash,使其 bucket 个数至少为 bnum |
| c.reserve(num) | 将容器 rehash,使其空间至少可拥有 num 个元素(始自 C++11) |
非更易型操作
| 操作 | 效果 |
|---|---|
| c.empty() | 返回是否容器为空(相当于size()==0但也许较快) |
| c.size() | 返回目前的元素个数 |
| c.max_size() | 返回元素个数之最大可能量 |
| c1 == c2 | 判断是否 c1 等于 c2 |
| c1 != c2 | 判断是否 c1 不等于 c2。等同于 !(c1==c2) |
特殊的查找操作
| 操作 | 效果 |
|---|---|
| c.count(val) | 返回“元素值为 val”的元素个数 |
| c.find(val) | 返回“元素值为 val”的第一个元素,如果找不到就返回 val |
| c.equal_range(val) | 返回 val 可被安插的第一个位置和最后一个位置,也就是“元素值==val”的元素区间 |
#include<iostream>
#include<unordered_map>
using namespace std;
int main(){
unordered_map<string, string> coll = {
{
"1", "qw"}, {
"2", "qwjy"}};
printf("qw个数:%d\n", coll.count("1"));
unordered_map<string, string>::const_iterator got = coll.find ("1");
if ( got == coll.end() )
cout << "not found";
else
cout << "found "<<got->first << " is " << got->second<<"\n\n";
return 0;
}

赋值操作
| 操作 | 效果 |
|---|---|
| c = c2 | 将c2的全部元素赋值给c |
| c = rv | 将 rvalue rv 的所有元素以 move assign 方式给予 c(始自C++11) |
| c = initlist | 将初值列 initlist 的所有元素赋值给 c(始自C++11) |
| c1.swap(c2) | 置换 c1 和 c2 的数据 |
| swap(c1 , c2) | 置换 c1 和 c2 的数据 |
迭代器操作
| 操作 | 效果 |
|---|---|
| c.begin() | 返回一个 forward iterator 指向第一元素 |
| c.end() | 返回一个 forward iterator 指向最末元素的下一位置 |
| c.cbegin() | 返回一个 const forward iterator 指向第一元素(始自C++11) |
| c.cend() | 返回一个 const forward iterator 指向最末元素的下一位置(始自C++11) |
| c.rbegin() | 返回一个反向的(reverse) iterator指向反向迭代的第一个元素 |
| c.rend() | 返回一个反向的(reverse) iterator 指向反向迭代的最末元素的下一位置 |
| c.crbegin() | 返回一个 const reverse iterator 指向反向迭代的第一元素(始自C++11) |
| c.crend() | 返回一个 const reverse iterator 指向反向迭代的最末元素的下一位置(始自C++11) |
安插和移除操作
| 操作 | 效果 |
|---|---|
| c.insert(val) | 安插一个 val 拷贝,返回新元素位置,不论是否成功——对 unordered container 而言 |
| c.insert(pos , val) | 安插一个 val 拷贝,返回新元素位置(pos 是个提示,指出安插动作的查找起点。若提示恰当可加快速度) |
| c.insert(beg , end) | 将区间 [beg, end) 内所有元素的拷贝安插到 c(无返回值) |
| c.insert(initlist) | 安插初值列 initlist 内所有元素的一份拷贝(无返回值,始自 C++11) |
| c.emplace(args . . .) | 安插一个以 args 为初值的元素,并返回新元素的位置,不论是否成功——对 unordered container 而言(始自 C++11) |
| c.emplace_hint(pos ,args . . .) | 安插一个以 args 为初值的元素,并返回新元素的位置(pos 是个提示,指出安插动作的查找起点。若提示恰当可加快速度) |
| c.erase(val) | 移除“与 val 相等”的所有元素,返回被移除的元素个数 |
| c.erase(pos) | 移除 iterator 位置 pos 上的元素,无返回值 |
| c.erase(beg , end) | 移除区间 [beg, end) 内的所有元素,无返回值 |
| c.clear() | 移除所有元素,将容器清空 |
#include<iostream>
#include<unordered_map>
using namespace std;
void Print(unordered_map<string, string> c, string str)//控制台打印
{
cout << str << endl;
for (auto& x: c)
cout << x.first << ": " << x.second << endl;
cout << endl;
}
int main(){
unordered_map<string, string> coll, c = {
{
"1", "qw"}, {
"2", "qwjy"}};
pair<string, string> a ("3", "qw&jy");
//插入
coll.insert(a);// 复制插入
coll.insert(make_pair<string, string>("4", "qwcc"));// 移动插入
coll.insert(c.begin(), c.end());// 范围插入
coll.insert({
{
"5", "qw1"}, {
"6", "qw2"}});// 初始化数组插入(可以用二维一次插入多个元素,也可以用一维插入一个元素)
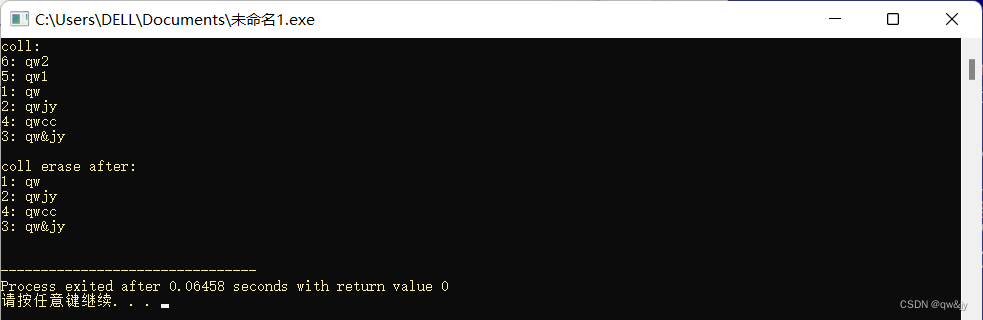
Print(coll, "coll:");
//移除
coll.erase(coll.begin());//通过位置
coll.erase("5");//通过key
Print(coll, "coll erase after:");
return 0;
}
Bucket接口
| 操作 | 效果 |
|---|---|
| c.bucket_count() | 返回当前的 bucket 个数 |
| c.bucket(val) | 返回 val 将(或可能)被找到的那个 bucket 的编号 |
| c.bucket_size(buckidx) | 返回第 buckidx 个 bucket 所含的元素个数 |
| c.begin(buckidx) | 返回一个 forward iterator,指向第 buckidx 个 bucket 中的第一元素 |
| c.end(buckidx) | 返回一个 forward iterator,指向第 buckidx 个 bucket 中的最末元素的下一位置 |
| c.cbegin(buckidx) | 返回一个 const forward iterator,指向第 buckidx 个 bucket 中的第一元素 |
| c.cend(buckidx) | 返回一个 const forward iterator,指向第 buckidx 个 bucket 中的最末元素的下一位置 |
Unordered Map的“元素直接访问”操作
| 操作 | 效果 |
|---|---|
| c[key] | 安插一个带着 key 的元素——如果尚未存在于容器内。返回一个 reference 指向带着 key 的元素(only for nonconstant unordered maps) |
| c.at(key) | 返回一个 reference 指向带着 key 的元素(始自C++11) |
#include<iostream>
#include<unordered_map>
using namespace std;
int main(){
unordered_map<string, string> coll;
coll["1"] = "qw";
cout << coll.at("1");
return 0;
}
