前言
项目需要,研究了一下主成分分析的c#实现,这里记录一下,也供有需要的朋友学习,主要通过调用Accord.Math程序包实现主成分分析中特征值以及特征向量的计算。
有关主成分分析计算指标权重的原理可以参考,链接: https://blog.csdn.net/qq_43517528/article/details/119578525.这里不做详细介绍。
一、安装需要的程序包
主要用到了Accord.Math以及Accord.Statistics程序包,安装方法如下:
第一步:打开VS的NuGet包管理器中的管理方案的NuGet程序包。如下图所示。
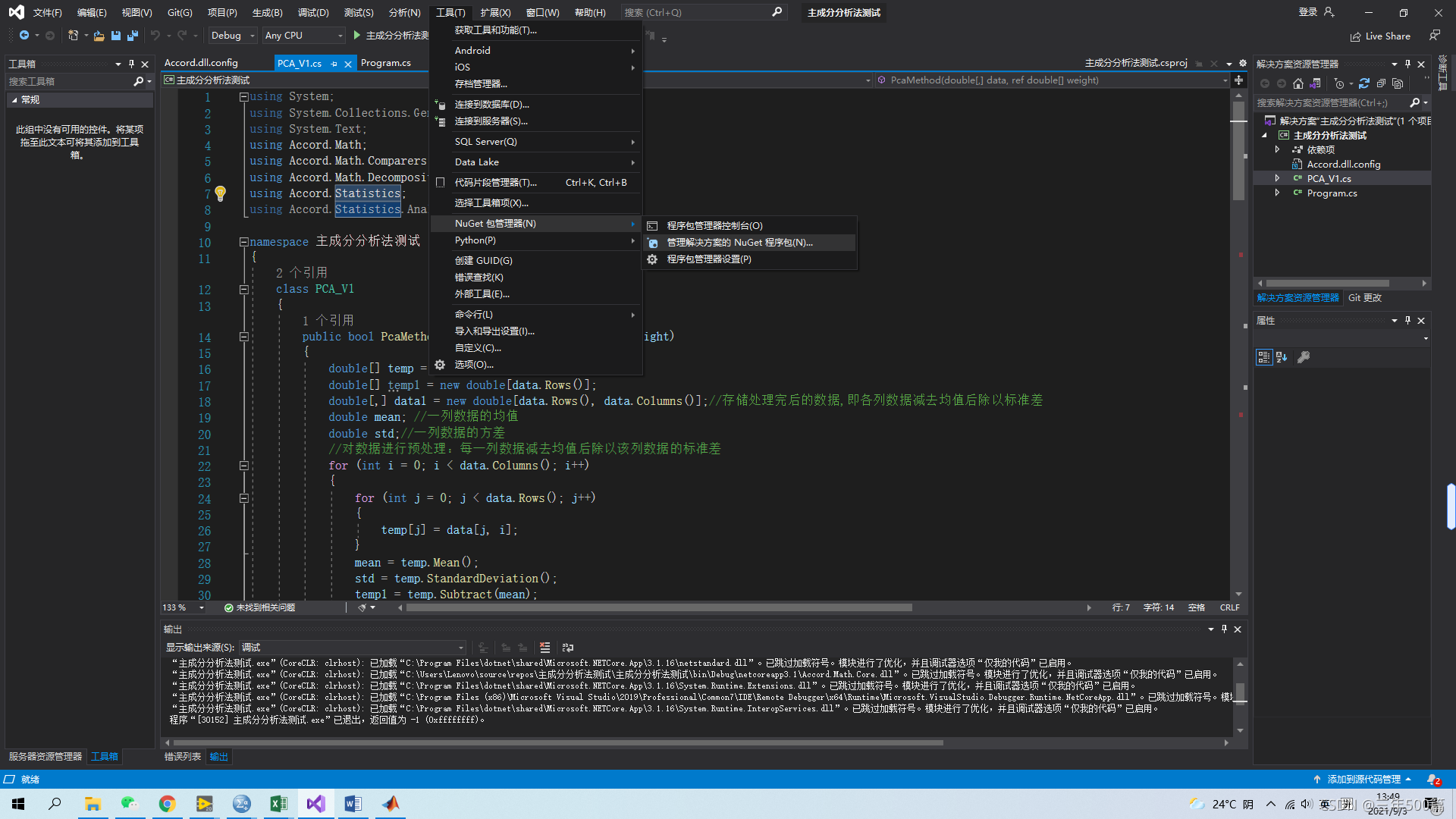
第二步,在浏览选项中,输入Accord,如下图所示。
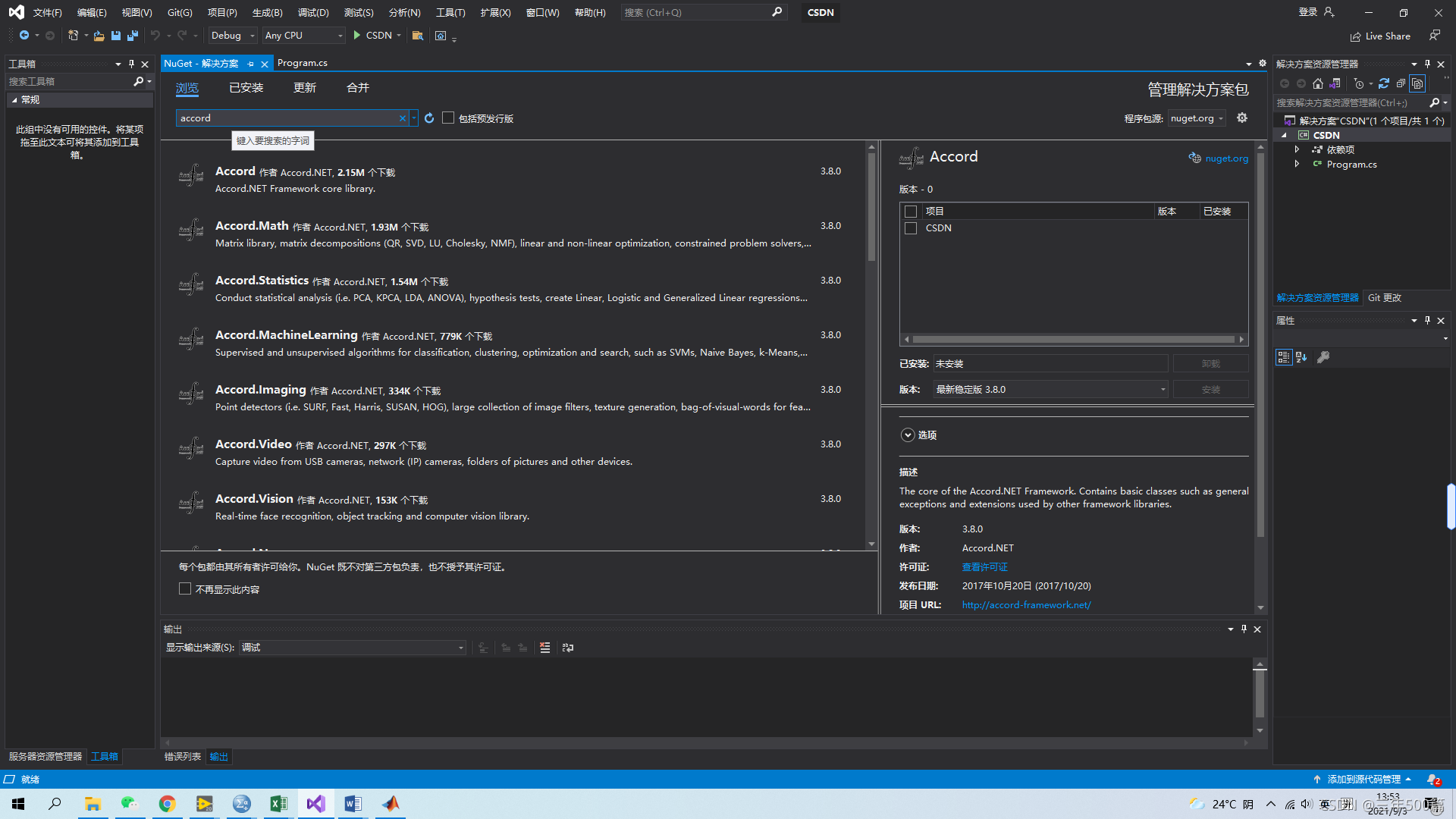
第三步:选择Accord.Math,勾选右侧的项目后,点击安装。
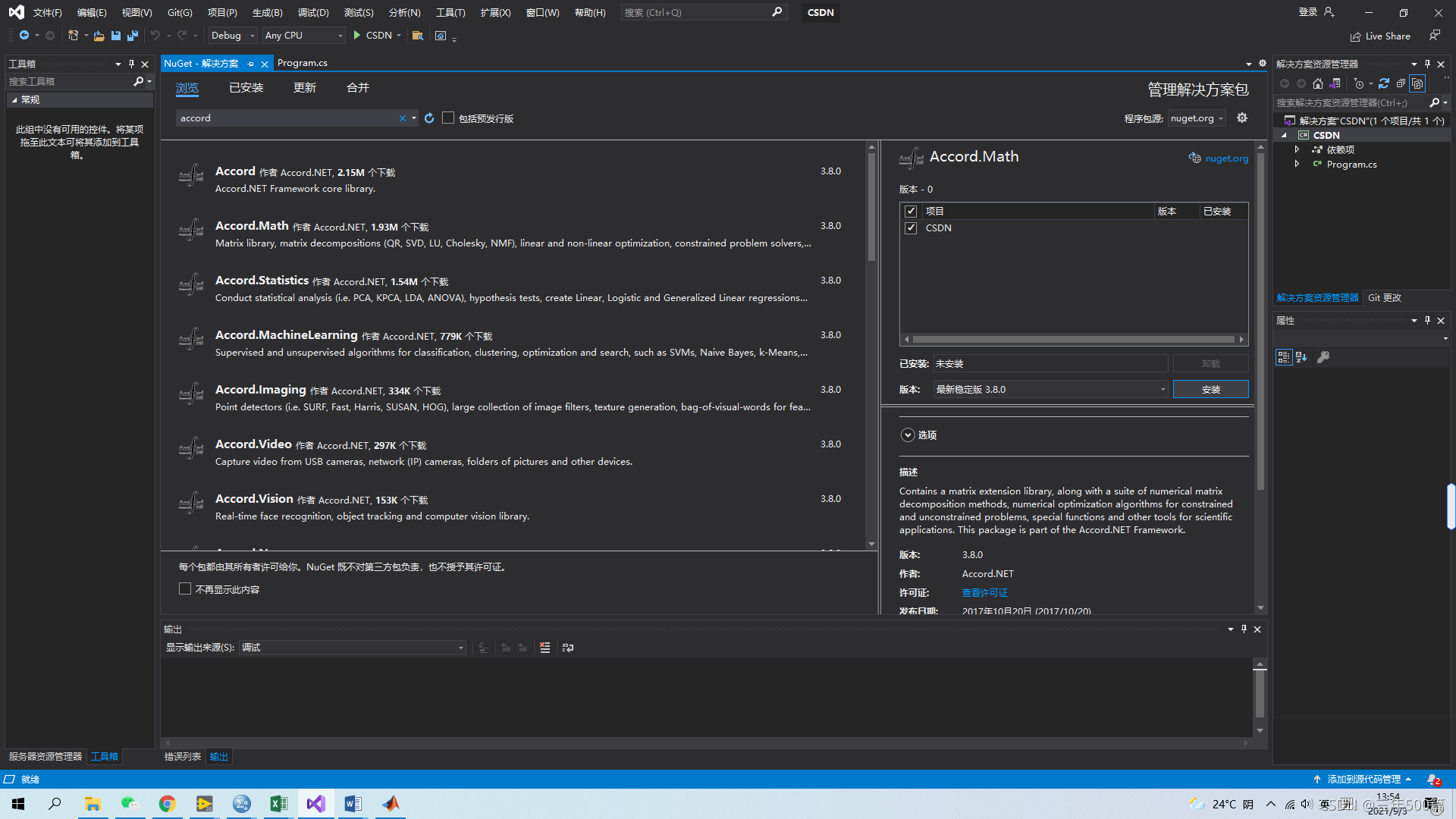
第四步:在弹出的对话框中点击确定,等待安装完成。
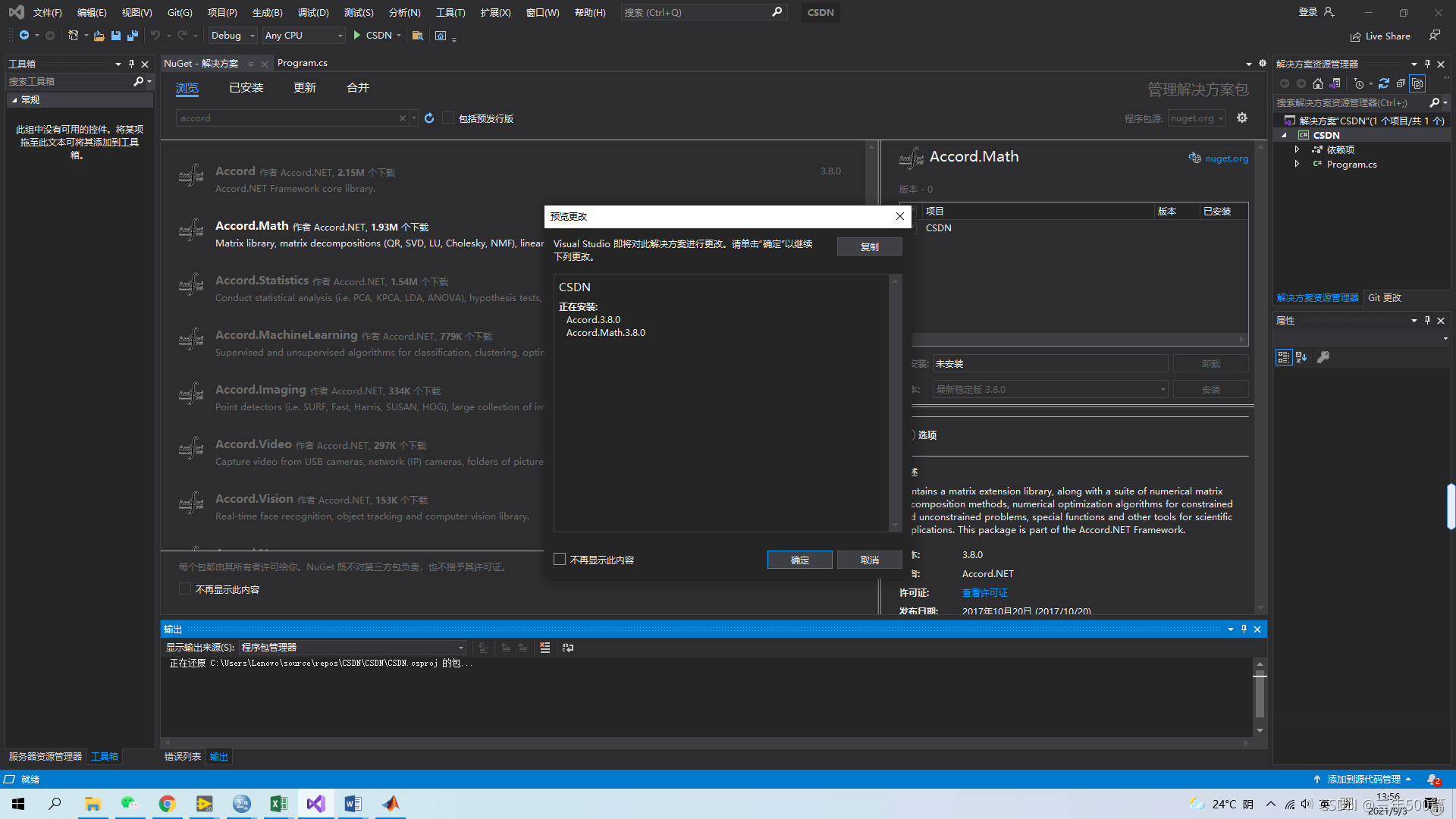
第五步:用同样的方法安装Accord.Statistics
二、源程序
这里把主成分分析求指标权重的方法单独写在了一个类中,在主函数中去调用它。
1.PCA函数
代码如下:注意需要引用如下命名空间:
using Accord.Math;
using Accord.Math.Comparers;
using Accord.Math.Decompositions;
using Accord.Statistics;
using Accord.Statistics.Analysis;
using System;
using System.Collections.Generic;
using System.Text;
using Accord.Math;
using Accord.Math.Comparers;
using Accord.Math.Decompositions;
using Accord.Statistics;
using Accord.Statistics.Analysis;
namespace 主成分分析法测试
{
class PCA_V1
{
public bool PcaMethod(double[,] data,ref double []weight)
{
double[] temp = new double[data.Rows()];
double[] temp1 = new double[data.Rows()];
double[,] data1 = new double[data.Rows(), data.Columns()];//存储处理完后的数据,即各列数据减去均值后除以标准差
double mean; //一列数据的均值
double std;//一列数据的方差
//对数据进行预处理:每一列数据减去均值后除以该列数据的标准差
for (int i = 0; i < data.Columns(); i++)
{
for (int j = 0; j < data.Rows(); j++)
{
temp[j] = data[j, i];
}
mean = temp.Mean();
std = temp.StandardDeviation();
temp1 = temp.Subtract(mean);
temp = temp1.Divide(std);
for (int j = 0; j < data.Rows(); j++)
{
data1[j, i] = temp[j];
}
}
//计算相关系数矩阵
double[,] cov = data1.Correlation();
//计算特征值以及特征向量
try
{
var evd = new EigenvalueDecomposition(cov);
double[] eigenvalues = evd.RealEigenvalues;
double[,] eigenvectors = evd.Eigenvectors;
// 对特征向量进行降序排列
eigenvectors = Accord.Math.Matrix.Sort(eigenvalues, eigenvectors, new GeneralComparer(ComparerDirection.Descending, true));//eigenvalues没有实现降序排序
//对特征值实现降序排序
for (int i = 0; i < eigenvalues.Length; i++)
{
for (int j = i + 1; j < eigenvalues.Length; j++)
{
double t = 0;
if (eigenvalues[i] < eigenvalues[j])
{
t = eigenvalues[i];
eigenvalues[i] = eigenvalues[j];
eigenvalues[j] = t;
}
}
}
//默认信息保留率为0.9,提取该信息保留率下的主成分
double sum = eigenvalues.Sum();
double sum1 = 0;
int k = 0;
for (int i = 0; i < eigenvalues.Length; i++)
{
sum1 = sum1 + eigenvalues[i] / sum;
if (sum1 < 0.9)
{
k++;
}
else
{
k++; //表示提取了K个主成分
break;
}
}
//计算各指标的权重(计算方法:对指标在各个主成分的线性组合的加权系数做平均)
double[] weight1 = new double[eigenvalues.Length];
for (int i = 0; i < eigenvectors.Rows(); i++)
{
double sum_temp = 0;
for (int j = 0; j < k; j++)
{
sum_temp = sum_temp + eigenvectors[i, j] * eigenvalues[j] / sum;
}
weight1[i] = sum_temp / sum1;
}
//对各权重做归一化处理
//对权重出现负值的处理(一般情况下不会出现负值),处理思路是:若有负权重,找到最小的那个负的权重,--
//--所有权重值加上这个权重之后进行归一化处理。
double min_weight;
min_weight = weight1.Min();
if (min_weight < 0)
{
weight1 = weight1.Add(-min_weight + 0.01);
}
for (int i = 0; i < weight1.Length; i++)
{
weight[i] = weight1[i] / weight1.Sum();
}
return true;
}
catch
{
return false;
}
}
}
}
2.主函数
在主函数中调用PCA函数,代码如下:
using System;
using Accord.Math;
namespace 主成分分析法测试
{
class Program
{
static void Main(string[] args)
{
//一组模拟数据,二维数组的每一行为同一时间下不同气体的值,每一列为同一气体在不同时间下的值。
double[,] data = new double[,] {
{
54.86, 29.04,13.35,1}, {
0.1, 9.33,0.42,1}, {
101.67, 52.98,25.65,2}, {
3.08, 16.31,1.64,2}, {
0, 66.38,0,3} ,{
1.36,52.89,0.57,3},{
0.22,113.03,0.17,4},{
0.18,86.35,0.13,4 },{
0.16,76.32,0.11,5} ,{
7,8,9,5},{
2,3,4,6} };
//生成一个PCA_V1对象
PCA_V1 pca = new PCA_V1();
//由于用到了ref参数,在主函数中需要定义weight,其大小与原始数据data的列数一致
double[] weight = new double[data.Columns()];
//调用PcaMethod方法,若返回值为true,表示计算没有错误,weight的值可用,若为false,表示计算过程出现错误,weight的值不可用。
bool IsTrue =pca.PcaMethod(data, ref weight);
}
}
}
注意:data中每一列为一个指标的值随着时间的变化,即,有几列就有几个指标。
总结
源文件稍后上传。