前言
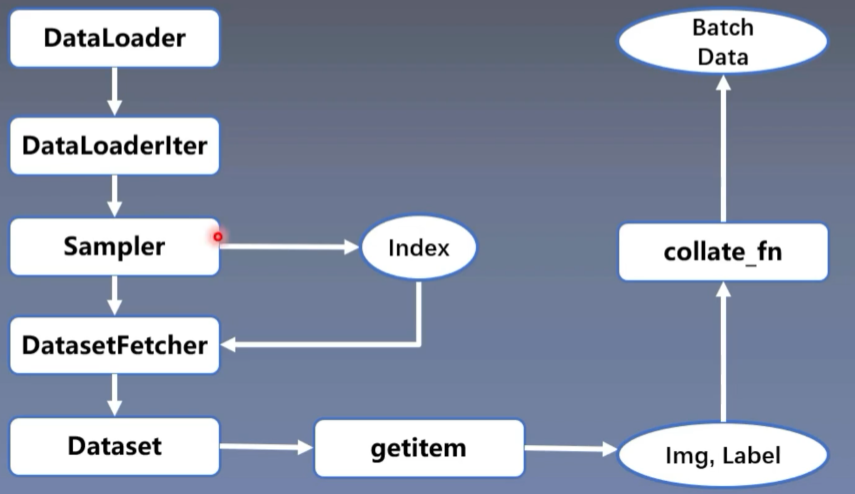
在模型训练的步骤中,数据的部分非常重要,它的过程主要分为数据收集、数据划分、数据读取、数据预处理。
数据收集的有原始样本和标签(Img,label)
数据集的划分需要分为训练集、验证集、测试集。
训练集负责训练模型,验证集负责验证模型是否过拟合,测试集是用来测试性能的。
数据读取主要就是DataLoader的内容
- DataLoader分为两个子模块,分别是Sampler和DataSet
Sampler的功能是生成索引(Index)
DataSet则是根据索引来读取数据
数据预处理需要用transforms来实现
自定义数据集类
PyTorch的自定义数据集可使用Dataset类、IterableDataset类来定义,前者用于实现Map-style(映射风格)的数据集,后者用于实现迭代风格的数据集。
DataLoader 和 Dataset
DataLoader 和 Dataset是pytorch数据读取的核心
Dataset
torch.utils.data.Dataset
功能:Dataset抽象类,所有自定义的Dataset需要继承它,并且复写__ getitem __()
getitem:
接收一个索引,返回一个样本

使用Dataset类重载鸢尾花数据集
import numpy as np
import torch
from torch.utils.data import Dataset
import numpy as np
class IrisDataset(Dataset):
'''鸢尾花数据集'''
def __init__(self):
super(IrisDataset).__init__()
data = np.loadtxt()("鸢尾花数据集路径.csv",delimiter=',',dtype=np.float32)
self.x = torch.from_numpy(data[:,0:-1])
self.y = torch.from_numpy(data[:,[-1]])
self.len = data.shape[0]
def __getitem__(self, index):
return self.x[index],self.y[index]
def __len__(self):
return self.len
DataLoader
torch.utils.data.DataLoader
实现自定义数据集之后,就可以返回数据集样本了,但这种直接通过索引来返回样本的方式比较原始,无法让数据集一次提供一个批次(batch)的数据,也无法对数据进行随机置乱和并行加速。为此,PyTorch专门提供DataLoader类来实现这一功能。
DataLoader类是一个数据加载器,它将数据集和样本抽样器组合在一起,并提供给定数据集上的可迭代对象。
功能:构建可跌倒的数据装载器

- dataset:Dataset类,决定数据从哪读取及如何读取
- batchsize:批大小
- num_works:是否多进程读取数据
- shuffle:每个epoch是否乱序
- drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
Epoch:所有训练样本都一输入到模型中,称之为一个Epoch
Iteration:一批样本输入到模型中,称之为一个Iteration
Batchsize:批大小,决定一个Epoch有多少个Iteration
DataLoader类的简单示例
我们以读取上面构建的鸢尾花数据集为例
import torch
from torch.utils.data import DataLoader
from Dataset类重载鸢尾花数据集 import IrisDataset
# 实例化
iris = IrisDataset()
irir_loader = DataLoader(dataset=iris,batch_size=10,shuffle=True)
for epoch in range(2):
for i,data in enumerate(irir_loader): # Return an enumerate object.
# 从irir_loader中读取数据
inputs,labels = data
# 打印数据集
print(inputs.data.size())
print(labels.data.size())
数据读取的三个问题
1、读哪些数据?
训练用的数据
2、从哪读数据?
数据集中
3、怎么读数据?
通过os库对硬盘上的文件读取
if __name__ == '__main__':
random.seed(1)
dataset_dir = ps.path.join('..','data')
split_dir = ps.path.join('..','split')
train_dir = os.path.join(split_dir,'train')
valid_dir = os.path.join(split_dir,'valid')
test_dir = os.path.join(split_dir,'test')
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
构建MyDataset实例
train_data = MyDataset(data_dir=train_dir,transform=train_transform)
valid_data = MyDataset(data_dir=train_dir,transform=valid_transform)
构建DataLoder
train_loader = DataLoader(dataset=train_data,batch_size=tensor(32,32),shuffle=True)
valid_loader = DataLoader(dataset=valid_data,batch_size=tensor(32,32))