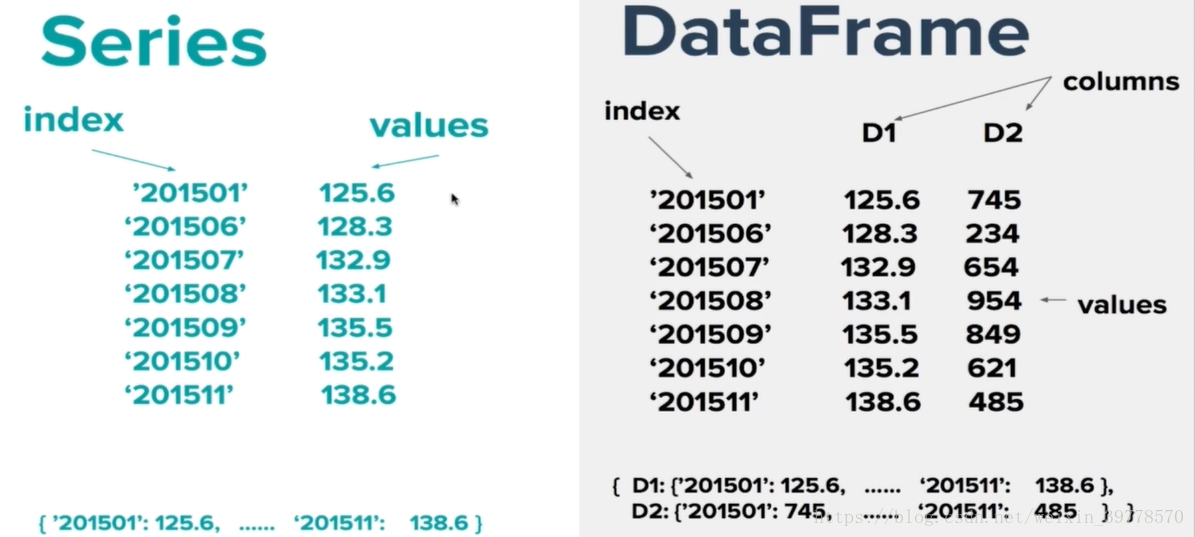
DataFrame和Series
# 导入需要的模块
>>> import pandas as pd >>> import numpy as np >>> from pandas import Series, DataFrame
# 首先创建一个字典
>>> data = {'Student':['XiaoMing','XiaoHong','XiaoWang'],'Grade':[100,90,20],'Class':['RG1','RG2','RG3']}
# 创建一个Series对象
>>> s1 = pd.Series(data['Student']) >>> s1 0 XiaoMing 1 XiaoHong 2 XiaoWang dtype: object
# 查看一下这个对象的属性
>>> s1.values array(['XiaoMing', 'XiaoHong', 'XiaoWang'], dtype=object)
# 当没有给索引赋值的时候默认为
>>> s1.index RangeIndex(start=0, stop=3, step=1)
# 创建并修改默认索引
>>> s1 = pd.Series(data['Student'], index = ['first','second','three']) >>> s1 first XiaoMing second XiaoHong three XiaoWang dtype: object
# 给它起个列名‘GDUF’
>>> s1 = pd.Series(data['Student'], index = ['first','second','three'], name = 'GDUF') >>> s1 first XiaoMing second XiaoHong three XiaoWang Name: GDUF, dtype: object # 注意:索引和列名是可以修改的,方式如下: >>> s1.name = 'haha' >>> s1.index = ['first','second','three']
# 使用字典创建DataFrame对象
>>> df1 = pd.DataFrame(data)
>>> df1
Student Grade Class
0 XiaoMing 100 RG1
1 XiaoHong 90 RG2
2 XiaoWang 20 RG3
# 查看DataFrame的属性
# 某一列 >>> cou = df1['Student'] >>> cou 0 XiaoMing 1 XiaoHong 2 XiaoWang Name: Student, dtype: object # Series是有名字的 # 列的类型为Series >>> type(cou) <class 'pandas.core.series.Series'> # 默认索引 >>> df1.index RangeIndex(start=0, stop=3, step=1)
# 查看某一列某一行 >>> c1 = df1['Student'][0] >>> c1 'XiaoMing' >>> type(c1) <class 'str'>
# 查看某一行的属性 >>> for row in df1.iterrows(): print(row), print(type(row)),print(type(row[0])), print(type(row[1])) break (0, Student XiaoLi Grade 100 Class RG1 Name: 0, dtype: object) # 每一行默认的名字为0 <class 'tuple'> # 每一行为一个tuple对象 <class 'int'> # 默认索引为int类型 <class 'pandas.core.series.Series'> # 值为Series类型 (None, None, None, None)# 通过Series构建DataFrame对象
>>> data
{'Student': ['XiaoMing', 'XiaoHong', 'XiaoWang'], 'Grade': [100, 90, 20], 'Class': ['RG1', 'RG2', 'RG3']}
>>> s1 = pd.Series(data['Student'])
>>> s2 = pd.Series(data['Grade'])
>>> s3 = pd.Series(data['Class'])
>>> df_new = pd.DataFrame([s1,s2,s3]) # 当以列表的形式构建的时候会按行来放,有时候可以优先选择按行放
>>> df_new
0 1 2
0 XiaoMing XiaoHong XiaoWang
1 100 90 20
2 RG1 RG2 RG3
>>> df_new.T # 进行行列转置
0 1 2
0 XiaoMing 100 RG1
1 XiaoHong 90 RG2
2 XiaoWang 20 RG3
# 修改索引(通过字典直接构建,修改索引)
>>> df_new = DataFrame(data)
>>> df_new
Student Grade Class
0 XiaoMing 100 RG1
1 XiaoHong 90 RG2
2 XiaoWang 20 RG3
>>> df_new.index = ['first', 'second', 'thrid']
>>> df_new
Student Grade Class
first XiaoMing 100 RG1
second XiaoHong 90 RG2
thrid XiaoWang 20 RG3
# 看一下这行代码# 构建Series对象的时候,同时指定索引,名字
>>> s1 = pd.Series(data['Student'], name = 'Student', index = ['one','two','three'])# 这样子DataFrame的结构就呼之欲出了,即列(colums),索引(index),值(values)
>>> df2 = pd.DataFrame(s1)
>>> df2
Student
one XiaoMing
two XiaoHong
three XiaoWang
>>> s1 = pd.Series(data['Student'], name = 'Student', index = ['one','two','three'])
>>> s2 = pd.Series(data['Grade'], name = 'Grade', index = ['one','two','three'])
>>> s3 = pd.Series(data['Class'], name = 'Class', index = ['one','two','three'])
>>> df2 = pd.DataFrame([s1,s2,s3])
>>> df2
>>> df2
one two three
Student XiaoMing XiaoHong XiaoWang
Grade 100 90 20
Class RG1 RG2 RG3
# 用列表构建是按行放置的,需要装置一下
>>> df2.T
Student Grade Class
one XiaoMing 100 RG1
two XiaoHong 90 RG2
three XiaoWang 20 RG3
# 下面这种也是一种比较直观的构建方式。但是比较繁琐 (字典中的值为Series)
>>> d = {'one': Series([1., 2., 3.], index=['a', 'b', 'c']), 'two': Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
>>> df = DataFrame(d)
>>> df
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
官网: http://pandas.pydata.org/pandas-docs/version/0.14.1/