入侵可以定义为任何类型的对信息系统造成损害的未经授权的活动。这意味着任何可能对信息机密性、完整性或可用性构成威胁的攻击都将被视为入侵。例如,使计算机服务对合法用户无响应的活动被视为入侵。 IDS 是一种软件或硬件系统,用于识别计算机系统上的恶意行为,以便维护系统安全。 IDS 的目标是识别传统防火墙无法识别的不同类型的恶意网络流量和计算机使用情况。这对于实现对损害计算机系统可用性、完整性或机密性的行为的高度保护至关重要。
总体上来说,IDS 系统可以大致分为两类:基于签名的入侵检测系统 (SIDS) 和基于异常的入侵检测系统 (AIDS),以下分别介绍:
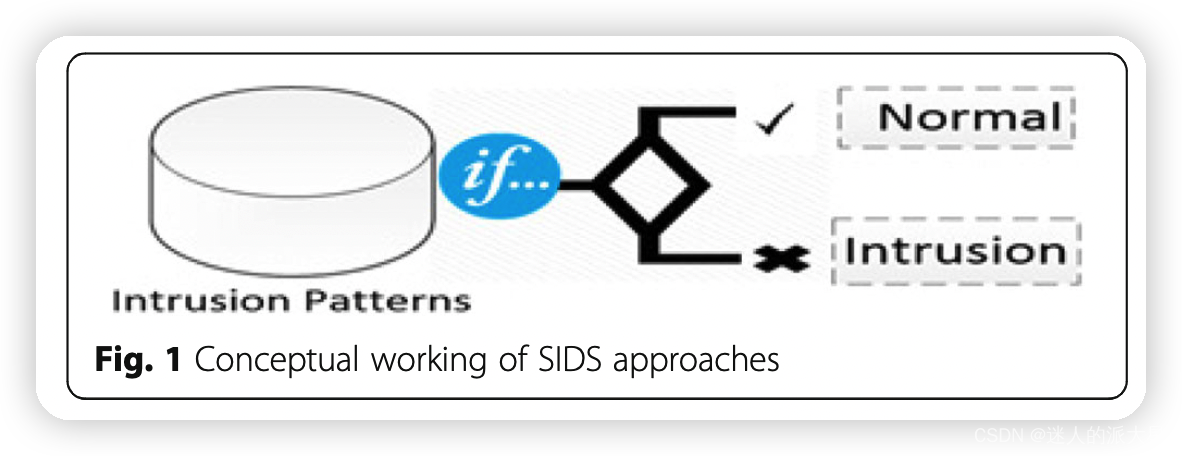
- 基于签名的入侵检测系统 (SIDS)。基于签名入侵检测系统 (SIDS) 是基于模式匹配技术来发现已知攻击,也被称为基于知识的检测或误用检测。在 SIDS 中,匹配方法用于查找先前的入侵。换言之,当入侵特征与特征数据库中已经存在的先前入侵的特征相匹配时,触发警报信号。对于 SIDS,检查主机的日志以查找先前被识别为恶意软件的命令或操作序列。 SIDS主要思想是建立一个入侵特征数据库,并将当前活动集与现有特征进行比较,如果发现匹配则发出警报。SIDS 通常对先前已知的入侵提供出色的检测精度。然而,SIDS 难以检测零日攻击,因为在提取和存储新攻击的签名之前,数据库中不存在匹配的签名。 SIDS 被用于许多常用工具,例如 Snort (Roesch, 1999) 和 NetSTAT (Vigna & Kemmerer, 1999)。 SIDS 的传统方法检查网络数据包并尝试与签名数据库进行匹配。但是这些技术无法识别跨越多个数据包的攻击。由于现代恶意软件更加复杂,可能有必要从多个数据包中提取签名信息。这需要 IDS 调用早期数据包的内容。关于为 SIDS 创建签名,通常有许多方法可以将签名创建为状态机 (Meiners et al., 2010)、正式语言字符串模式或语义条件 (Lin et al., 2011)。零日攻击(赛门铁克,2017 年)的频率越来越高,这使得 SIDS 技术的有效性逐渐降低,因为任何此类攻击都不存在先前的签名。恶意软件的多态变体和不断增加的针对性攻击可能会进一步破坏这种传统范式的充分性。SIDS的大体结构如图所示:
- 基于异常的入侵检测系统(AIDS)。AIDS由于能够克服SIDS的局限性而引起了许多学者的关注。在AIDS中,计算机系统行为的正常模型是使用机器学习、基于统计或基于知识的方法创建的。观察到的行为与正常模型之间的任何显着偏差都被视为异常,可以解释为入侵。这组技术的假设是恶意行为不同于典型的用户行为。异常用户的与标准行为不同的行为被归类为入侵。AIDS的发展包括两个阶段:训练阶段和测试阶段。在训练阶段,正常流量配置文件用于学习正常行为模型,然后在测试阶段,使用新数据集建立系统泛化到以前未见过的入侵的能力。AIDS可以根据训练的方法分为许多类别,例如,基于统计的、基于知识的和基于机器学习的(Butun et al., 2014)。 AIDS 的主要优点是能够识别零日攻击,因为识别异常用户活动不依赖于签名数据库(Alazab 等,2012)。当被检查的行为与通常的行为不同时,AIDS会触发危险信号。SIDS 只能识别已知的入侵,而 AIDS 可以检测零日攻击。然而,AIDS 可能导致高误报率,因为异常可能只是新的正常活动,而不是真正的入侵。
两种IDS的比较如下表:
| 方法 | 优点 | 缺点 |
|---|---|---|
| SIDS | 设计简单 | 需要经常更新签名 |
| 非常有效的识别入侵且误报率小 | 无法识别已知攻击的变体 | |
| 速度快 | 无法识别0-day攻击 | |
| 在检测已知攻击上具有优势 | 不适合检测多步攻击 | |
| AIDS | 可用于检测新的攻击 | AIDS无法处理加密数据包 |
| 可用于创建入侵签名 | 高误报率 | |
| 很难为动态的计算机系统建立保护 | ||
| 无法具体检测攻击类别 | ||
| 需要训练模型 |
根据IDS实现的方式,也可以分为以下五类:基于统计的、基于模式的、基于规则的、基于状态的和基于启发式的。大致比较如下:
| 检测方法 | 特点 |
|---|---|
| 基于统计:使用复杂的统计算法分析网络流量以处理信息 | 需要大量统计知识 |
| 简单但准确率不高 | |
| 实时 | |
| 基于模式:识别数据中的字符、形式和模式 | 实现简单 |
| 可以用Hash函数实现 | |
| 基于规则:使用攻击“签名”来检测对可疑网络流量的潜在攻击 | 因为需要模式匹配,计算成本可能比较高 |
| 需要大量的规则 | |
| 误报率低 | |
| 检出率高 | |
| 基于状态:检查事件流以识别任何可能的攻击 | 可以使用状态机实现自训练 |
| 误报率低 | |
| 基于启发式:识别异常活动 | 需要先验知识和经验 |
根据数据来源,还可以将IDS分为基于主机的IDS(HIDS)和基于网络的IDS(NIDS):
| 分类 | 优点 | 不足 | 数据源 |
|---|---|---|---|
| HIDS | HIDS 可以检查端到端的加密通信行为 | 延迟通常比较高 | 审核记录 |
| 不需要额外的硬件 | 消耗主机资源 | 日志文件 | |
| 通过检查主机文件系统、系统调用或网络事件来检测入侵 | 需要安装在每台主机上 | 应用程序接口 (API) | |
| 重组每个数据包 | 只能监视安装它的机器上的攻击 | 规则模式 | |
| 关注整体,而不是单个流 | 系统调用 | ||
| NIDS | 通过检查网络数据包检测攻击 | 需要专用硬件 | 简单网络管理协议(SNMP) |
| 不需要在每台主机上安装 | 仅支持识别网络层面的攻击 | 网络数据包(TCP/UDP/ICMP) | |
| 可以同时查看不同的主机 | 难以分析高速网络 | 管理信息库(MIB) | |
| 能够检测广泛的网络协议 | 路由器NetFlow记录 |
同样,根据AIDS的实现方式,可分为三类:基于统计的、基于知识的和机器学习方法。如下图:
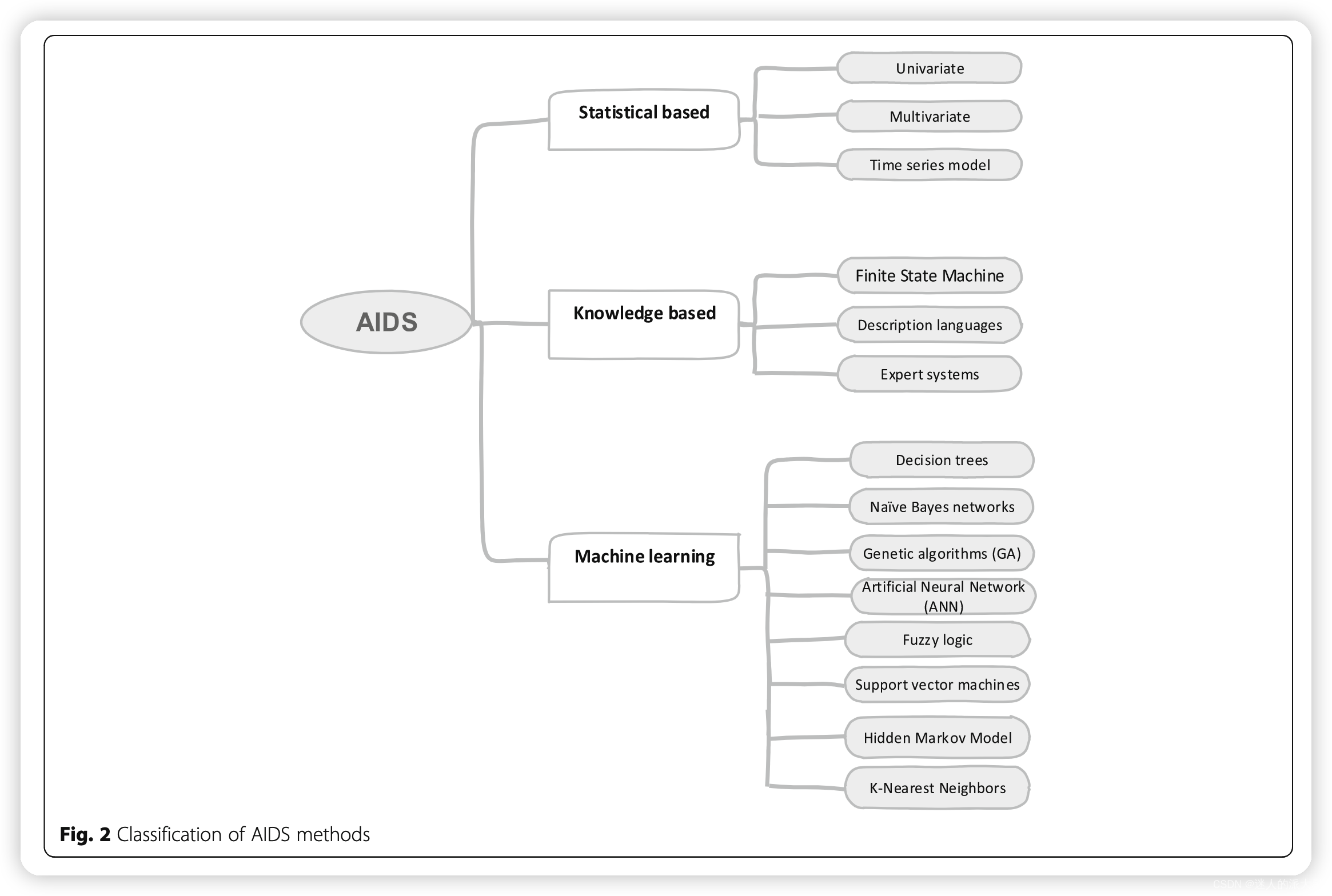
展开介绍如下:
- 基于统计的技术。基于统计的 IDS 为正常行为配置文件构建分布模型,然后检测低概率事件并将其标记为潜在入侵。统计 AIDS 本质上考虑了数据包的中位数、均值、众数和标准差等统计指标。换句话说,不是检查数据流量,而是监控每个数据包,用来表示流的指纹。统计 AIDS 用于识别当前行为与正常行为的任何类型的差异。
- 基于知识的技术。这组技术也称为专家系统方法。这种方法需要创建一个反映合法流量配置文件的知识库。与此标准配置文件不同的操作被视为入侵。与其他类型的 AIDS 不同,标准配置文件模型通常是根据人类知识创建的,根据一组试图定义正常系统活动的规则。基于知识的技术的主要好处是能够减少误报,因为系统了解所有正常行为。然而,在动态变化的计算环境中,这种 IDS 需要定期更新有关预期正常行为的知识,这是一项耗时的任务,因为收集有关所有正常行为的信息非常困难。
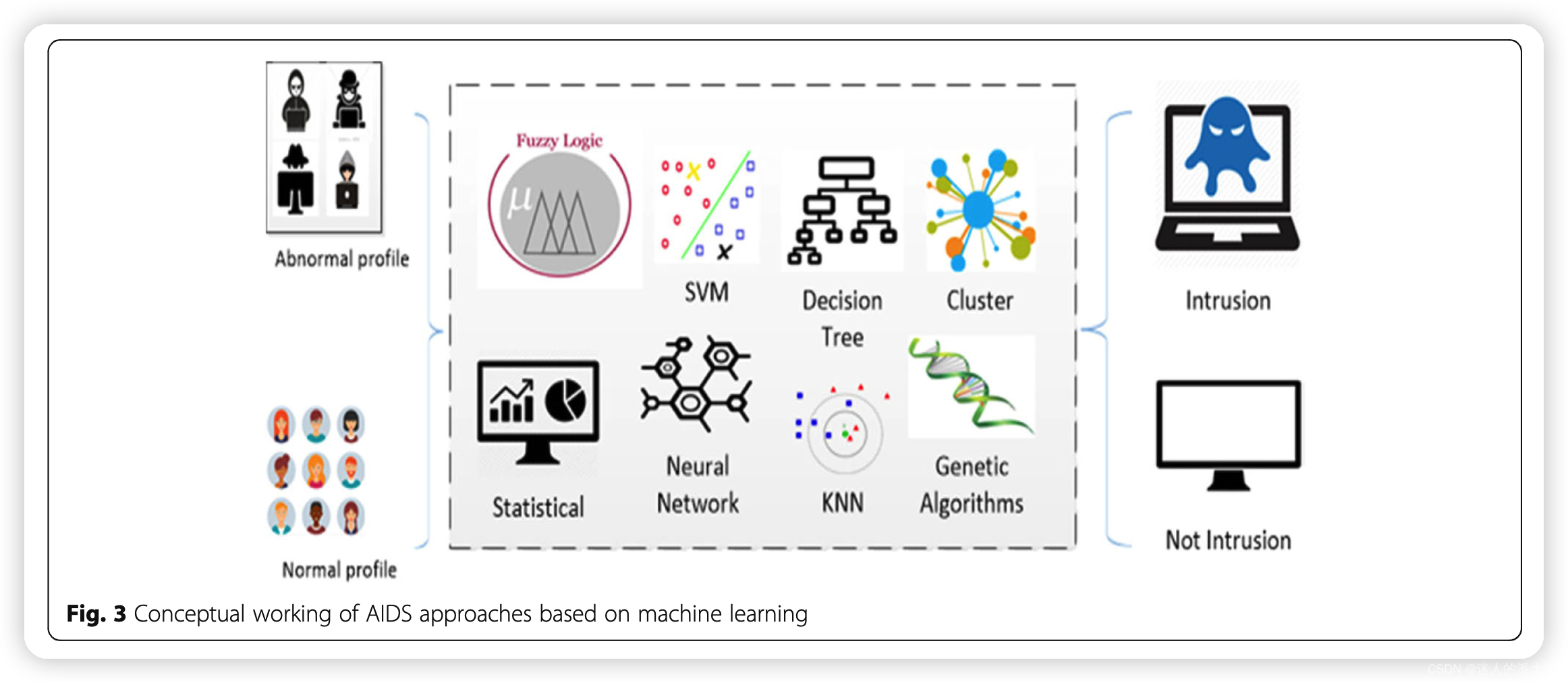
- 基于机器学习的技术。机器学习是从大量数据中提取知识的过程。机器学习模型包含一组规则、方法或复杂的“传递函数”,可用于发现有趣的数据模式,或识别或预测行为(Dua & Du,2016)。机器学习技术已广泛应用于AIDS领域。方法分类大致如图:
参考文献
Khraisat A, Gondal I, Vamplew P, et al. Survey of intrusion detection systems: techniques, datasets and challenges[J]. Cybersecurity, 2019, 2(1): 1-22.