自己学习过程中的一些记录,如有不正确的地方,恳请大家批评指正!
数据集格式转换
我下载的是VOC格式的数据集(MAR20),首先要把数据集转换成yolo可以用的格式。
合并xml文件
MAR20数据集一张图片对应两个xml文件,先将xml文件合并(由于本人水平有限,且所查阅的资料都是一个图片对应一个xml文件,所以先将两个xml文件合并,但是两个xml文件对应的是两种标注方式,是否可以合并存疑,希望有大神能解决我的困境),代码如下:
from xml.etree.ElementTree import ElementTree, Element, parse
import xml.etree.ElementTree as ET
import os
import shutil
hole_path = 'D:/ProgramData/code/datasets/MAR20/Annotations/Horizontal Bounding Boxes'
arm_path = 'D:/ProgramData/code/datasets/MAR20/Annotations/Oriented Bounding Boxes'
out_path = 'D:/ProgramData/code/datasets/MAR20/Annotations/xmlcombine'
# 格式化
def __indent(elem, level=0):
i = "\n" + level*"\t"
if len(elem):
if not elem.text or not elem.text.strip():
elem.text = i + "\t"
if not elem.tail or not elem.tail.strip():
elem.tail = i
for elem in elem:
__indent(elem, level+1)
if not elem.tail or not elem.tail.strip():
elem.tail = i
else:
if level and (not elem.tail or not elem.tail.strip()):
elem.tail = i
for hole_xml in os.listdir(hole_path):
# 将同名xml合并
if os.path.exists(os.path.join(arm_path,hole_xml)):
print('Horizontal Bounding Boxes',hole_xml)
tree_hole = parse(os.path.join(hole_path,hole_xml))
root_hole = tree_hole.getroot() # annotation
new_hole = tree_hole
tree_arm = parse(os.path.join(arm_path,hole_xml))
root_arm = tree_arm.getroot() # annotation
object = (tree_arm.findall('object'))
for i in range(len(object)):
root_hole.append(object[i])
__indent(root_hole)
new_hole.write(os.path.join(out_path,hole_xml))
#不同名xml复制
else:
print('copying',hole_xml)
shutil.copy(os.path.join(hole_path,hole_xml), out_path)
# 将不同名xml复制
for arm_xml in os.listdir(arm_path):
if not os.path.exists(os.path.join(out_path,arm_xml)):
print('copying')
shutil.copy(os.path.join(arm_path, arm_xml), out_path2.xml转换txt
在数据集根目录下新建一个labels文件夹,用来存放xml文件转换成txt格式的文件。具体操作如下:
在pycharm项目的根目录下新建一个txt_write.py文件,用来划分数据集,代码如下:
# -*- coding: utf-8 -*-
"""
分训练集、验证集和测试集,按照 8:1:1 的比例来分,训练集8,验证集1,测试集1
"""
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='D:/ProgramData/code/datasets/MAR20/Annotations/Horizontal Oriented Bounding Boxes', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='D:/ProgramData/code/datasets/MAR20/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
train_percent = 0.8 # 训练集所占比例
val_percent = 0.1 # 验证集所占比例
test_persent = 0.1 # 测试集所占比例
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list = list(range(num))
t_train = int(num * train_percent)
t_val = int(num * val_percent)
train = random.sample(list, t_train)
num1 = len(train)
for i in range(num1):
list.remove(train[i])
val_test = [i for i in list if not i in train]
val = random.sample(val_test, t_val)
num2 = len(val)
for i in range(num2):
list.remove(val[i])
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
for i in train:
name = total_xml[i][:-4] + '\n'
file_train.write(name)
for i in val:
name = total_xml[i][:-4] + '\n'
file_val.write(name)
for i in list:
name = total_xml[i][:-4] + '\n'
file_test.write(name)
file_train.close()
file_val.close()
file_test.close()将xml文件转成txt格式,生成训练集、验证集和测试集的txt,txt记录的是图片的路径
# *coding:utf-8 *
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import cv2
sets = ['train', 'test','val']
#数据集类别
classes = ['A1','A2','A3','A4','A5','A6','A7','A8','A9','A10','A11','A12','A13','A14','A15','A16','A17','A18','A19','A20' ]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
# in_file = open('D:/yolov7-main/voc2007/Annotations/%s.xml' % (image_id)) # 修改路径(最好使用全路径)
# img_file = cv2.imread('JILI_NB\images\%s.jpg' % (image_id))
# out_file = open('JILI_NB\labels/%s.txt' % (image_id), 'w+') # 修改路径(最好使用全路径)
in_file = open('D:/ProgramData/code/datasets/MAR20/Annotations/Horizontal Oriented Bounding Boxes/%s.xml' % (image_id)) # 修改路径(最好使用全路径)
img_file = cv2.imread('D:/ProgramData/code/datasets/MAR20/JPEGImages/%s.jpg' % (image_id))
out_file = open('D:/ProgramData/code/datasets/MAR20/Labels/%s.txt' % (image_id), 'w+') # 修改路径(最好使用全路径)
tree = ET.parse(in_file)
root = tree.getroot()
# size = root.find('size')
assert img_file is not None
size = img_file.shape[0:-1]
h = int(size[0])
w = int(size[1])
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes : # or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
ZIP_ONE = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in ZIP_ONE]) + '\n')
wd = getcwd()
for image_set in sets:
# if not os.path.exists('JILI_NB/labels'):
# os.makedirs('JILI_NB/labels/')
if not os.path.exists('D:/ProgramData/code/datasets/MAR20/Labels'):
os.makedirs('D:/ProgramData/code/datasets/MAR20/Labels')
image_ids = open('D:/ProgramData/code/datasets/MAR20/ImageSets/Main/%s.txt' % (image_set)).read().split() # 修改路径(最好使用全路径)
list_file = open('D:/ProgramData/code/datasets/MAR20/Labels%s.txt' % (image_set), 'w+') # 修改路径(最好使用全路径)
# print(image_ids)
for image_id in image_ids:
try:
print(image_id)
list_file.write('D:/ProgramData/code/datasets/MAR20/JPEGImages/%s.jpg\n' % (image_id)) # 修改路径(最好使用全路径)
convert_annotation(image_id)
except:
print('error img:', image_id)
list_file.close()3.更改文件夹结构
上边操作完成之后,数据集的文件格式就没有问题啦,下面需要更改文件夹结构
进行上述操作之后文件夹结构如下,需要进一步更改
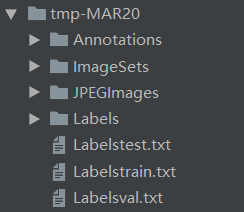
更改为下图所示,代码如下:(这里注意一下,shutil.copy()调用的是txt文件中的路径,本人由于生成的txt为图片名称,非路径,下列代码运行时总报找不到文件的错,花了一天时间才发现问题。针对该问题加了一段代码,将路径写进txt文件之后可以正常运行了)
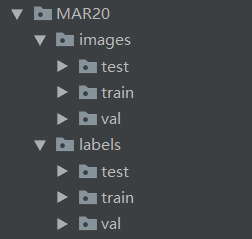
import shutil
import os
file_List = ["test", "val","train" ]
for file in file_List:
if not os.path.exists('D:/ProgramData/code/yolov5-master/MAR20/images/%s' % file):
os.makedirs('D:/ProgramData/code/yolov5-master/MAR20/images/%s' % file)
if not os.path.exists('D:/ProgramData/code/yolov5-master/MAR20/labels/%s' % file):
os.makedirs('D:/ProgramData/code/yolov5-master/MAR20/labels/%s' % file)
print(os.path.exists('../tmp/ImageSets/Main/%s.txt' % file))
f = open('../tmp/ImageSets/Main/%s.txt' % file, 'r')
lines = f.readlines()
'''
#将路径写进txt文件,如果生成的txt文件为图片路径则不需要
f.seek(0)
f.truncate() # 先将原来文件进行清空
for line_list in lines: # 对于原来文件的内容每一行进行添加的操作
line_list = line_list.replace("\n", "")
line_new ="D:\ProgramData\code\yolov5-master\tmp\JPEGImages\" + line_list + ".jpg "+"\n"
f.write(line_new)
f.close()
'''
for line in lines:
print(line)
line = "/".join(line.split('/')[-5:]).strip()
shutil.copy(line, "../MAR20/images/%s" % file)
#shutil.copyfile(line, "../MAR20/images/%s" % file)
#shutil.copymode(line, "../MAR20/images/%s" % file)
line = line.replace('JPEGImages', 'Labels')
line = line.replace('jpg', 'txt')
shutil.copy(line, "../MAR20/labels/%s/" % file)到这数据集转换就全部完成啦!
配置文件
4.在pycharm项目的同级文件夹中新建一个datastes文件夹
datasets文件夹用来放数据集,将生成的数据集文件夹放在datasets文件夹中,接下来开始配置文件吧
首先,新建一个项目目录下的data文件夹里新建一个airplane.yaml文件
train: D:\ProgramData\code\datasets\MAR20\images\train
val: D:\ProgramData\code\datasets\MAR20\images\val
test: D:\ProgramData\code\datasets\MAR20\images\test
nc: 20 #有多少个类
#类别名称
names: ['A1','A2','A3','A4','A5','A6','A7','A8','A9','A10','A11','A12','A13','A14','A15','A16','A17','A18','A19','A20']接着,修改项目根目录下的train.py文件
#yolov5有smlx四个模型,选择哪个模型设置哪个模型路径(所有的路径都最好是全路径,不用ROOT代替)
parser.add_argument('--cfg', type=str, default='D:/ProgramData/code/yolov5-master/models/yolov5s.yaml', help='model.yaml path')
#调用自己设置的yaml文件
parser.add_argument('--data', type=str, default= 'D:/ProgramData/code/yolov5-master/data/airplane.yaml', help='dataset.yaml path')这些完成后就可以开始训练啦。
扩展:epochs:训练几轮,默认100,可以根据需要更改。
batch-size:每次训练选取的样本数,比如说我有3073个样本,batch-size=16,那么我每次训练的样本数为193。