文章目录
一、提出任务
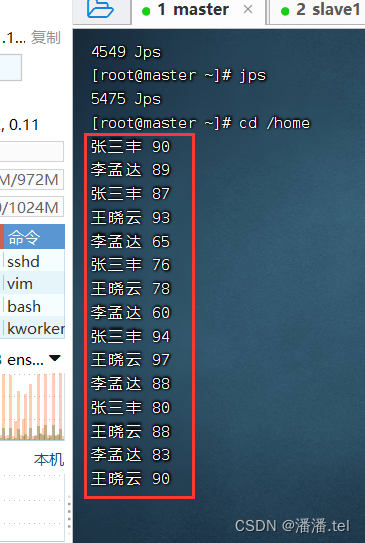
学生数据:
张三丰 90
李孟达 85
张三丰 87
王晓云 93
李孟达 65
张三丰 76
王晓云 78
李孟达 60
张三丰 94
王晓云 97
李孟达 88
张三丰 80
王晓云 88
李孟达 82
王晓云 98
预备工作:启动集群的HDFS与Spark
将成绩文件-grades.txt上传到HDFS上/input目录
二、完成任务
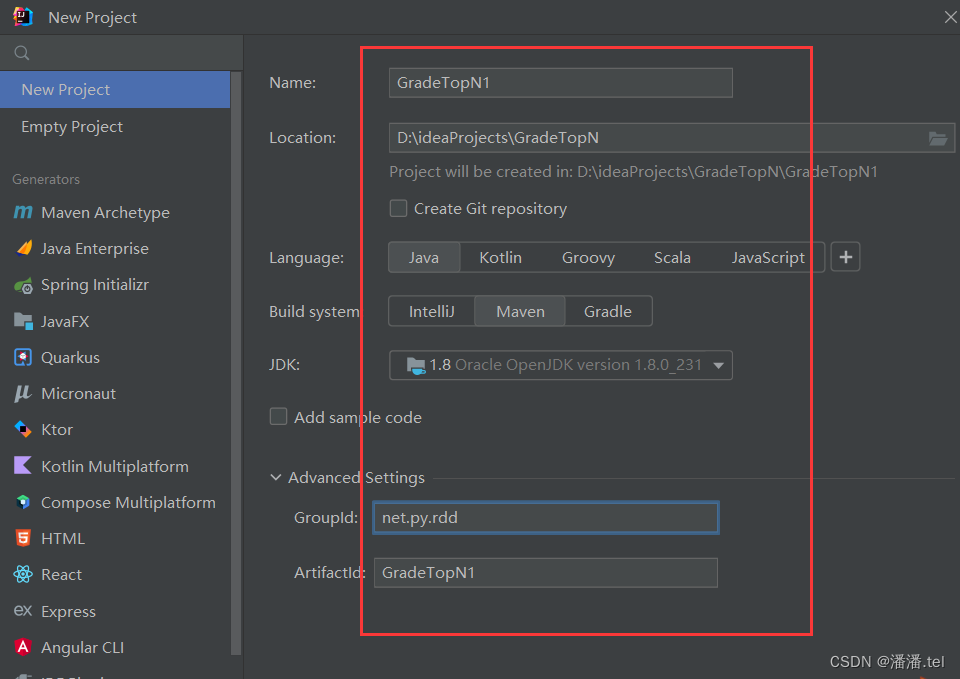
(一)新建Maven项目
(二)添加相关依赖和构建插件
(三)创建日志属性文件
(四)创建分组排行榜单例对象
(五)本地运行程序,查看结果
(六)交互式操作查看中间结果
1、读取成绩文件得到RDD
scala> val lines = sc.textFile("hdfs://master:9000/input/grades.txt")
lines:org.apache.spark.rdd.RDD[String] = hdfs://master:9000/input/grades.txt MapPartitons RDD[1] at textFile at <console>:24
scala>lines.collect.foreach(println)
张三丰 90
李孟达 85
张三丰 87
王晓云 93
李孟达 65
张三丰 76
王晓云 78
李孟达 60
张三丰 94
王晓云 78
李孟达 88
王晓云 97
李孟达 88
张三丰 80
王晓云 88
李孟达 82
王晓云 98
2、利用映射算子生成二元组构成的RDD
scala> :paste
//Entering paste mode(ctrl-D to finish)
val grades = lines.map(line => {
val fields= line.split( " " )
(fields(0),fields(1))
})
grades:org.apache.spark.rdd.RDD[(String,String)] = MapartitonsRDD[3] at map at <pastie>:25
scala> grades.collect.foreach(println)
(张三丰, 90)
(李孟达 ,85)
(张三丰 ,87)
(王晓云 ,93)
(李孟达 ,65)
(张三丰 ,76)
(王晓云 ,78)
(李孟达 ,60)
(张三丰 ,94)
3、按键分组得到新的二元组构成的RDD
scala>val groupGrades = grades.groupByKey()
groupGrades: org.apache.spark.rdd.RDD[(Sting, Iterable[String[)] = ShullfeldRDD[4] at group ByKey at <console>:25
scala> groupGrades.collect.foreach(println)
(李孟达,CompactBuffer(85,65,60,88,82)
(王晓云,CompactBuffer(93,78,97,88,98)
(张三丰,CompactBuffer(90,87,76,94,80)
4、按值排序,取前三
scala> :paste
//Entering paste mode (ctrl -D to finish)
val top3 = groupGrades.map(item => {
val name = item._1
val top3 = item._2.toList.sortWith(_ > _).take(3)
(name, top3)
})
//Exiting paste mode, now inerpreting.
top3:org.apache.spark.rdd.RDD[(String,List[String])] = MapartitionsRDD[5] at map at <pastie>:25
scala > top3.collect.foreach(println)
(李孟达,List(88,85,82))
(王晓云,List(98,97,93))
(张三丰,List(94,90,87))
5、按指定格式输出结果
scala> :paste
//Entering paste mode (ctrl-D to finish)
top3.collect.foreach(line => {
top3.collect.foreach(line => {
val name = line._1
var scores = ""
for (score <- line._2)
scores = scores + " " + score
println(name + ":" + scores)
})
//Exiting paste mode, now interpreting.
李孟达:88 85 82
王晓云:98 97 93
张三丰:94 90 87