前言
由于业务要求,我需要将104协议的报文内容解析后传到kafka里,然后程序也是一个SpringBoot项目,所以本篇文章我想说一说我是如何将那些数据传到kafka中并判断其是否消费,至于104协议的报文内容的解析和通信在此不去介绍,涉及到netty的知识。
主要讲生产者怎么发送到kafka,以及用命令来判断消息消费下来了,然后将消费后的数据利用反射机制来将数据保存到mysql中
步骤
1、安装kafka
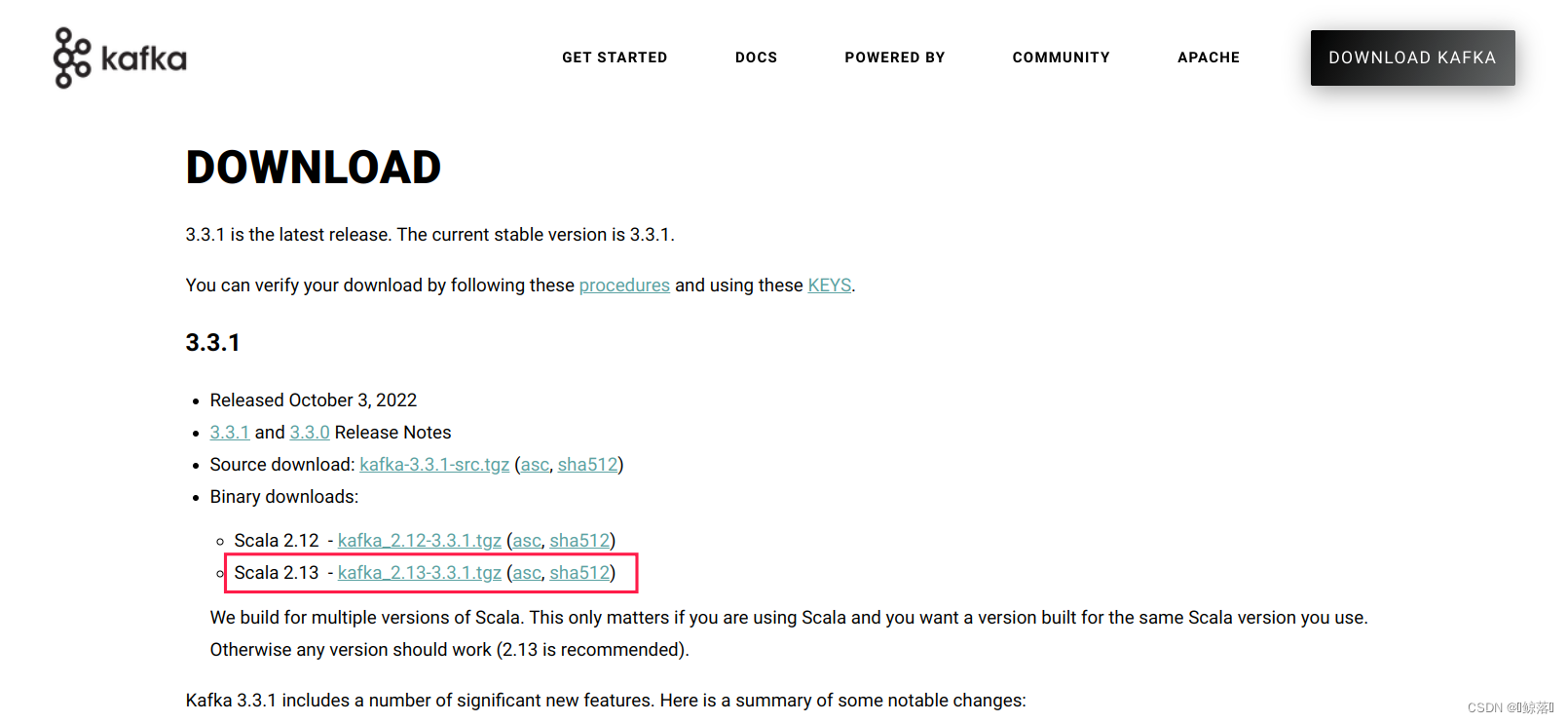
解压安装包
tar -zxvf kafka_2.13-3.3.1.tgz -C /opt/module/
修改解压后的文件名称
mv kafka_2.13-3.3.1/ kafka
修改server.properties 和 zookeeper.properties 配置文件
cd config/
server.properties :


其中zookeeper.connect 的地址名字按需求而定
zookeeper.properties:
配置环境变量
vim etc/profile
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
刷新一下环境变量
source /etc/profile
然后重点,先启动zookeeper再启动kafka (要在kafka目录下输入命令)
#启动zookeeper服务
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
#启动kafka服务
bin/kafka-server-start.sh -daemon config/server.properties
2、导入kafka的依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.5.14.RELEASE</version>
</dependency>
3、配置yml文件
server:
port: 8082
# 数据库数据源
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://...:3306/abc
username: root
password: root
kafka:
producer:
bootstrap-servers: 127.0.0.1:9092
retries: 3
acks: all
max-block-ms: 6000
batch-size: 4096
linger-ms: 1000
buffer-memory: 33554432
max-request-size: 1048576
client-id: 自定义名字
compression-type: gzip
consumer:
bootstrap-servers: 127.0.0.1:9092
enable-auto-commit: true
auto-commit-interval-ms: 1000
max-poll-records: 100
group-id: 自定义名字
session-timeout-ms: 120000
request-timeout-ms: 120000
auto-offset-reset: latest
5、编写生产者配置类
用于启动项目后加载配置文件里的参数建立一个生产者服务
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaProducerConfiguration {
@Value("${kafka.producer.bootstrap-servers}")
private String bootstrapServers;
@Value("${kafka.producer.retries}")
private Integer retries;
@Value("${kafka.producer.acks}")
private String acks;
@Value("${kafka.producer.max-block-ms}")
private Integer maxBlockMs;
@Value("${kafka.producer.batch-size}")
private Integer batchSize;
@Value("${kafka.producer.linger-ms}")
private Integer lingerMs;
@Value("${kafka.producer.buffer-memory}")
private Integer bufferMemory;
@Value("${kafka.producer.max-request-size}")
private Integer maxRequestSize;
@Value("${kafka.producer.client-id}")
private String clientId;
@Value("${kafka.producer.compression-type}")
private String compressionType;
/**
* 不包含事务 producerFactory
* @return
*/
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> props = new HashMap<>();
//kafka 集群地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
//重试次数
props.put(ProducerConfig.RETRIES_CONFIG, retries);
//应答级别
//acks=0 把消息发送到kafka就认为发送成功
//acks=1 把消息发送到kafka leader分区,并且写入磁盘就认为发送成功
//acks=all 把消息发送到kafka leader分区,并且leader分区的副本follower对消息进行了同步就任务发送成功
props.put(ProducerConfig.ACKS_CONFIG, acks);
//KafkaProducer.send() 和 partitionsFor() 方法的最长阻塞时间 单位 ms
props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, maxBlockMs);
//批量处理的最大大小 单位 byte
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
//发送延时,当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
props.put(ProducerConfig.LINGER_MS_CONFIG, lingerMs);
//生产者可用缓冲区的最大值 单位 byte
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
//每条消息最大的大小
props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, maxRequestSize);
//客户端ID
props.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
//Key 序列化方式
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//Value 序列化方式
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//消息压缩:none、lz4、gzip、snappy,默认为 none。
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, compressionType);
//自定义分区器
// props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class.getName());
return new DefaultKafkaProducerFactory<>(props);
}
/**
* 包含事务 producerFactory
* @return
*/
public ProducerFactory<String, String> producerFactoryWithTransaction() {
DefaultKafkaProducerFactory<String, String> defaultKafkaProducerFactory = (DefaultKafkaProducerFactory<String, String>) producerFactory();
//设置事务Id前缀
defaultKafkaProducerFactory.setTransactionIdPrefix("tx");
return defaultKafkaProducerFactory;
}
/**
* 不包含事务 kafkaTemplate
* @return
*/
@Bean("kafkaTemplateWithNoTransaction")
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
/**
* 包含事务 kafkaTemplate
* @return
*/
@Bean
public KafkaTemplate<String, String> kafkaTemplateWithTransaction() {
return new KafkaTemplate<>(producerFactoryWithTransaction());
}
/**
* 以该方式配置事务管理器:就不能以普通方式发送消息,只能通过 kafkaTemplate.executeInTransaction 或
* 在方法上加 @Transactional 注解来发送消息,否则报错
* @param producerFactory
* @return
*/
// @Bean
// public KafkaTransactionManager<Integer, String> kafkaTransactionManager(ProducerFactory<Integer, String> producerFactory) {
// return new KafkaTransactionManager<>(producerFactory);
// }
}
4、编写生产者
用来编写发送消息的方法和启动项目后初始化创造一个MessageProducer,以便其他地方可以调用它,来发送消息
package com.axinite.iec104.kafka.producer;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.common.errors.TimeoutException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.kafka.core.KafkaOperations;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.kafka.support.SendResult;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import javax.annotation.PostConstruct;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
@Service
@Slf4j
public class MessageProducer {
@Qualifier("kafkaTemplateWithNoTransaction")
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Qualifier("kafkaTemplateWithTransaction")
@Autowired
private KafkaTemplate<String, String> kafkaTemplateWithTransaction;
public static IotMessageProducer messageProducer;
public static KafkaTemplate<String, String> staticKafkaTemplate;
@PostConstruct
public void init(){
messageProducer = new IotMessageProducer();
staticKafkaTemplate = this.kafkaTemplate;
}
/**
* 发送消息(同步)
* @param topic 主题
* @param key 键
* @param message 值
*/
public void sendMessageSync(String topic, String key, String message) throws InterruptedException, ExecutionException, TimeoutException, java.util.concurrent.TimeoutException {
//可以指定最长等待时间,也可以不指定
staticKafkaTemplate.send(topic, message).get(10, TimeUnit.SECONDS);
log.info("sendMessageSync => topic: {}, key: {}, message: {}", topic, key, message);
}
/**
* 发送消息并获取结果
* @param topic
* @param message
* @throws ExecutionException
* @throws InterruptedException
*/
public void sendMessageGetResult(String topic, String key, String message) throws ExecutionException, InterruptedException {
SendResult<String, String> result = staticKafkaTemplate.send(topic, key, message).get();
log.info("sendMessageSync => topic: {}, key: {}, message: {}", topic, key, message);
log.info("The partition the message was sent to: " + result.getRecordMetadata().partition());
}
/**
* 发送消息(异步)
* @param topic 主题
* @param message 消息内容
*/
public void sendMessageAsync(String topic, String message) {
ListenableFuture<SendResult<String, String>> future = staticKafkaTemplate.send(topic, message);
//添加回调
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.error("sendMessageAsync failure! topic : {}, message: {}", topic, message);
}
@Override
public void onSuccess(SendResult<String, String> stringStringSendResult) {
log.info("sendMessageAsync success! topic: {}, message: {}", topic, message);
}
});
}
/**
* 可以将消息组装成 Message 对象和 ProducerRecord 对象发送
* @param topic
* @param key
* @param message
* @throws InterruptedException
* @throws ExecutionException
* @throws TimeoutException
*/
public void testMessageBuilder(String topic, String key, String message) throws InterruptedException, ExecutionException, TimeoutException {
// 组装消息
Message msg = MessageBuilder.withPayload(message)
.setHeader(KafkaHeaders.MESSAGE_KEY, key)
.setHeader(KafkaHeaders.TOPIC, topic)
.setHeader(KafkaHeaders.PREFIX,"kafka_")
.build();
//同步发送
staticKafkaTemplate.send(msg).get();
}
/**
* 以事务方式发送消息
* @param topic
* @param key
* @param message
*/
public void sendMessageInTransaction(String topic, String key, String message) {
kafkaTemplateWithTransaction.executeInTransaction(new KafkaOperations.OperationsCallback<String, String, Object>() {
@Override
public Object doInOperations(KafkaOperations<String, String> kafkaOperations) {
kafkaOperations.send(topic, key, message);
//出现异常将会中断事务,消息不会发送出去
throw new RuntimeException("exception");
}
});
}
}
我这里使用@PostConstruct初始化是为了启动启动类后,先加载并初始化,由于我项目需要做netty的服务端通信,那么启动后会调用客户端的run方法,如下:
@Component
public class Iec104TcpServerSlaveTest implements ApplicationRunner{
/**
*
* @Title: test
* @Description: 测试 iec104 协议TCP传输方式服务端做从机服务
* @param @throws Exception
* @return void
* @throws
*/
@Override
public void run(ApplicationArguments args) throws Exception {
System.out.println("我启动了没?");
Iec104Config iec104Config = new Iec104Config();
iec104Config.setFrameAmountMax((short) 1);
iec104Config.setTerminnalAddress((short) 1);
Iec104SlaveFactory.createTcpServerSlave(2404).setDataHandler(new SysDataHandler()).setConfig(iec104Config).run();
Thread.sleep(1000000);
}
}
因为接口实现了ApplicationRunner接口,那么启动类启动后最后会运行这个run方法去启动服务端,运行后它会执行里面的Check104Handler去检查104报文,那么我如何去使用这个MessageProducer将报文解析后的数据传到kafka? 就需要将在Check104Handler引入它,但是我试了使用@Autowired会找不到这个MessageProducer,不知原因是什么,我认为大概是由于这个run方法没执行完毕,注入不了这个MessageProducer,因为服务端一直在跑,这个run方法执行时调用Check104Handler中还没有注入不这个MessageProducer。所以由于不能使用@Autowired,我使用了@PostConstruct提前加载注入到容器并初始化,以下是它的使用:
package com.axinite.iec104.server.handler;
import cn.hutool.json.JSONArray;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.axinite.iec104.analysis.protocol104.Analysis;
import com.axinite.iec104.common.Iec104Constant;
import com.axinite.iec104.enums.EmsEnergyEnum;
import com.axinite.iec104.enums.MobileEnergyEnum;
import com.axinite.iec104.kafka.producer.MessageProducer;
import com.axinite.iec104.util.ByteUtil;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelInboundHandlerAdapter;
import io.netty.util.ReferenceCountUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.util.LinkedHashMap;
import static io.netty.buffer.ByteBufUtil.appendPrettyHexDump;
import static io.netty.util.internal.StringUtil.NEWLINE;
/**
*
* @ClassName: Check104Handler
* @Description: 检查104报文
*/
@Component
public class Check104Handler extends ChannelInboundHandlerAdapter {
private static final Logger LOGGER = LoggerFactory.getLogger(ChannelInboundHandlerAdapter.class);
/**
* 拦截系统消息
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf result = (ByteBuf) msg;
// log(result);
byte[] bytes = new byte[result.readableBytes()];
result.readBytes(bytes);
LOGGER.info("接收到的报文: " + ByteUtil.byteArrayToHexString(bytes));
String content = ByteUtil.byteArrayToHexString(bytes);
String aa = Analysis.analysis(content);
LOGGER.info("------------报文详细信息------------");
System.out.println(aa);
MessageProducer.messageProducer.sendMessageGetResult(EmsEnergyConstants.KAFKA_EMS_INFO,"test", aa);
}
if (bytes.length < Iec104Constant.APCI_LENGTH || bytes[0] != Iec104Constant.HEAD_DATA) {
LOGGER.error("报文无效");
ReferenceCountUtil.release(result);
} else {
result.writeBytes(bytes);
ctx.fireChannelRead(msg);
}
}
public static void log(ByteBuf buffer) {
int length = buffer.readableBytes();
int rows = length / 16 + (length % 15 == 0 ? 0 : 1) + 4;
StringBuilder buf = new StringBuilder(rows * 80 * 2)
.append("read index:").append(buffer.readerIndex())
.append(" write index:").append(buffer.writerIndex())
.append(" capacity:").append(buffer.capacity())
.append(NEWLINE);
appendPrettyHexDump(buf, buffer);
System.out.println(buf.toString());
}
}
主要代码:
MessageProducer.messageProducer.sendMessageGetResult("test","test", aa);
5、启动完程序,使用命令去检查数据是否消费下来
注意: 启动程序的前提是,你本地已经先启动了zookeeper,然后再启动了kafka,如下命令(注意它的先后顺序,zookeeper先,kafka后)
在kafka的根目录下输入以下命令
#在kafka的根目录下输入以下命令
#启动zookeeper服务 (先开启zk,再开kafka)
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
#启动kafka服务
bin/kafka-server-start.sh -daemon config/server.properties
然后启动consumer服务去查看你的topic
#启动consumer服务
bin/kafka-console-consumer.sh --bootstrap-server ip:port --topic test
数据内容我就不放了
6、将消费的数据入库
1、编写消费者配置类
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.ConsumerAwareListenerErrorHandler;
import org.springframework.kafka.listener.ListenerExecutionFailedException;
import org.springframework.messaging.Message;
import java.util.HashMap;
import java.util.Map;
@Slf4j
@Configuration
public class KafkaConsumerConfiguration {
@Value("${kafka.consumer.bootstrap-servers}")
private String bootstrapServers;
@Value("${kafka.consumer.enable-auto-commit}")
private Boolean enableAutoCommit;
@Value("${kafka.consumer.auto-commit-interval-ms}")
private Integer autoCommitIntervalMs;
@Value("${kafka.consumer.max-poll-records}")
private Integer maxPollRecords;
@Value("${kafka.consumer.group-id}")
private String groupId;
@Value("${kafka.consumer.session-timeout-ms}")
private Integer sessionTimeoutMs;
@Value("${kafka.consumer.request-timeout-ms}")
private Integer requestTimeoutMs;
@Value("${kafka.consumer.auto-offset-reset}")
private String autoOffsetReset;
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
//设置 consumerFactory
factory.setConsumerFactory(consumerFactory());
//设置是否开启批量监听
factory.setBatchListener(false);
//设置消费者组中的线程数量
factory.setConcurrency(1);
return factory;
}
/**
* consumerFactory
* @return
*/
public ConsumerFactory<String, Object> consumerFactory() {
Map<String, Object> props = new HashMap<>();
//kafka集群地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
//自动提交 offset 默认 true
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
//自动提交的频率 单位 ms
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitIntervalMs);
//批量消费最大数量
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecords);
//消费者组
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
//session超时,超过这个时间consumer没有发送心跳,就会触发rebalance操作
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeoutMs);
//请求超时
props.put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, requestTimeoutMs);
//Key 反序列化类
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//Value 反序列化类
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//当kafka中没有初始offset或offset超出范围时将自动重置offset
//earliest:重置为分区中最小的offset
//latest:重置为分区中最新的offset(消费分区中新产生的数据)
//none:只要有一个分区不存在已提交的offset,就抛出异常
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
//设置Consumer拦截器
// props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, MyConsumerInterceptor.class.getName());
return new DefaultKafkaConsumerFactory<>(props);
}
/**
* 消费异常处理器
* @return
*/
@Bean
public ConsumerAwareListenerErrorHandler consumerAwareListenerErrorHandler() {
return new ConsumerAwareListenerErrorHandler() {
@Override
public Object handleError(Message<?> message, ListenerExecutionFailedException exception, Consumer<?, ?> consumer) {
//打印消费异常的消息和异常信息
log.error("consumer failed! message: {}, exceptionMsg: {}, groupId: {}", message, exception.getMessage(), exception.getGroupId());
return null;
}
};
}
}
2、编写监听主题消费入库的方法
import com.cspg.kafka.domain.constants.EmsEnergyConstants;
import com.cspg.kafka.service.ems.EmsEnergyInfoService;
import com.cspg.kafka.service.ems.EmsEnergyTelemeterStatusService;
import com.cspg.kafka.service.ems.EmsEnergyTelesignStatusService;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
@Slf4j
public class EmsEnergyConsumer {
@Autowired
private EmsEnergyInfoService emsEnergyInfoService;
@Autowired
private EmsEnergyTelesignStatusService telesignStatusService;
@Autowired
private EmsEnergyTelemeterStatusService telemeterStatusService;
/**
* 配网自动化系统基本信息
* @param record
*/
@KafkaListener(topics = EmsEnergyConstants.KAFKA_EMS_INFO)
@SneakyThrows
public void consumerEmsInfo(ConsumerRecord<String, String> record) {
log.info("kafka消费,配网自动化系统基本信息:"+record.topic()+"-"+record.partition()+"-"+record.value());
emsEnergyInfoService.saveEmsInfo(record.value());
log.info("配网自动化系统基本信息,消费结束");
}
/**
* 配网自动化系统遥信信息
* @param record
*/
@KafkaListener(topics = EmsEnergyConstants.KAFKA_EMS_Telesign_STATUS)
@SneakyThrows
public void consumerEmsEnergyTelesignStatus(ConsumerRecord<String, String> record) {
log.info("kafka消费,配网自动化系统遥信信息:"+record.topic()+"-"+record.partition()+"-"+record.value());
telesignStatusService.saveTelesignStatus(record.value());
log.info("配网自动化系统遥信信息,消费结束");
}
/**
* 配网自动化系统遥测信息
* @param record
*/
@KafkaListener(topics = EmsEnergyConstants.KAFKA_EMS_Telemeter_STATUS)
@SneakyThrows
public void consumerEmsEnergyTelemeterStatus(ConsumerRecord<String, String> record) {
log.info("kafka消费,配网自动化系统遥测信息:"+record.topic()+"-"+record.partition()+"-"+record.value());
telemeterStatusService.saveTelemeterStatus(record.value());
log.info("配网自动化系统遥测信息,消费结束");
}
}
其中@KafkaListener(topics = EmsEnergyConstants.KAFKA_EMS_Telemeter_STATUS)是指定topic的名字
3、反射入库
@Repository
public interface EmsEnergyInfoMapper extends BaseMapper<EmsEnergyInfo> {
}
import cn.hutool.core.date.LocalDateTimeUtil;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.cspg.kafka.domain.ems.EmsEnergyInfo;
import com.cspg.kafka.mapper.ems.EmsEnergyInfoMapper;
import com.cspg.kafka.service.ems.EmsEnergyInfoService;
import com.cspg.kafka.utils.FieldUtils;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.beanutils.ConvertUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.ReflectionUtils;
import javax.annotation.PostConstruct;
import java.lang.reflect.Field;
import java.util.List;
@Service
@Slf4j
@Transactional(rollbackFor = Exception.class)
public class EmsEnergyInfoServiceImpl extends ServiceImpl<EmsEnergyInfoMapper, EmsEnergyInfo> implements EmsEnergyInfoService {
@Autowired
private EmsEnergyInfoService emsEnergyInfoService;
@Autowired
private EmsEnergyInfoMapper emsEnergyInfoMapper;
@SneakyThrows
@Override
public void saveEmsInfo(String message){
EmsEnergyInfo result = new EmsEnergyInfo();
JSONArray infoArray = JSONArray.parseArray(message);
for (int i=0; i<infoArray.size(); i++){
JSONObject info = infoArray.getJSONObject(i);
String filedName = info.getString("field");
String filedValue = info.getString("value");
//下划线转驼峰
String humpFileName = FieldUtils.lineToHump(filedName);
//利用反射保存字段值
Class<EmsEnergyInfo> emsEnergyInfoClass = EmsEnergyInfo.class;
//获取对应字段
Field infoField = emsEnergyInfoClass.getDeclaredField(humpFileName);
ReflectionUtils.makeAccessible(infoField);
if (filedValue != null && filedValue.length() != 0){
ReflectionUtils.setField(infoField, result, ConvertUtils.convert(filedValue, infoField.getType()));
}
}
saveObject(EmsEnergyInfo.class.getName(), result);
}
private void saveObject(String tableClassName, Object object) {
log.info("准备入库,表名:{},对象结构:{}",tableClassName, object.toString());
tableClassName = tableClassName.substring(tableClassName.lastIndexOf(".") + 1);
System.out.println(tableClassName == "EmsEnergyInfo");
if (tableClassName.equals("EmsEnergyInfo")){
EmsEnergyInfo emsEnergyInfo = (EmsEnergyInfo) object;
int emsEnergyInfoCount = emsEnergyInfoService.count();
if(emsEnergyInfoCount == 1) {
List<EmsEnergyInfo> emsEnergyInfos = emsEnergyInfoMapper.selectList(null);
QueryWrapper<EmsEnergyInfo> emsEnergyInfoQueryWrapper = new QueryWrapper<>();
// 基本信息只有一条记录,同时为了避免id不等于,所以需获取数据后读取id
emsEnergyInfoQueryWrapper.eq("ems_id", emsEnergyInfos.get(0).getEmsId());
emsEnergyInfoService.update(emsEnergyInfo,emsEnergyInfoQueryWrapper);
} else {
emsEnergyInfoService.save(emsEnergyInfo);
}
}
}
}
其中FieldUtils.lineToHump里的写法
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class FieldUtils {
private static Pattern linePattern = Pattern.compile("_(\\w)");
/** 下划线转驼峰 */
public static String lineToHump(String str) {
str = str.toLowerCase();
Matcher matcher = linePattern.matcher(str);
StringBuffer sb = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(sb, matcher.group(1).toUpperCase());
}
matcher.appendTail(sb);
return sb.toString();
}
private static Pattern humpPattern = Pattern.compile("[A-Z]");
/** 驼峰转下划线 */
public static String humpToLine(String str) {
Matcher matcher = humpPattern.matcher(str);
StringBuffer sb = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(sb, "_" + matcher.group(0).toLowerCase());
}
matcher.appendTail(sb);
return sb.toString();
}
}
7、放些kafka常用的命令
#启动producer服务
bin/kafka-console-producer.sh --bootstrap-server ip:port --topic first
#启动kafka服务
bin/kafka-server-start.sh -daemon config/server.properties
#启动zookeeper服务 (先开启zk,再开kafka)
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
#停止服务
bin/kafka-server-stop.sh
bin/zookeeper-server-stop.sh
#启动consumer服务
bin/kafka-console-consumer.sh --bootstrap-server ip:port --topic topic名字
#查看当前有哪些topic
bin/kafka-topics.sh --bootstrap-server ip:port --list
#重头打印所有消费后的数据
bin/kafka-console-consumer.sh --bootstrap-server ip:port --from-beginning --topic topic名字
留言
这篇代码比较多,但是说的很详细,当然还有些类没放全,那些都是自定义的东西,比如实体类、topic的constants类啊… 有些注解可能爆红,因为我使用matis-plus,最后再加上我的pom吧,按情况加啊,有些没必要
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.vaadin.external.google</groupId>
<artifactId>android-json</artifactId>
<version>0.0.20131108.vaadin1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>2.15</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>com.auth0</groupId>
<artifactId>java-jwt</artifactId>
<version>3.10.3</version>
</dependency>
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-jwt</artifactId>
<version>1.0.9.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--knife4j接口文档 -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>2.0.7</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.5.8</version>
</dependency>
</dependencies>
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.15</version>
</dependency>
<!-- kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.4</version>
</dependency>