论文信息
name_en: LaMDA: Language Models for Dialog Applications
name_ch: LaMDA:对话应用程序的语言模型
paper_addr: http://arxiv.org/abs/2201.08239
doi: 10.48550/arXiv.2201.08239
date_read: 2023-03-30
date_publish: 2022-02-10
tags: [‘自然语言处理’,‘深度学习’]
author: Romal Thoppilan, Google
citation: 229
读后感
对于对话机器人的调优。提升模型的安全性和事实性,同时可咨询外部知识来源,如:信息检索系统、语言翻译器和计算器——结合了自然语言模型与其它工具。利用众包方式,选择人类偏好的回答。
介绍
Google推出的LaMDA(Language Model for Dialogue Applications),针对对话应用的大语言模型。它可以处理开放式对话,这种对话通常围绕特定主题展开(外部知识源)。
方法
模型结构
LaMDA采用的是纯decoder的结构,类似于GPT,使用了46层Transformer。
数据
在公共对话数据和 web tex 的 1.56T 词进行预训练,137B 参数。
以SSI为例,要求众包工作者与 LaMDA 实例就任何主题进行交互来收集 6400 轮,121K 的对话。这些对话需要持续 14 到 30 回合。对于每个响应,我们要求其他众包工作者进行标注。其它也使用类似的众包方法评测。
调优
通过在人工标注数据上做进一步finetune以及让模型学会检索利用外部知识源的能力,使得模型在安全性以及事实性这两个关键问题上获得明显提升。
LaMDA的finetune包括两部分,一部分是针对生成文本质量跟安全性,另一部分则是学习如何利用外部的信息检索系统。
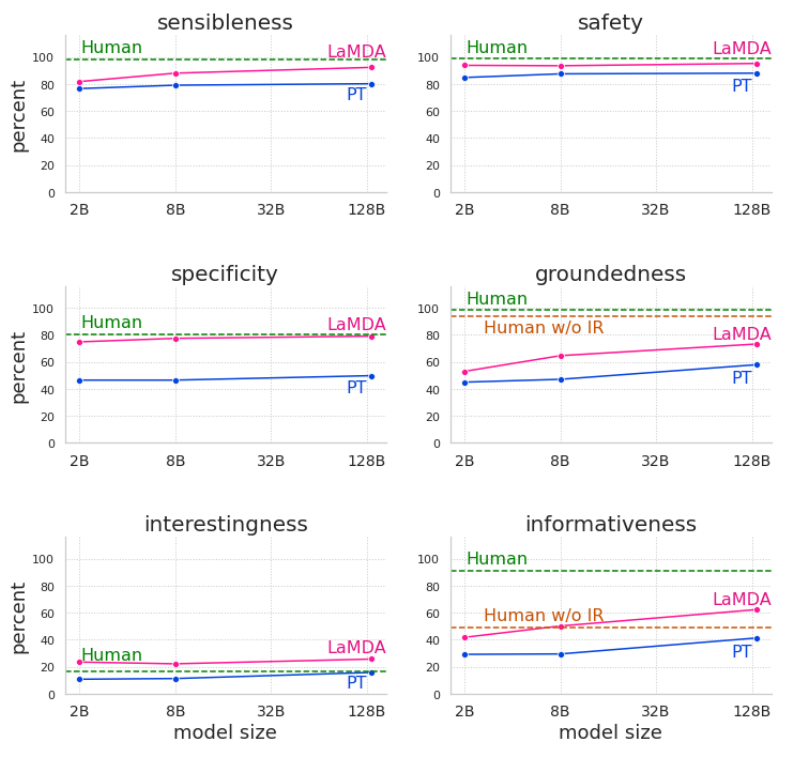
质量(SSI)可以从三方面评估,分别是:
- sensibleness:文本是否合理,跟历史对话是否有冲突;
- Specificity:对于前文是否有针对性,避免笼统回复;
- Interestingness:文本是否能引起某人注意或者好奇,是否是超出期待的巧妙回复
提供对于生成/判别任务的安全性和事实性
对于生成模型,数据以如下方式组织:
<context> <sentinel> <response>
对于判别模型,数据以如下方式组织:
<context> <sentinel> <response> <attribute-name> <rating>
结合sensible,specific,interesting三方面得分调优模型。
微调学习调用外部信息检索系统
有时事实是不断变化的,无法仅使用扩大模型规模的方法让模型反馈你想要的答案。使用以下方法调优模型:
- 加入工具集:创建了一个工具集 (TS),其中包括信息检索系统、计算器和翻译器。TS 将字符串作为输入并输出一个或多个字符串的列表。信息检索系统还能够从开放网络返回内容片段及其相应的 URL。
- 收集对话:收集了 40K 带注释的对话轮次带注释(生成数据)。其中 LaMDA 生成的候选者被标记为“正确”或“不正确”,用作排名任务的输入数据。(这个非常像InstructGPT里的reward标注)。微调语言模型,通过使用工具集查找其声明来为其响应回答。(newbing可能就是这么做的)
- 调优模型:
- 任务一:根据用户输入的内容,生成访问TS格式的数据(详见:newbing)
context + base → 提问TS的问题(其中base是其预训练模型返回的答案) - 任务二:通过TS返回的内容和上下文生成回答
context + base + query + snippet->返回给用户的答案
以下是一个示例:
- 任务一:根据用户输入的内容,生成访问TS格式的数据(详见:newbing)

实验
参考
中文文章: 对话机器人之LaMDA