1.查看微博网页内容
先打开微博,登录自己的账号,然后选择需要的用户页面。然后点击F12,打开开发者工具,点击network,然后重新刷新页面,选择XHR选项
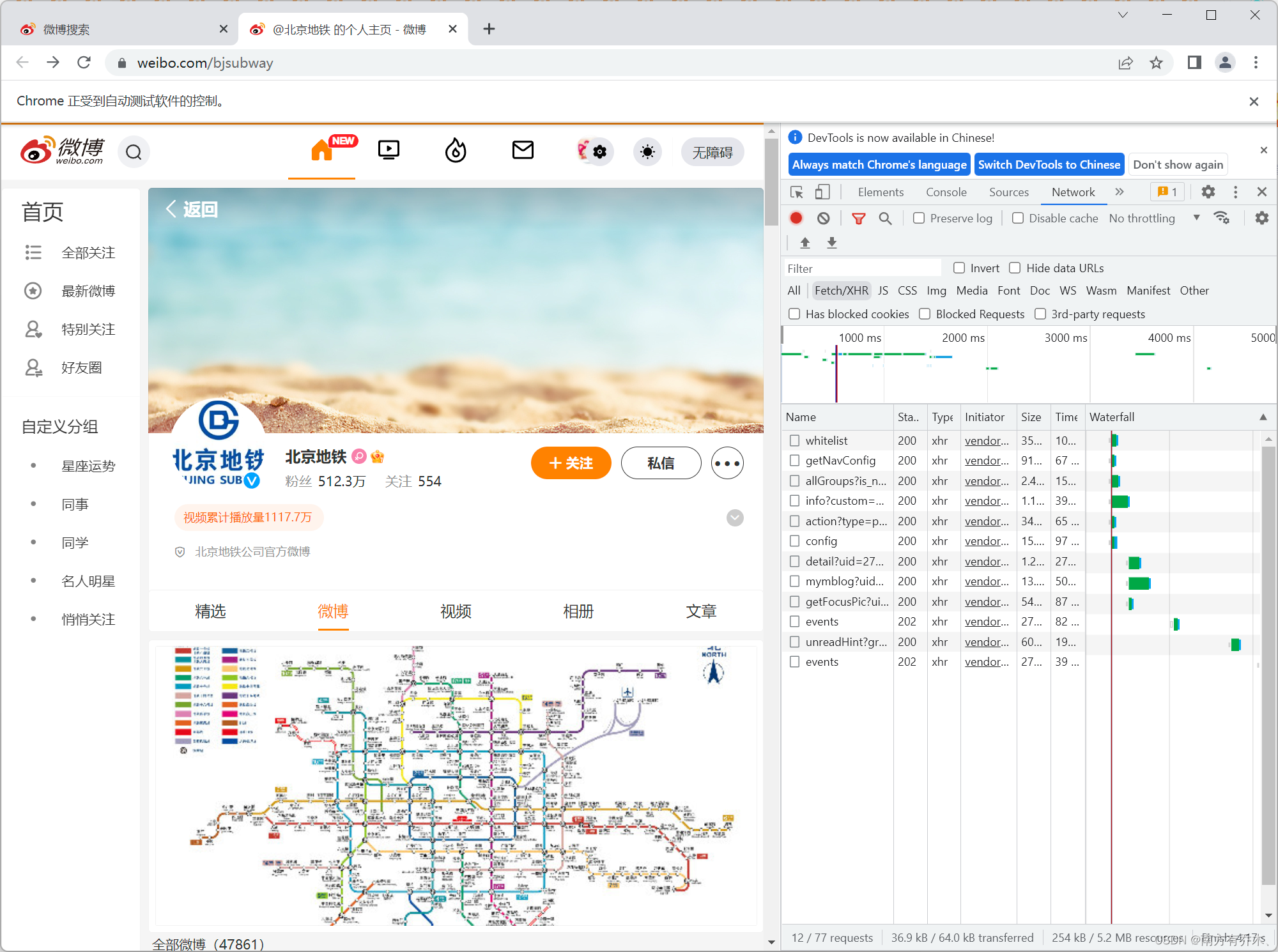
接下来就是在这些请求里找包含微博内容的请求
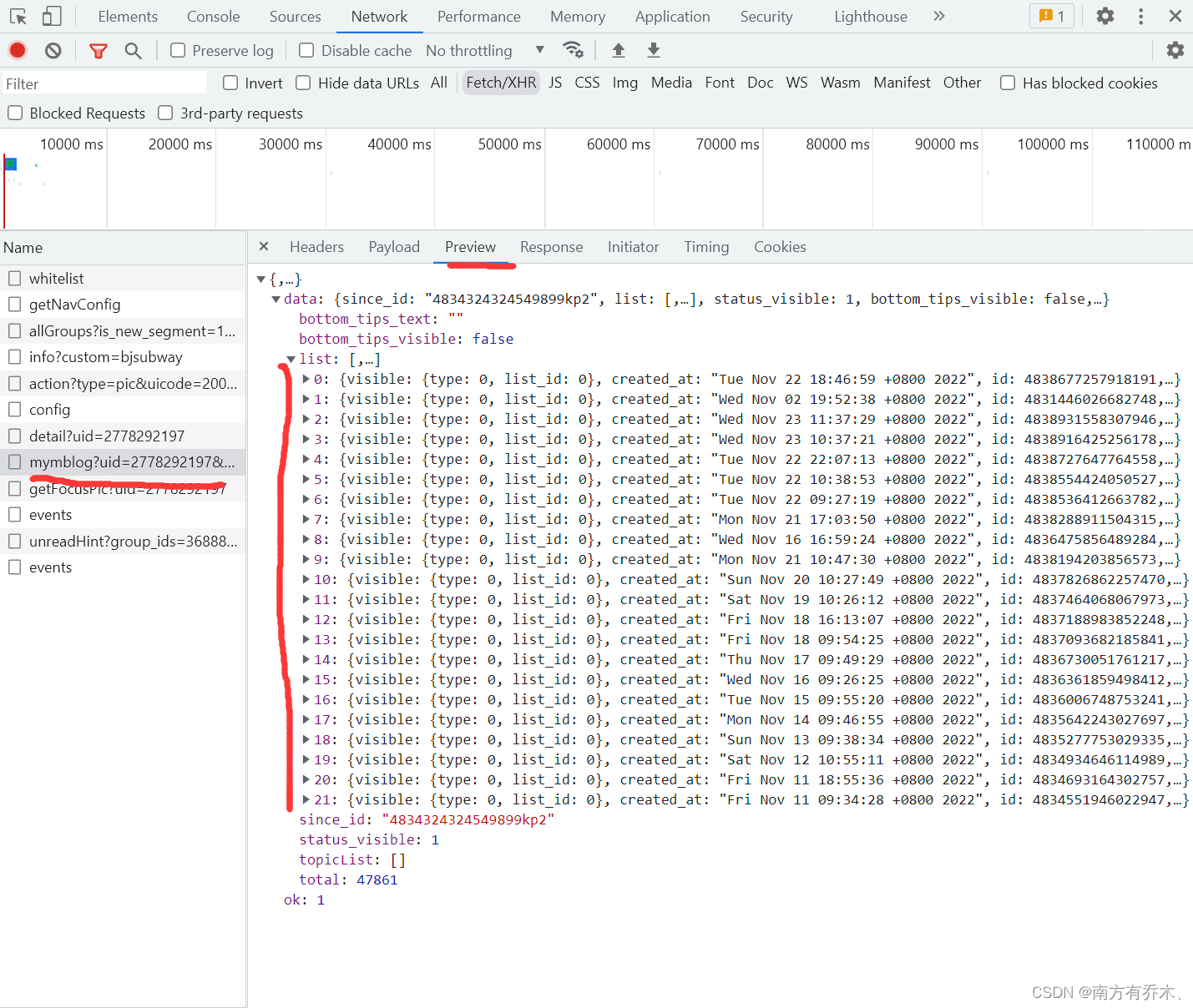
可以看到一次请求有22条内容
然后观察请求头
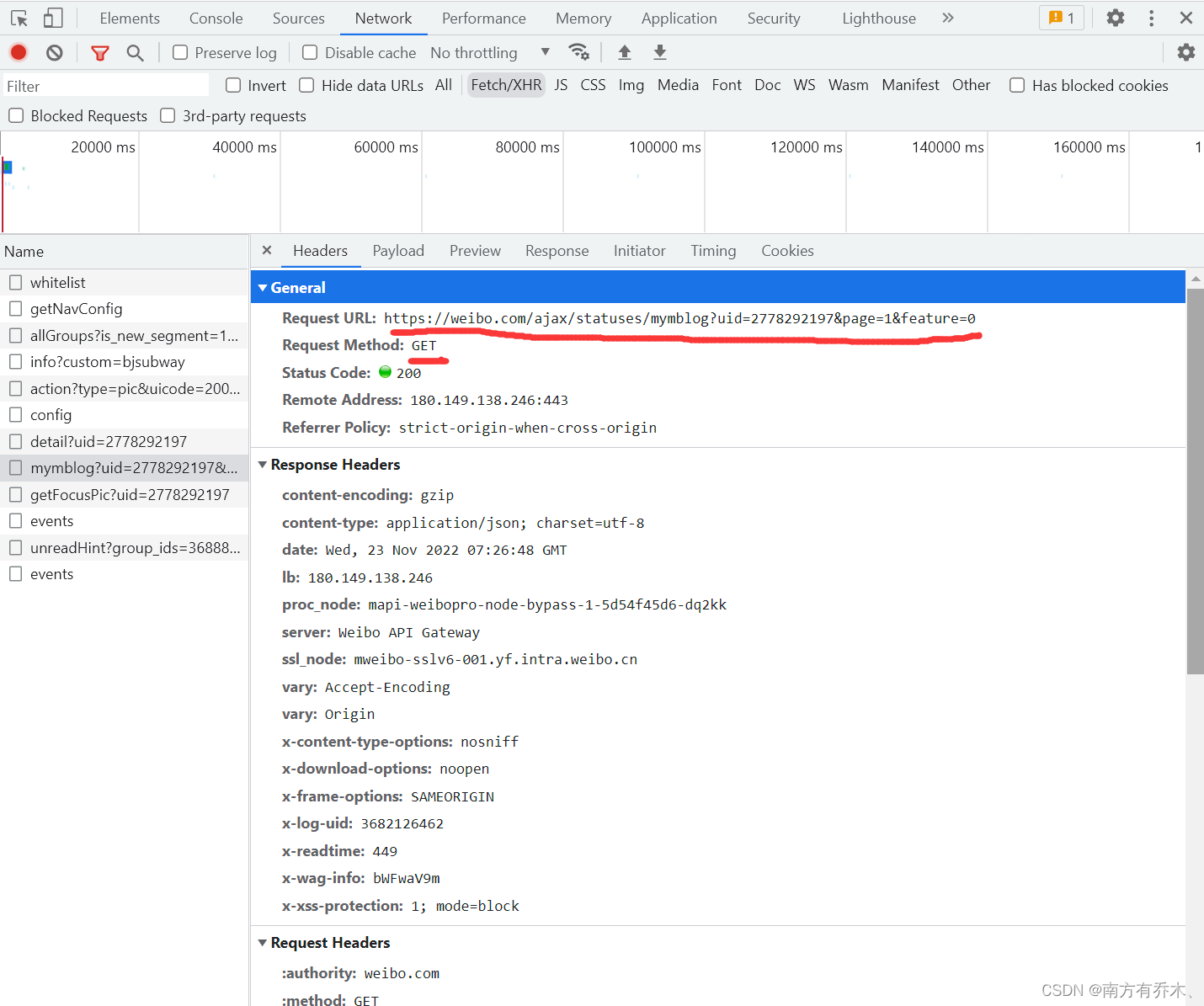
这些就是我们要请求的url
接下来就是爬虫的demo。在我们需要向这个url请求数据的时候一定要带上user-agent和cookie,不然请求会失败,而且cookie容易过期,如果过几天发现demo运行失败可以重新登录然后复制新的cookie。
扫描二维码关注公众号,回复: 15021254 查看本文章
在这里我们直接在请求头里往下拉,将里面的ua和cookie获取到就好了。
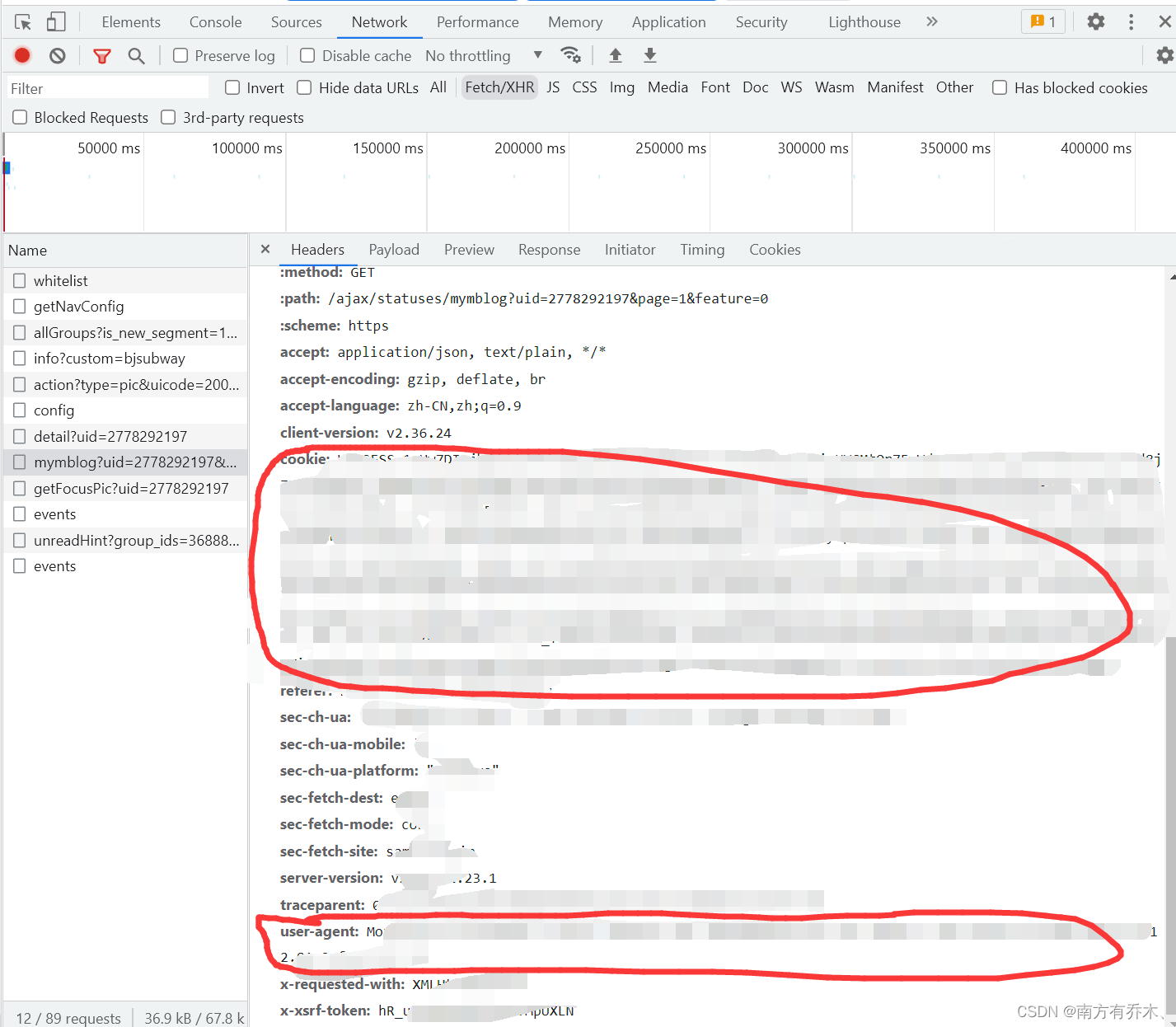
最后就是demo部分:
import requests
import json
headers = {
'user-agent': '你的ua',
'cookie': '你的cookie'
}
response = requests.get('https://weibo.com/ajax/statuses/mymblog?uid=2219143801&page=2&feature=0',headers=headers).json()
print(response)最后获得的结果:

这样子看着比较麻烦,可以直接在浏览器里看自己需要哪些内容。
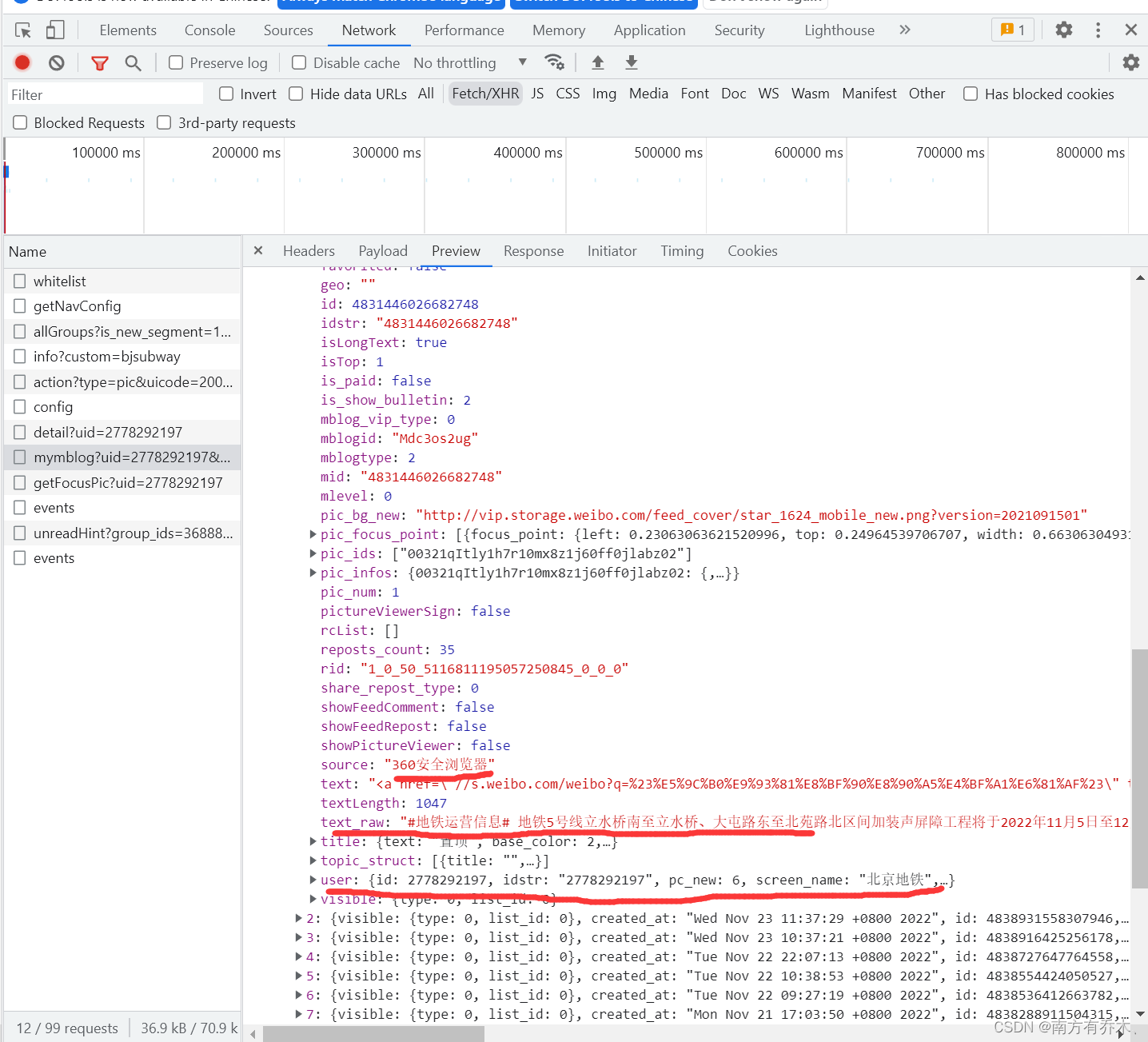
最后就是自己抓取需要的内容就好了。
这里仅是一页的内容,如果想要更多的内容,可以观察url的规则,可以看到url这里有个page=1
所以仅需要更改page数为2、3等就可以获得后面的微博内容。前面的uid则是该用户的id,更改uid为对应用户id值就可以获取别的用户的内容。