当应用程序尝试连接到服务或网络资源时,使应用程序能够通过以透明方式重试失败的操作来处理临时故障。 这可以提高应用程序的稳定性。
上下文和问题
与在云中运行的元素进行通信的应用程序必须能够敏感地察觉到此环境中可能会出现的暂时性错误。 这类故障包括组件和服务瞬间断开网络连接、服务暂时不可用,或者当服务繁忙时出现超时。
这些错误通常可以自己修复,如果在延迟合适的时间后重新执行触发了错误的操作,该操作可能会成功。 例如,处理大量并发请求的数据库服务可以实现限制策略,该策略会暂时拒绝任何后续请求,直到其工作负载得以减轻。 尝试访问该数据库的应用程序可能无法连接,但如果它在延迟一段时间后再次尝试,则可能会成功。
解决方案
在云中,暂时性错误很常见,因此应当将应用程序设计为能够优雅地以透明方式处理它们。 这可以尽量降低错误可能会给应用程序正在执行的业务任务带来的影响。
如果应用程序在尝试将请求发送到远程服务时检测到故障,则它可以使用以下策略来处理故障:
-
取消。 如果错误表明故障不是暂时性的或者在重新执行的情况下不可能成功,则应用程序应当取消操作并报告异常。 例如,对于因为提供了无效的凭据而导致的身份验证失败,无论尝试多少次,身份验证都不可能成功。
-
重试。 如果所报告的具体错误不常见或极少见,则它可能是由不常见的情况(例如网络包在传输过程中损坏)导致的。 在这种情况下,应用程序可以立即再次重试失败的请求,因为不大可能会重复出现同一故障并且请求可能会成功。
-
在延迟一段时间后重试。 如果错误是由更普遍的连接或繁忙故障之一引起的,则网络或服务可能需要很短的一段时间来等待连接问题得以修复或积压的工作得以清除。 应用程序应当等待合适的时间,然后重试请求。
对于更常见的暂时性故障,在选择重试之间的时长时应当考虑使来自应用程序的多个实例的请求尽可能均匀地分布。 这可以降低繁忙的服务持续过载的可能性。 如果应用程序的许多实例由于重试请求而导致某个服务持续过载,则该服务将需要更长的时间才能恢复。
如果请求仍然失败,则应用程序可以等待并进行另一尝试。 如果需要,可以在增大重试尝试之间的延迟时间的情况下不断重复此过程,直到已尝试的请求数目达到某个最大数目。 可以采用递增方式或指数方式增大延迟时间,具体取决于故障的类型和它在此时间段内被更正的可能性。
下图展示了使用此模式调用托管服务中的某个操作。 如果请求在经历预定义的尝试次数后没有成功,则应用程序应当将该错误视为异常并相应地对其进行处理。
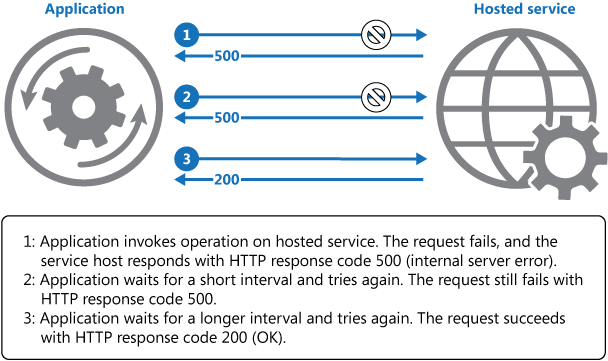
应用程序应当将访问远程服务的所有尝试包装在代码中并在代码中实现与上面列出的策略之一匹配的重试策略。 发送到不同服务的请求遵守不同的策略。 某些供应商提供了实现了重试策略的库,应用程序可以在这些重试策略中指定最大重试次数、重试尝试之间的间隔时间以及其他参数。
应用程序应当记录错误和失败操作的详细信息。 此信息对操作员比较有用。 尽管如此,为避免操作员在随后的重试尝试成功后收到大量操作警报,最好将早期失败记录为信息性条目,并仅将最后一次重试尝试失败记录为错误。 以下是此日志记录模型的示例。
如果某个服务频繁不可用或繁忙,通常是由于该服务已耗尽了其资源。 可以通过横向扩展该服务来降低出现这些错误的频率。 例如,如果某个数据库服务持续过载,则对数据库进行分区并将负载分布到多个服务器中可能有助于解决问题。
Microsoft Entity Framework 提供了用于重试数据库操作的设施。 另外,大多数 Azure 服务和客户端 SDK 都提供了重试机制。 有关详细信息,请参阅特定服务的重试指南。
问题和注意事项
在决定如何实现此模式时,应考虑以下几点。
应当对重试策略进行调整以匹配应用程序的业务要求和故障性质。 对于某些非关键操作,最好是快速失败而不是重试多次并影响应用程序的吞吐量。 例如,在访问远程服务的交互式 Web 应用中,最好是在重试较少次数后失败并且重试尝试之间的延迟时间应当很短,而且最好向用户显示合适的消息(例如“请稍后重试”)。 对于批处理应用程序,增加重试尝试次数并且在尝试之间采用呈指数级增长的延迟时间可能更为合适。
对于运行状况已接近或处于其容量上限的繁忙服务,如果采用尝试延迟时间间隔最小且尝试次数较多的积极重试策略,则可能会进一步降低性能。 如果此重试策略不断尝试执行失败的操作,则它还可能会影响应用程序的响应能力。
如果某个请求在进行大量的重试后失败,则应用程序最好是阻止发往同一资源的后续请求并立即报告失败。 当期限过期后,应用程序可以试探性地允许一个或多个请求通过以查看它们是否成功。 有关此策略的详细信息,请参阅断路器模式。
请考虑操作是否是幂等的。 如果是,则可以放心地进行重试。 否则,重试可能会导致操作执行多次并产生意外的副作用。 例如,某个服务可以收到请求,成功处理该请求,但无法发送响应。 此时,重试逻辑可能会认为第一个请求没有收到并重新发送请求。
对服务的请求可能会因各种原因而失败并引发不同的异常,具体取决于故障性质。 某些异常表明故障可以快速解决,而另一些异常表明故障会持续较长时间。 根据异常类型为重试策略调整重试尝试之间的时间间隔会起作用。
请考虑属于事务一部分的操作将如何影响总体的事务一致性。 请优调事务操作的重试策略以尽量提高成功几率并降低撤消所有事务步骤的需求。
请确保针对各种故障状况充分测试重试代码。 请检查并确保它不会严重影响应用程序的性能或可靠性、不会导致服务和资源过载,不会导致争用状况或瓶颈。
只有充分了解失败操作的完整上下文后才应实现重试逻辑。 例如,如果某个任务包含的重试策略会调用也包含重试策略的另一任务,则这一层额外的重试可能会给处理增加很长的延迟。 更好的解决方案可能是将较低级别的任务配置为快速失败并将失败原因报告给调用它的任务。 然后,此较高级别的任务可以根据自己的策略处理失败。
请务必记录导致重试的所有连接故障,以便可以查明应用程序、服务或资源的底层问题。
请调查服务或资源最有可能发生的错误以查明它们可能持续很长时间还是已处于末期。 如果可能持续很长时间,则最好将错误作为异常进行处理。 应用程序可以报告或记录异常,然后尝试通过调用备用服务(如果有)或通过提供降级的功能来继续运行。 有关如何检测和处理持续时间很长的错误的详细信息,请参阅断路器模式。
何时使用此模式
当应用程序与远程服务进行交互或者访问远程资源时可能会遇到暂时性错误时,请使用此模式。 这些错误预计只会短时存在,并且通过后续尝试重复执行之前失败的请求可能会成功。
在下列情况下,此模式可能不适用:
- 当错误可能会持续很长时间时,因为此模式可能会影响应用程序的响应能力。 如果应用程序尝试重复执行可能会失败的请求,可能会浪费时间和资源。
- 处理不是由于出现暂时性错误而导致的故障,例如,由应用程序的业务逻辑中的错误导致的内部异常。
- 作为替代方法来解决系统中的可伸缩性问题。 如果应用程序遇到频繁的繁忙错误,则这通常表明应当纵向扩展正在访问的服务或资源。
示例
以 C# 编写的此示例展示了重试模式的实现。 下面显示的 OperationWithBasicRetryAsync 方法通过 TransientOperationAsync 方法以异步方式调用一个外部服务。 TransientOperationAsync 方法的细节特定于该服务,示例代码中省略了其细节。
C#复制
private int retryCount = 3;
private readonly TimeSpan delay = TimeSpan.FromSeconds(5);
public async Task OperationWithBasicRetryAsync()
{
int currentRetry = 0;
for (;;)
{
try
{
// Call external service.
await TransientOperationAsync();
// Return or break.
break;
}
catch (Exception ex)
{
Trace.TraceError("Operation Exception");
currentRetry++;
// Check if the exception thrown was a transient exception
// based on the logic in the error detection strategy.
// Determine whether to retry the operation, as well as how
// long to wait, based on the retry strategy.
if (currentRetry > this.retryCount || !IsTransient(ex))
{
// If this isn't a transient error or we shouldn't retry,
// rethrow the exception.
throw;
}
}
// Wait to retry the operation.
// Consider calculating an exponential delay here and
// using a strategy best suited for the operation and fault.
await Task.Delay(delay);
}
}
// Async method that wraps a call to a remote service (details not shown).
private async Task TransientOperationAsync()
{
...
}
包装在 for 循环中的一个 try/catch 块包含了调用此方法的语句。 如果对 TransientOperationAsync 方法的调用成功且没有引发异常,则 for 循环会退出。 如果 TransientOperationAsync 方法失败,则 catch 块会检查失败原因。 如果认为失败原因是某个暂时性错误,则代码将等待很短的延迟时间,然后重试该操作。
For 循环还会跟踪已尝试的操作次数,并且如果代码失败三次,则会认为异常将持续更长的时间。 如果异常不是暂时性的或者它持续很长时间,则 catch 处理程序会引发异常。 此异常会使 for 循环退出,应当由调用 OperationWithBasicRetryAsync 方法的代码捕获此异常。
下面显示的 IsTransient 方法检查是否存在与在其中运行代码的环境相关的一组特定异常。 暂时性异常的定义根据正在访问的资源以及在其中执行操作的环境而异。
C#复制
private bool IsTransient(Exception ex)
{
// Determine if the exception is transient.
// In some cases this is as simple as checking the exception type, in other
// cases it might be necessary to inspect other properties of the exception.
if (ex is OperationTransientException)
return true;
var webException = ex as WebException;
if (webException != null)
{
// If the web exception contains one of the following status values
// it might be transient.
return new[] {WebExceptionStatus.ConnectionClosed,
WebExceptionStatus.Timeout,
WebExceptionStatus.RequestCanceled }.
Contains(webException.Status);
}
// Additional exception checking logic goes here.
return false;
}
后续步骤
-
编写自定义重试逻辑之前,请考虑使用通用框架,例如适用于 .NET 的 Polly 或适用于 Java 的 Resilience4j。
-
处理更改业务数据的命令时,请注意,重试可能会导致该操作执行两次,如果该操作类似于要求客户使用信用卡付费,则可能会出现问题。 使用这篇博客文章中描述的幂等模式可以处理这些情况。
相关资源
-
适用于 .NET 的可靠 Web 应用模式演示如何将重试端模式应用于云上聚合的 ASP.NET Web 应用程序。
-
对于大多数 Azure 服务,客户端 SDK 包含内置的重试逻辑。 有关详细信息,请参阅 Azure 服务的重试指南。
-
断路器模式。 如果预计故障会持续较长时间,则实现断路器模式可能更为合适。 结合使用重试和断路器模式可综合地处理故障。
建议的内容
-
优先级队列模式 - Azure Architecture Center
为发送到服务的请求确定优先级,以便高优先级请求能够得到比低优先级请求更快速地接收和处理。
-
断路器模式 - Azure Architecture Center
连接到远程服务或资源时处理故障,此类故障所需修复时间不定。
-
saga 模式 - Azure Design Patterns
使用 Saga 设计模式,确保微服务体系结构中分布式事务的数据一致性。
-
异步请求-答复模式 - Azure Architecture Center
在后端处理需要是异步处理但前端仍需要明确响应的情况下,允许将后端处理与前端主机解耦。
-
声明-检查模式 - Azure Architecture Center
了解声明-检查模式,该模式将大型消息拆分成声明检查和有效负载,以免消息总线过载。
-
补偿事务模式 - Azure Architecture Center
当最终一致性操作的步骤失败时,使用补偿事务模式撤消工作。
-
速率限制模式 - Azure Architecture Center
可以使用速率限制模式来帮助避免或尽量减少限制错误。
-
事件溯源模式 - Azure Architecture Center
使用只追加存储来记录描述域中数据采取的操作的完整系列事件。
显示较少选项