今日重点:DQL 及学习要点与练习环境说明
DQL 是数据查询语言,用于查询数据,它是我们在真正的开发中使用最多的一种。而我们项目用 得最多的也是查询。而在 SQL 中, DQL 所占比例也是最大的,结构也是最复杂的。
本章用的软件:
MySQL8.0.28(linux)
Navicat 15 数据库远程
官方练习库表:world.sql 此表是练习表,数据肯定不准确望周知
学习环境说明:
world数据库
city 城市表 (第一张表)
country 国家表 (第二张表)
countrylanguage 国家的语言 (第三张表)
查看表结构:
desc + 表名
查看city表结构
desc city; 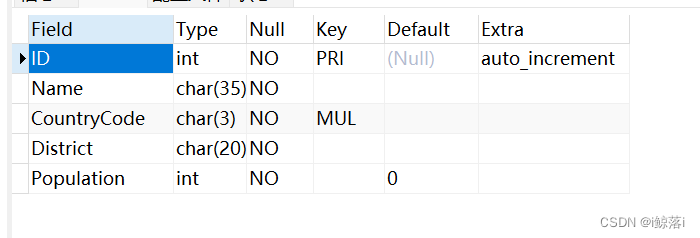
表结构详解:
ID : 城市序号(1-...)
name : 城市名字
countrycode : 国家代码,例如:CHN,USA
district : 区域: 中国 省 美国 洲
population : 人口数
个人网站地址无任何不良诱导
本章mysql练习库表sql 下载: 如果嫌看的麻烦 我自己讲的教学视频也在网址里面 可直接下载world.sql练习库表 与 Navicat 15 数据库远程链接软件(永久激活)下载地址![]() https://www.bdqn.vip/download_one/
https://www.bdqn.vip/download_one/
使用方式:将world.sql 导入到 /(根目录下) 下后 ,登录数据库以后
导入库表命令:
source /world.sql目录
四、ORDER BY 排序 、 GROUP BY 分组(配合聚合函数(MAX))
select通用语法与条件
select + 列
from +表
where +条件 满足条件查
group by+ 条件 分组查询
having + 条件 排序 或者过滤
order by +条件 排序
limit+ 不显示所有 显示前几 select * from 表名 limit 3;显示前三行查询语句之条件查询
WHERE 条件所有的写法加实例演示
一、where 配合比较判断查询
> 大于,< 小于, >=大于等于,<= 小于等于,<>不等于
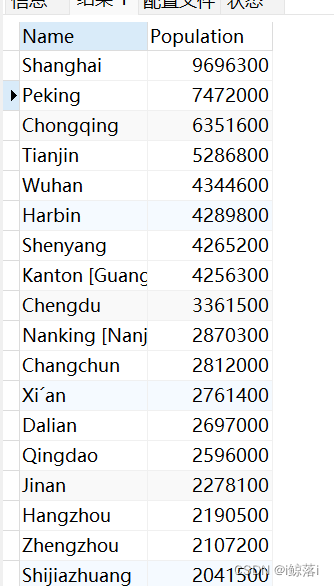
1、查询中国的所有城市和人口数量
SELECT `Name`,Population from city WHERE CountryCode="CHN";查询结果:
2、 查询世界上人口小于一百人的城市名字和人口数量
SELECT `Name`,Population FROM city WHERE Population<100;查询结果:
亚当斯敦 人口数小于42

3、除了美国显示其他所有国家(取反)
SELECT * FROM city WHERE CountryCode<>"USA";查询结果: 结果内就不包含 USA 其余的全部显示,注意 实际环境不建议用 * 号 ,容易卡死
所有的 > 大于,< 小于, >=大于等于,<= 小于等于,<>不等于 与上写法一致 就不 一 一演示了
二、where 的逻辑连接符 (and or)
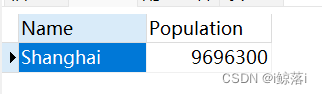
1、查询中国人口大于800万的城市
注意连接符 AND 表示前后两个条件都要满足
SELECT
`Name`,
Population
FROM
city
WHERE
CountryCode = "CHN"
AND Population > 8000000;查询结果:
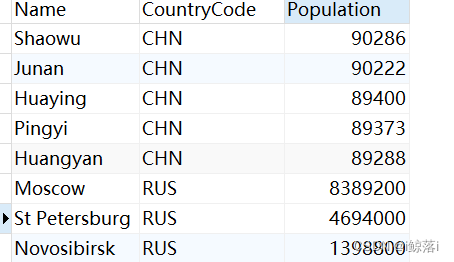
2、 查询所有中国与俄罗斯的城市与人口数
注意链接符号 or 表示前后两个条件满足其一即可显示
SELECT
`Name`,
CountryCode,
Population
FROM
city
WHERE
CountryCode = "CHN"
OR CountryCode = "RUS";查询结果:
三、where 条件过滤 之 BETWEEN
BETWEEN 介于什么与什么之间 中间链接符号为 AND
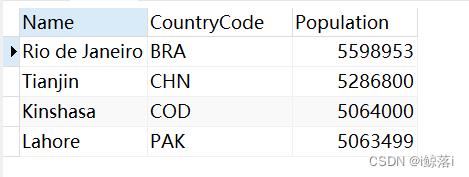
1、查询所有人口在500万到600万之间的所有城市名字
SELECT
`Name`,
CountryCode,
Population
FROM
city
WHERE
Population BETWEEN 5000000
AND 6000000;查询结果:
当然这个BETWEEN 不限制与人口数量,也可以查询时间
时间不在本次练习的表中,为了演示我自行随意弄了个表,为了让大家更好的了解
按日期查询
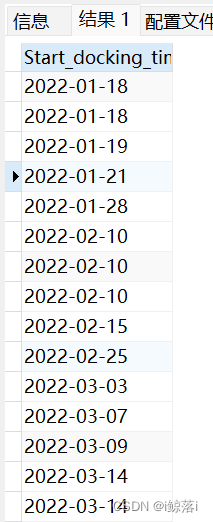
2、介于2022-01-01 到 2022-03-31日期之间的所有数据
SELECT
Start_docking_time #字段名
FROM
app_handoverinfo #表名
WHERE
Start_docking_time BETWEEN "2022-01-01" #查询所有 今年 1月份到3月份所有的时间
AND "2022-03-31";查询结果:
四、where 之模糊查询
LIKE 模糊查询关键字 %代表所有字符
注意事项:不要出现类似于 %CH%,前后都有百分号的语句,因为不走索引,性能极差
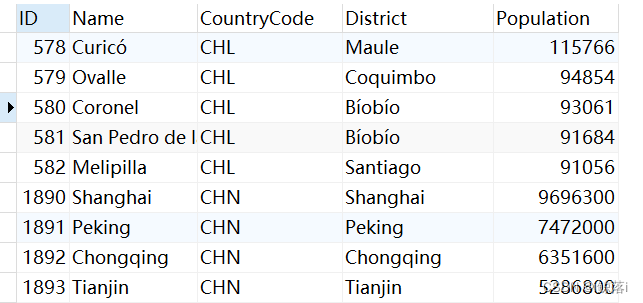
1、查询国家中带有CH开头的,城市信息
SELECT
*
FROM
city
WHERE
CountryCode LIKE "CH%"; 查询结果:
聚合函数、分组、去重
#-------------聚合函数关键字-------------------
SUM #求和
AVG #平均值
COUNT #统计
MAX #最大值
MIN #最小值
#-------------条件分组关键字-------------------
GROUP BY #分组
#-------------去重关键字-----------------------
DISTINCT #去重
#--------------排序关键字----------------------
ORDER BY一、count 统计
切记 统计需要配合分组一起使用 不然会报错
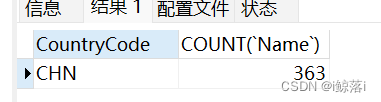
1、统计中国有多少个城市
SELECT
CountryCode,
COUNT( `Name` )
FROM
city
WHERE
CountryCode = "CHN"
GROUP BY
CountryCode;查询结果:
二、SUM求和
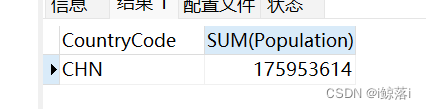
1、查询中国所有人口的总数
SELECT
CountryCode,
SUM( Population )
FROM
city
WHERE
CountryCode = "CHN";查询结果:
三、MAX 最大值
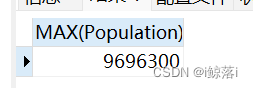
1、查询中国人口数量最大的值
SELECT MAX(Population) FROM city WHERE CountryCode="CHN";查询结果:
四、ORDER BY 排序 、 GROUP BY 分组(配合聚合函数(MAX))
注意 ORDER BY 加上desc 就是降序(默认升序)
2、查询中国,地区 人口最多的地方 (通过group by 分组 可以获取每个组的最大值)
可以作为ORDER BY 的排序条件
LIMIT 显示前几
SELECT
District,#地区
MAX( Population ) #人口最大
FROM
city
WHERE
CountryCode = "CHN"
GROUP BY
District
ORDER BY
MAX( Population ) DESC
LIMIT 1;#只显示第一个查询结果:

五、min 最小值
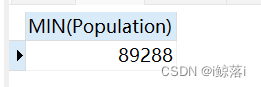
1、查询中国人口数最少的值
SELECT MIN(Population) FROM city;
查询结果:
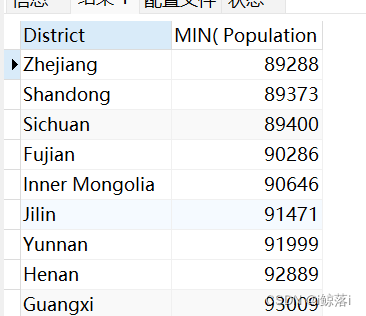
2、查询中国,地区 人口最少的地方(通过group by 分组 可以获取每个组的最小值)
可以作为ORDER BY 的排序条件
SELECT
District, #地区
MIN( Population ) #人口最小
FROM
city
WHERE
CountryCode = "CHN" #条件中国
GROUP BY
District #按省分组
ORDER BY
MIN(Population); #按最小值排序查询结果:
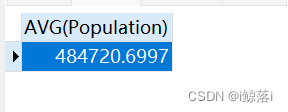
六、AVG平均值
1、查询中国人口总数的平均值
SELECT
AVG( Population )
FROM
city
WHERE
CountryCode = "CHN";查询结果:
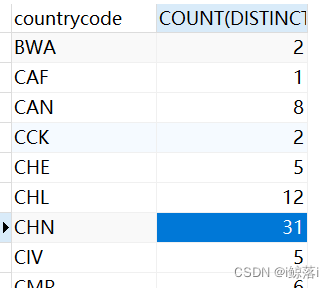
七、DISTINCT 去重
1、统计每个 国家 地区 的个数 通过DISTINCT 去重 同名只保留一个
SELECT
countrycode,
COUNT( DISTINCT district )
FROM
city
GROUP BY
countrycode;查询结果:
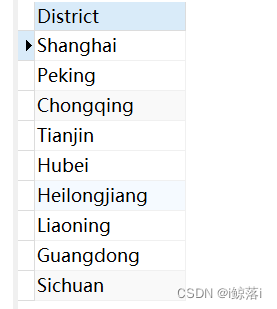
2、查询中国所有的地区 并去重
DISTINCT 也可以单独拿出来写
SELECT DISTINCT
District
FROM
city
WHERE
CountryCode = "CHN";查询结果:
HAVING 筛选成组后的各种数据
首先 HAVING 与 WHERE 的区别:
1、where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。而 having子句在聚合后对组记录进行筛选。
2、where不能使用聚合函数、having中可以使用聚合函数
例如:SELECT Population FROM city WHERE SUM(Population) > 8000000; 错误写法
简单来说,就是where 是直接对表中数据做,而HAVING 是针对前置条件进行条件判断的
3、可以配合where使用,作用不大 花里胡哨~~~ 哈哈哈~~
举例:
1、统计所有国家的总人口数量,将总人口数大于8000w的过滤出来,并且按照从大到小顺序排列
SELECT
CountryCode, #国家名字中
SUM( Population ) #统计人口
FROM
city
GROUP BY
CountryCode
HAVING
SUM( Population ) > 80000000 #条件,切记需要前置有 才可用 having
ORDER BY
SUM( Population ) DESC #按人口总数降序查询结果:
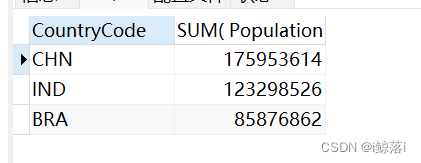
HAVING 配合 WHERE 一起使用
作用不大,就是花里胡哨,看起来代码多复杂 哈哈哈~~~
SELECT
District,
SUM( Population ),
COUNT(*)
FROM
city
WHERE
CountryCode BETWEEN "CHN"
AND "RUS"
GROUP BY
District
HAVING
COUNT(*) > 40
ORDER BY
SUM( Population ) DESC查询结果:

LIMIT 偏移量
LIMIT M,N :跳过M行,显示一共N行
LIMIT Y OFFSET X: 跳过X行,显示一共Y行
1、查询国家总人口大于5000万 并且降序,显示前三 偏移 一 位
SELECT
CountryCode, #国家缩写
SUM( Population ) #统计人口总数
FROM
city
GROUP BY
CountryCode #按国家分组
HAVING
SUM( Population ) > 50000000 #查询大于5000万的
ORDER BY
SUM( Population ) DESC #按总数降序
LIMIT 3 OFFSET 1; #显示前三,并向后偏移一位查询结果:
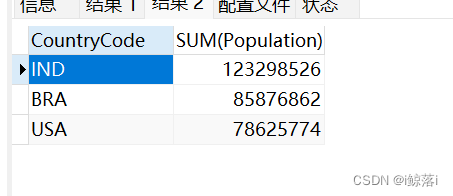
2、第二种实现偏移方法
SELECT
CountryCode,
SUM( Population )
FROM
city
GROUP BY
CountryCode
HAVING
SUM( Population ) > 50000000
ORDER BY
SUM( Population ) DESC
LIMIT 1,3; ##这里注意 1 代表跳过第一行 3 代表只显示三行与上面查询结果一致
UNION 和 UNION ALL 合并查询
注意事项:
UNION 合并查询结果不去重
UNION ALL 合并查询结果去重
union的字段数 不一致会报错
1、查询中国或俄罗斯的全部信息
几种写法效果相同,做对比
第一种where写法
SELECT
*
FROM
city
WHERE
CountryCode = "CHN"
OR CountryCode = "RUS";第二种 UNION 写法
SELECT * FROM city WHERE countrycode='CHN'
UNION ALL ##将两条语句链接并去重 不加all 就是不去重
SELECT * FROM city WHERE countrycode='RUS';查询结果:

多表联查
JOIN 按照功能可分为如下三类:
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录;
LEFT JOIN(左连接):获取左表中的所有记录,即使在右表没有对应匹配的记录,并为空NULL;
RIGHT JOIN(右连接):与 LEFT JOIN 相反,用于获取右表中的所有记录,即使左表没有对应匹配的记录。
直接 JOIN 默认的是内链接
练习表内容: 我们先看一下个个链接的区别 AS 为别名 ##这个表不在world库中,大家了解下写法后,自行练习
两张表一张学生表(student ) 一张成绩表(score) 共同列 为学号(code)
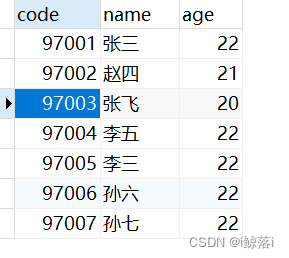
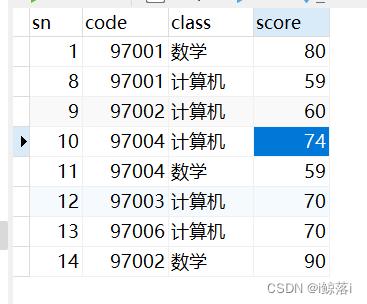
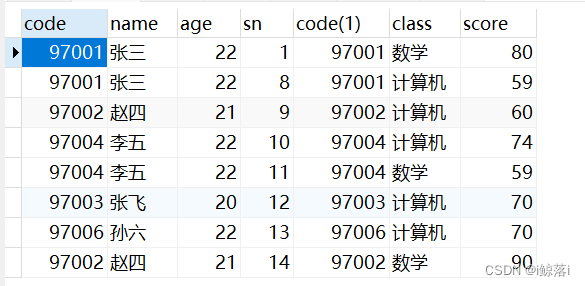
INNER JOIN 内连接
匹配两个表中都有的内容,不匹配的不显示
SELECT * FROM student as a INNER JOIN score AS b ON a.`code`=b.`code`; 查询结果:
LEFT JOIN 左连接
右表(score)匹配左表(student)的内容,如果右表中没有的则显示为空
SELECT * FROM student as a LEFT JOIN score AS b ON a.`code`=b.`code`; 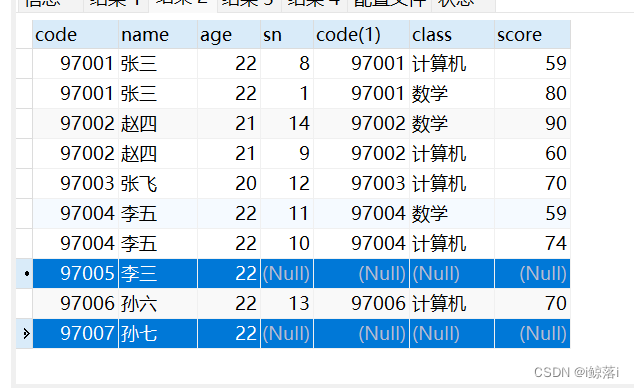
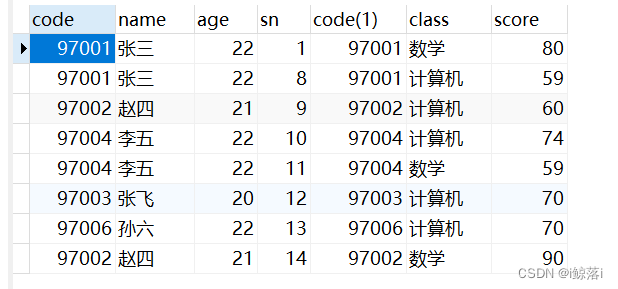
RIGHT JOIN 右连接
左表(student)匹配右表的内容(score),只有右表中有的才显示,没有的不显示
SELECT * FROM student as a RIGHT JOIN score AS b ON a.`code`=b.`code`;查询结果:
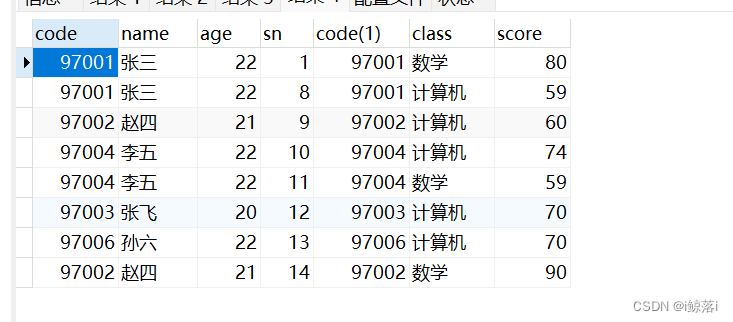
JOIN 链接直接写 默认是内连接
SELECT * FROM student as a JOIN score AS b on a.`code`=b.`code`; 查询结果:
1、查询赵四的数学成绩
#a 代表 学生名字表
#b 代表 学生成绩表
SELECT
a.`name`,
b.class,
b.score
FROM
student AS a
JOIN score AS b ON a.`code` = b.`code` #默认内连接
WHERE
b.class = "数学" #条件
AND a.`name` = "赵四"; #条件查询结果:
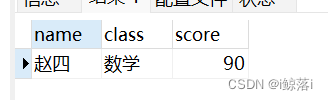
多表联查稍难的例子
练习表内容:
学生名字表(student) 老师名称表(teacher) 课程表(course) 成绩表(score)

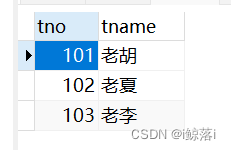
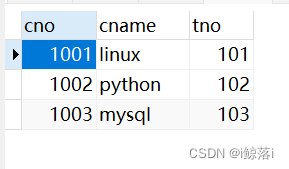
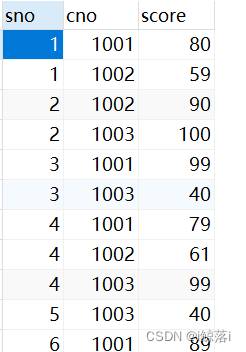
根据以上四表进行查询
扩充知识点:
| 函数 | 说明 |
|---|---|
| FLOOR(X) | 返回不大于X的最大整数(简单来说就是取整) |
| ROUND(X) | 返回离X最近的整数,截断时要进行四舍五入(简单来说就是四舍五入) |
| ROUND(X,D) | 保留X小数点后D位的值,截断时要进行四舍五入。(简单来说就是保留小数点后几位,并将未保留的数四舍五入) |
| FORMAT(X,D) | 将数字X格式化,将X保留到小数点后D位,截断时要进行四舍五入。(与上面一致) |
| CASE | 满足条件,并返回 |
具体用法参考以下
1. 查询平均成绩大于70分的同学的学号和平均成绩并排序
注意 下面用了一个新的函数FLOOR 舍弃小数点后面的位数,只保留整数
SELECT
a.sname, #学生名字
FLOOR(AVG( b.score )) 学生平均成绩
FROM
student AS a
LEFT JOIN score AS b ON a.sno = b.sno
#将共同列链接
GROUP BY
a.sname #以名字分组
HAVING
AVG( b.score )> 70 #平均成绩大于70
ORDER BY
AVG( b.score ) DESC; #降序排序运行结果:

2、查询只选修了一门课的学生名称
思路:将多表连起来---设置别名---找关键字段----通过名字去重-----统计有多少课程---并将课程少于两个的查询出来
SELECT DISTINCT #DISITNCT 去重
s.sname,
COUNT( c.cname ) #统计课程名字
FROM
student AS s
JOIN score AS sc ON s.sno = sc.sno #将三表连起来
JOIN course AS c ON sc.cno = c.cno
GROUP BY
s.sname
HAVING
COUNT( c.cname )< 2; #小于2的全部显示出来
查询结果:
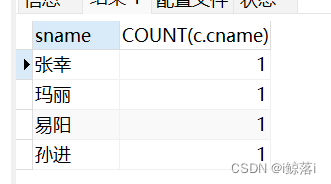
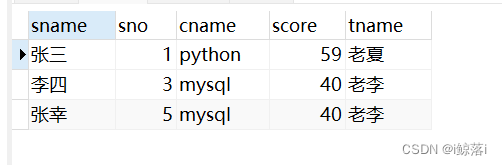
3、查询成绩小于60的 学生名字,学号,科目,成绩,科目老师名字
SELECT
s.sname, #学生名字
s.sno, #学号
c.cname, #科目名字
sc.score, #成绩
t.tname #老师名字
FROM
student AS s #将四表连起来
JOIN score AS sc ON s.sno = sc.sno
JOIN course AS c ON sc.cno = c.cno
JOIN teacher AS t ON c.tno = t.tno
WHERE
sc.score < 60; #成绩低于60的查询结果:
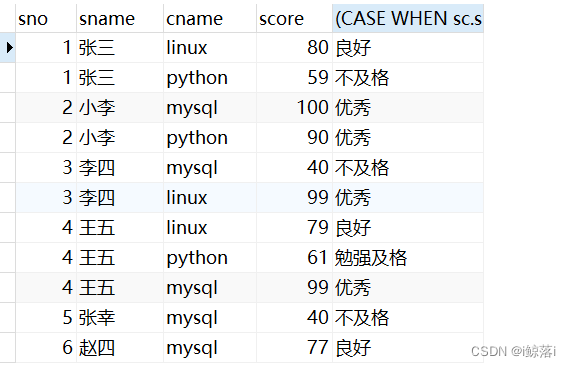
4、查询每门课程的成绩 大于85分的为优秀,良好(71-85),一般(60-70),不及格(小于60)的学生列,并按学号排序
思路:现将所有表连起来查看一下,找出要的关键字段,不加任何条件,查看一下,然后根据CASE 函数 来写一个判断语句即可
SELECT
s.sno,
s.sname,
c.cname,
sc.score,(
CASE
WHEN sc.score > 85 THEN
"优秀"
WHEN sc.score < 85 AND sc.score > 71 THEN
"良好"
WHEN sc.score BETWEEN 60
AND 70 THEN
"勉强及格" ELSE "不及格"
END
)
FROM
student AS s
JOIN score AS sc ON s.sno = sc.sno
JOIN course AS c ON sc.cno = c.cno
JOIN teacher AS t ON c.tno = t.tno
ORDER BY
s.sno;查询结果:
特殊查询方法
1、查询MySQL的安装位置
select @@basedir;2、查询端口号
select @@port;3、模糊查看innodb开头的配置
show variables like 'innodb%';4、查询当前系统时间
select now();