点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
内容来自CVer计算机视觉


宋子扬:
香港理工大学计算机系博士二年级, 导师 YANG Bo. 研究兴趣为无监督的三维场景理解
本文设计了一种通用的、能分割多个物体的无监督3D物体分割方法:这种方法在完全无标注的点云序列上进行训练,从运动信息中学习3D物体分割;经过训练后,能够直接在单帧点云上进行物体分割。为此,本文提出了无监督的3D物体分割方法OGC (Object Geometry Consistency)。

OGC: Unsupervised 3D Object Segmentation from Rigid Dynamics of Point Clouds
论文:https://arxiv.org/abs/2210.04458
代码:https://github.com/vLAR-group/OGC
在物体部件分割和室内、室外物体分割任务上的效果图(无需任何人工标注):
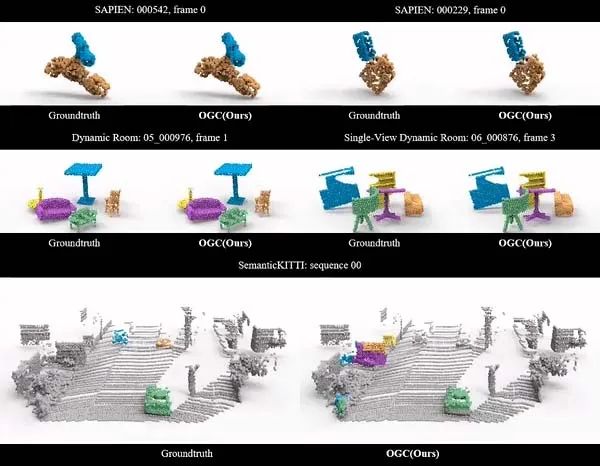
01
Introduction
三维点云物体分割是三维场景理解的关键问题之一,也是自动驾驶、智能机器人等应用的基础。然而,目前的主流方法都是基于监督学习,需要大量人工标注的数据,而对点云数据进行人工标注是十分耗费时间和人力的。
02
Motivation
本文旨在寻求一种无监督的3D物体分割方法。我们发现,运动信息有望帮助我们实现这一目标。如下图1所示,在左图中的蓝色/橙色圆圈内,一辆汽车上的所有点一起向前运动,而场景中其他的点则保持静止。那么理论上,我们可以基于每个点的运动,将场景中属于汽车的点和其他点分割开,实现右图中的效果。
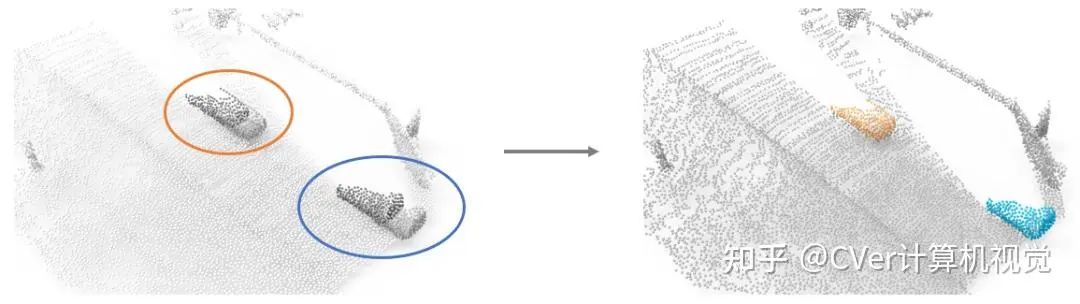
Figure 1. 利用运动信息分割物体的motivation
利用运动信息分割3D物体的想法已经在一些现有的工作中得到了探索。例如,[1] 和 [2] 利用传统的稀疏子空间聚类的方法从点云序列中分割运动的物体;SLIM [3] 提出了第一个基于学习的方法来分割运动的前景和静止的背景。然而,现有的方法都在以下的一个或多个方面存在局限性:
1)只适用于特定场景,不具备通用性;
2)只能实现运动的前景和静止的背景之间的二类分割,无法进一步区分前景中的多个物体;
3)(几乎所有的现有方法都存在的局限)必须要多帧的点云序列作为输入,而且只能分割出其中在运动的物体。但是理论上,我们利用运动信息学会辨别某些物体之后,当这些物体以静止的状态出现在单帧点云中,我们应该依然能辨别它们。
针对上述问题,我们希望设计一种通用的、能分割多个物体的无监督3D物体分割方法:这种方法在完全无标注的点云序列上进行训练,从运动信息中学习3D物体分割;经过训练后,能够直接在单帧点云上进行物体分割。为此,本文提出了无监督的3D物体分割方法OGC (Object Geometry Consistency)。本文的主要贡献包括以下三点:
1)我们提出了第一个通用的无监督3D物体分割框架OGC,训练过程中无需任何人工标注,从点云序列包含的运动信息中学习;经过训练后能直接在单帧点云上进行物体分割。
2)作为OGC框架的核心,我们以物体在运动中保持几何形状一致作为约束条件,设计了一组损失函数,能够有效地利用运动信息为物体分割提供监督信号。
3)我们在物体部件分割和室内、室外物体分割任务上都取得了非常好的效果
03
Method
3.1
Overview
如下图2所示,我们的框架包括三个部分:
1)一个物体分割网络(橙色部分),从单帧点云估计物体分割mask;
2)一个自监督的场景流估计网络(绿色部分),估计两帧点云之间的运动(场景流);
3)一组损失函数(蓝色部分),利用2)估计出的运动为1)输出的物体分割mask提供监督信号。
在训练过程中,需要三个部分联合工作;在训练后,只需保留1)的物体分割网络,即可用于分割单帧点云。

Figure 2 OGC示意图
对于OGC框架中的物体分割网络和场景流估计网络,我们可以直接利用现有的网络结构,如下图3所示。具体来说:

3.2
OGC Losses
OGC框架的关键,就在于如何利用运动信息为物体分割提供监督信号。为此,我们设计了以下损失函数:
1)Dynamic loss:现实世界中大部分物体的运动都可以用刚体变换来描述。因此在这项损失函数中,我们要求对每个估计出的物体分割mask,其中所包含的点的运动必须服从同一个刚体变换:
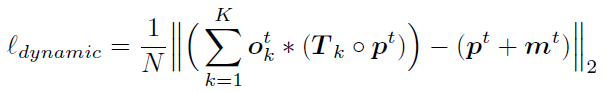
上式中,
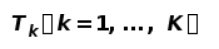
表示每个物体分割mask上拟合出的刚体变换。如果一个mask实际上包含了两个运动方向不同的物体,这两个物体上点的运动必然不可能服从同一个刚体变换。此时用这两个物体上的点强行拟合出的刚体变换与这些点的实际运动并不一致,这个mask就会被损失函数惩罚。可以看到,dynamic loss能帮助我们区分运动方向不同的物体。但是,如果实际上属于同一个物体的点被分割成两块,即“过度分割”,dynamic loss并不能惩罚这种情况。
2)Smoothness loss:物体上的点在空间中一般都是连接在一起的,否则物体就会断裂。基于这一事实,我们提出了对物体分割mask的平滑性先验,要求一个局部区域内相互邻近的点被分配到同一个物体:
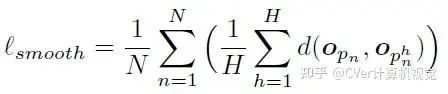
上式中H表示某个点的领域内包含的点的数量。可以看到dynamic loss和smoothness loss起到了相互对抗的效果:前者根据运动方向的不同将点区分开;后者则根据空间中的近邻关系将邻近的点聚合,以抵消潜在的“过度分割”问题。这两项损失函数联合起来,为分割场景中的运动物体提供了充足的监督信号。
3)Invariance loss:我们希望将学习到的运动物体分割充分地泛化到外形相近的静态物体。为此,我们要求物体分割网络在面对处于不同位姿的同一物体时,能够无差别地辨别(分割)该物体。具体来说,我们对同一场景施加两个不同的空间变换(旋转,平移和缩放)v1和v2,使得场景中物体的位姿都发生变化,然后我们要求场景的分割结果保持不变:
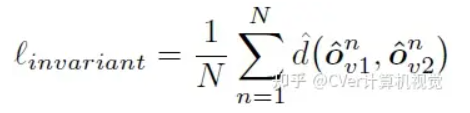
Invariance loss能有效地将从运动物体学习到的分割策略泛化到不同位姿的静态物体。
3.3
Iterative Optimization
当我们从运动信息中学会了分割物体,理论上我们可以用估计出的物体分割来提升对运动(场景流)的估计质量,随后从更准确的运动信息中更好地学习分割物体。为实现这一目标,我们提出了如下图4所示的“物体分割-运动估计”迭代优化算法:初始阶段,我们通过FlowStep3D网络估计运动。在每一轮中,我们首先从当前估计出的运动信息学习物体分割;随后用我们的Object-aware ICP算法,基于估计出的物体分割来提升对运动的估计质量,将改善后的运动估计送入下一轮。
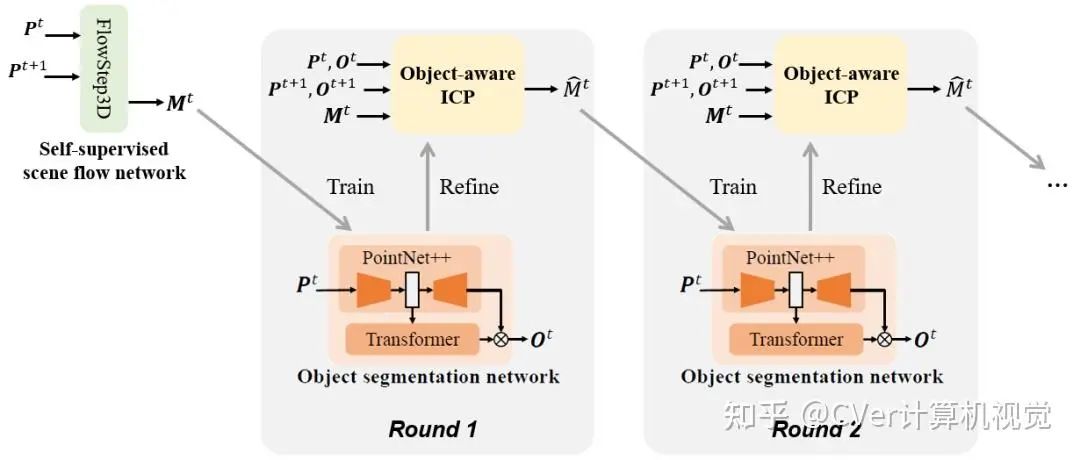
Figure 4 “物体分割-运动估计”迭代优化算法示意图
在迭代过程中用到的Object-aware ICP算法,可以看作传统的ICP算法向多物体场景的拓展,算法的具体细节可以参考原文附录A.2。
04
Experiments
Evaluation on Synthetic Datasets
我们首先在SAPIEN数据集和我们在自己合成的OGC-DR / OGC-DRSV数据集上评估了OGC对物体部件分割和室内物体分割任务的效果。从下面两个表格可以看到,在高质量的合成数据集上,OGC不仅领先于传统的无监督运动分割和聚类方法,还达到了接近甚至超越全监督方法的效果。
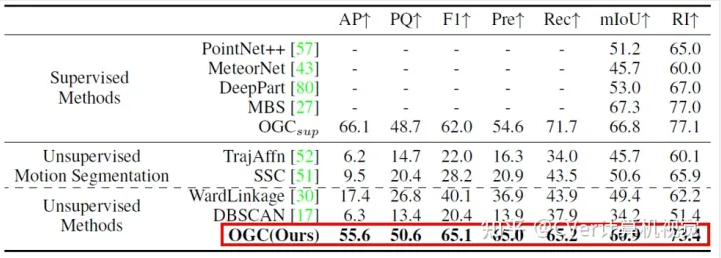
Figure 5 不同方法在SAPIEN数据集上的定量结果对比

Figure 6不同方法在OGC-DR/OGC-DRSV数据集上的定量结果对比
Evaluation on Real-World Outdoor Datasets
接下来,我们评估OGC在极具挑战性的室外物体分割任务上的表现。首先,我们在KITTI Scene Flow(KITTI-SF)数据集上进行评估。KITTI-SF包含200对点云用于训练,200单帧点云用于测试。实验结果如下表所示:我们的方法达到了与全监督方法接近的优异性能。
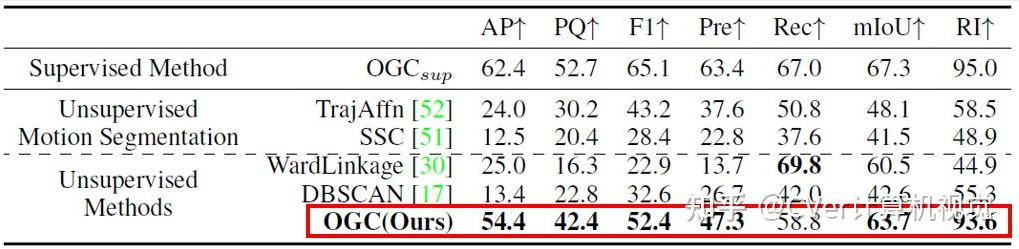
Figure 7不同方法在KITTI-SF数据集上的定量结果对比
在实际应用中,有时无法收集到包含运动的序列数据,但我们可以将相似场景中训练出的OGC模型泛化过来。这里,我们将上述KITTI-SF数据集上训练好的OGC模型拿来,直接用于分割KITTI Detection(KITTI-Det)和SemanticKITTI数据集中的单帧点云。注意:KITTI-Det和SemanticKITTI中的点云都是通过雷达采集的,比KITTI-SF中双目相机采集的点云稀疏很多,且KITTI-SF(3769帧)和SemanticKITTI(23201帧)的数据规模都远远大于KITTI-SF。实验结果如下面两张表所示:我们在KITTI-SF上训练的OGC模型能直接泛化到稀疏的雷达点云数据,并取得与全监督方法接近的效果。
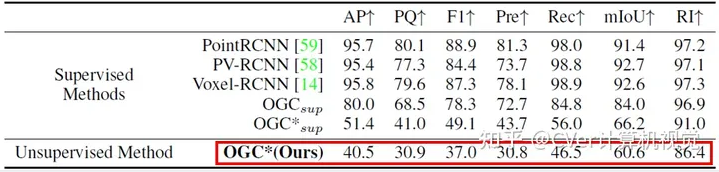
Figure 8在KITTI-Det数据集上的定量结果对比(*表示模型在KITTI-SF上训练)
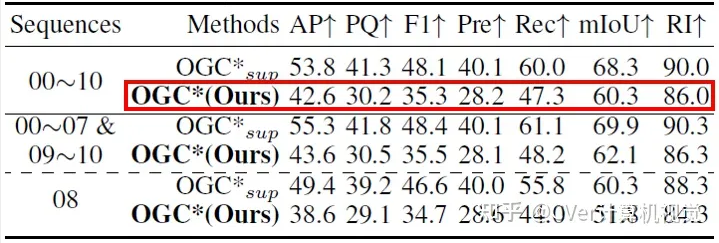
Figure 9在SemanticKITTI数据集上的定量结果对比(*表示模型在KITTI-SF上训练)
Ablation Studies
我们在SAPIEN数据集上对OGC框架的核心技术进行了消融实验:
1)损失函数设计:从下方图表可以看到,OGC的三个损失函数结合使用能带来最好的效果。如果移除dynamic loss,所有点会被分到同一物体;如果移除smoothness loss,会出现“过度分割”的问题。
2)迭代优化算法:可以看到,随着迭代轮数增多,更高质量的运动估计确实带来了更好的物体分割表现。
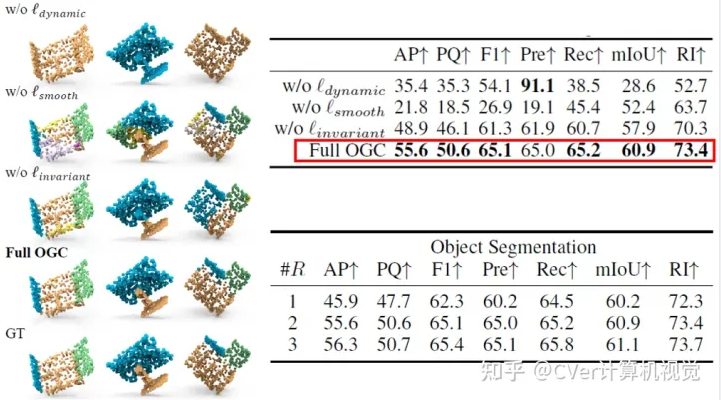
Figure 10 在SAPIEN数据集上的消融实验(图-左和表-上:损失函数设计;表下:迭代优化算法)
05
Summary
最后总结一下,我们提出了第一个点云上的无监督3D物体分割框架。这个框架的核心是一组基于物体几何形状一致性的损失函数,利用运动信息有效地监督物体分割。我们的方法在完全无标注的点云序列上训练,训练后可以直接用于分割单帧点云,在多种任务场景下都展示出了非常好的效果。未来OGC还可以进一步拓展:
1)当有少量标注数据时,如何将无监督的OGC模型与这些标注数据结合取得更好的性能;
2)当有多帧作为输入时,如何利用多帧信息更好地分割。
References
[1] U. M. Nunes and Y. Demiris. 3D motion segmentation of articulated rigid bodies based on RGB-D data. BMVC, 2018.
[2] C. Jiang, D. P. Paudel, D. Fofi, et al. Moving Object Detection by 3D Flow Field Analysis. TITS, 22(4):1950–1963, 2021.
[3] S. A. Baur, D. J. Emmerichs, F. Moosmann, et al. SLIM: Self-Supervised LiDAR Scene Flow and Motion Segmentation. ICCV, 2021.
[4] B. Cheng, A. G. Schwing, and A. Kirillov. Per-Pixel Classification is Not All You Need for Semantic Segmentation. NeurIPS, 2021.
[5] Y. Kittenplon, Y. C. Eldar, and D. Raviv. FlowStep3D: Model Unrolling for Self-Supervised Scene Flow Estimation. CVPR, 2021.
提
醒
点击“阅读原文”跳转到58:41可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1000多位海内外讲者,举办了逾500场活动,超500万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!