链路追踪Sleuth+Zipkin.跟学笔记
学习目标

随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要可以帮助理解系统行为于分析性能问题的工具以便发生故障的时候,能够快速定位和解决问题。在复杂的微服务架构系统中,几乎每个前端请求都会形成一个复杂的分布式服务调用链路。
一个请求完整调用链可能如下图所示:

本视频跟学 优极限_2021年链路追踪教学-SpringCloud全家桶之Sleuth+Zipkin教程-核心知识点精讲
希望各位多多支持原视频,本篇文章是学习完视频之后,笔记的提炼。
一、什么是链路追踪
“链路追踪”一词是在2010年提出的,当时谷歌发布了一篇Dapper论文: Dapper, 大规模分布式系统的跟踪系统,介绍了谷歌自研的分布式链路追踪的实现原理,还介绍了他们是怎么低成本实现对应用透明的。
论文(中文翻译)
单纯的理解链路追踪,就是指一次任务的开始到结束, 期间调用的所有系统及耗时(时间跨度)都可以完整记录下来。
实Dapper一开始只是一个独立的调用链路追踪系统, 后来逐渐演化成了监控平台,并且基于监控平台孕育出了很多工具,比如实时预警、过载保护、 指标数据查询等。
除了谷歌的Dapper,还有一些其他比较有名的产品, 比如阿里的鹰眼、大众点评的CAT、Twitter 的Zipkin、Naver (著名社交软件LINE的母公司)的PinPoint以及国产开源的SkyWalking (已贡献给Apache)等。
二、什么是Sleuth
Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案。兼容Zipkin, HTrace 和其他基于日志的追踪系统,例如ELK (Elasticsearch. Logstash、 Kibana) 。
Spring Cloud Sleuth提供了以下功能:
链路追踪:通过Sleuth可以很清楚的看出一个请求都经过了那些服务,可以很方便的理清服务间的调用关系等。性能分析:通过Sleuth可以很方便的看出每个采样请求的耗时,分析哪些服务调用比较耗时,当服务调用的耗时随着请求量的增大而增大时,可以对服务的扩 容提供定的提醒。数据分析,优化链路:对于频繁调用一个服务,或并行调用等,可以针对业务做一些优化措施。可视化错误:对于程序未捕获的异常,可以配合Zipkin查看。
三、专业术语
1. Span
基本工作单位,一次单独的调用链可以称为一个Span, Dapper 记录的是Span的名称,以及每个Span的ID和父ID,重建在一次追踪过程中不同Span之间的关系,图中一个矩形框就是一个 Span,前端从发出请求到收到回复就是一个Span。
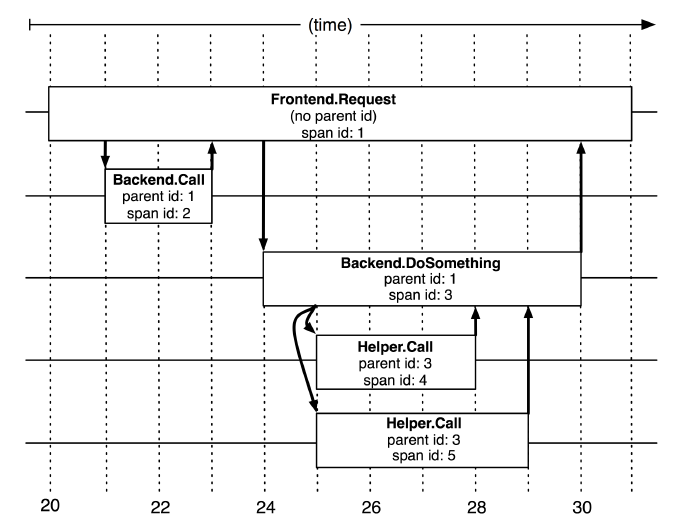
开始跟踪的初始跨度称为root span 。该跨度的ID的值等于跟踪ID。
上图比较抽象,我们画一个容易理解的图,如下:

Dapper录了span名称,以及每个span的ID和父spanID,以重建在一次追踪过程中不同span之间的关系。如果一个span没有父ID被称为root span。所有span都挂在一个特定的Trace上,也共用一个trace id。
图示为Help.Call微服务模块展开的具体结构。
2. Trace
一列Span组成的树状结构,一个Trace认为是一次完整的链路, 内部包含n多个Span。Trace 和Span存在一对多的关系,Span与Span之间存在父子关系。
举个例子:户端调用服务A、服务B、服务C、服务F,而每个服务例如C就是一个Span,如果在服务C中另起线程调用了D,那么D就是C的子Span,如果在服务D中另起线程调用了E,那么E就是D的子Span,这个C->D->E的链路就是条Trace。如果链路追踪系统做好了,链路数据有了,借助前端解析和渲染工具,可以达到下图中的效果:

我们后面要学习的zipkin的可视化界面如下:

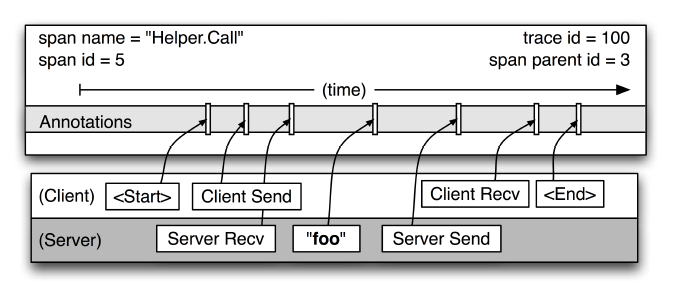
3. Annotation
用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束。
- cs-Client Sent: 客户端发起一个请求,这个annotation描述了这个span的开始;
- sr-Server Received:服务端获得请求并准备开始处理它,如果sr减去cs时间戳便可得到网络延迟;
- ss-Server Sent:求处理完成(当请求返回客户端),如果 ss减去sr时间戳便可得到服务端处理请求需要的时间;
- cr- Client Received: 表示span结束户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间。
公式:
网络延迟 = sr - cs
服务端处理请求需要的时间 = ss - sr
客户端从服务端获取回复的所有所需时间 = cr - cs
四、实现原理
如果想知道一个接口在哪个环节出现了问题,就必须清楚该接口调用了哪些服务,以及调用的顺序,如果把这些服务串起来,看起来就像链条一样,我们称其为调用链。

想要实现调用链,就要为每次调用做个标识,然后将服务按标识大小排列,可以更清晰地看出调用顺序,我们暂且将该标识命名为spanid。

实际场中,我们需要知道某次请求调用的情况,所以只有spanid还不够,得为每次请求做个唯一标识, 这样才能根据标识查出本次请求调用的所有服务,而这个标识我们命名为traceid。

现在根据spanid可以轻易地知道被调用服务的先后顺序,但无法体现调用的层级关系,正如下图所示,多个服务可能是逐级调用的链条,也可能是同时被同一个服务调用。

所以应该每次都记录下是谁调用的,我们用parentid 作为这个标识的名字。

到现在,已经知道调用顺序和层级关系了,但是接口出现问题后,还是不能找到出问题的环节,如果某个服务有问题,那个被调用执行的服务一定耗时很长, 要想计算出耗时,上述的三个标识还不够, 还需要加上时间戳,时间戳可以更精细一点,精确到微秒级。
增加请求发起的timestamp。

只记录发起调用时的时间戳还算不出耗时,要记录下服务返回时的时间戳,有始有终才能算出时间差,既然返回的也记了,就把上述的三个标识都记一下吧, 不然区分不出是谁的时间戳。

虽然能计算出从服务调用到服务返回的总耗时,但是这个时间包含了服务的执行时间和网络延迟,有时候我们需要区分出这两
类时间以方便做针对性优化。那如何计算网络延迟呢?我们可以把调用和返回的过程分为以下四个事件。
- Client Sent简称cs,客户端发起调用请求到服务端。
- Server Received简称sr.指服务端接收到了客户端的调用请求。
- Server Sent简称ss,指服务端完成了处理,准备将信息返给客户端。
- Client Received简称cr,指客F端接收到了服务端的返回信息。

假如在这四个事件发生时记录下时间戳,就可以轻松计算出耗时,比如:
sr减去cs就是调用时的网络延迟
ss 减去sr就是服务执行时间
cr减去ss就是服务响应的延迟
cr减cs就是整个服务调用执行的时间

其实span内除了记这几个参数之外,还可以记录一其他信息,比如发起调用服务名称、被调服务名称、返回结果、IP、调用服务的名称等,最后,我们再把相同parentid的span信息合成一个大的span块,就完成了一个完整的调用链。
以上原型图来自张以诺的绘制。
五、环境准备
- eureka-server :注册中心
- eureka-server02 :注册中心
- gateway-server : Spring Cloud Gateway服务网关
- product-service :商品服务,提供了根据主键查询商品接口http://localhost:7870/product/{id} 根据多个主键查询商品接口http://localhost :7870/product/listByIds
- order-service :订单服务,提供了根据主键查询订单接口http://localhost :9090/order/{id}且订单服务调用商品服务。
课件资料:
百度云-课件
提取码:c8cp

在IDEA中打开

导入项目后如下:

然后顺序启动:
eureka-server
eureka-server2
gateway
order-service
product-service
启动eureka-server和eureka-server2的时候增加配置
register-with-eureka: false #是否将自己注册到eureka中
fetch-registry: false #是否从eureka中拉去信息列表

这里注意,如果出现子项目@SpringBootApplication报红问题

解决方案:右键-maven-reload project

验证Eureka是否启动成功
访问
http://localhost:8761/

验证product-service服务是否启动成功
访问
http://localhost:7070/product/listByIds?id=1&id=2

验证order-service服务是否启动成功
访问
http://localhost:9090/order/1

验证网关gateway是否启动成功
访问
http://localhost:9000/order-service/order/1

访问
http://localhost:9000/product-service/product/listByIds?id=1&id=2

发现都没有问题
六、入门案例
在需要进行链路追踪的项目中(服务网关、商品服务、订单服务)添加 spring-cloud-starter-sleuth 依赖。
6.1.添加依赖
<!-- spring cloud sleuth 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
6.2 记录日志
在需要链路追踪的项目中(服务网关、商品服务、订单服务)添加 logback.xml 日志文件,内容如下(logback 日志的输出级别需要是 DEBUG 级别):
注意修改
< property name=“log.path”
value=“${catalina.base}/gateway-server/logs”/ >
中项目名称。
日志核心配置:
%d{yyyy-MM-dd HH:mm:ss.SSS}
[${applicationName},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-}] [%thread]%-5level %logger{50} - %msg%n
注意:资料中提供的日志文件有编码问题,直接拷贝我这里的即可
logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,
则低于WARN的信息都不会输出 -->
<!-- scan: 当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod: 设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。
当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug: 当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默
认值为false。 -->
<configuration scan="true" scanPeriod="10 seconds">
<!-- 日志上下文名称 -->
<contextName>my_logback</contextName>
<!-- name的值是变量的名称,value的值是变量定义的值。通过定义的值会被插入到logger上下文
中。定义变量后,可以使“${}”来使用变量。 -->
<property name="log.path" value="${catalina.base}/gateway-server/logs"/>
<!-- 加载 Spring 配置文件信息 -->
<springProperty scope="context" name="applicationName"
source="spring.application.name" defaultValue="localhost"/>
<!-- 日志输出格式 -->
<property name="LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS}
[${applicationName},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-}] [%thread] %-5level
%logger{50} - %msg%n"/>
<!--输出到控制台-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--此日志appender是为开发使用,只配置最底级别,控制台输出的日志级别是大于或等于此级
别的日志信息-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 输出到文件 -->
<!-- 时间滚动输出 level为 DEBUG 日志 -->
<appender name="DEBUG_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${log.path}/log_debug.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset> <!-- 设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 日志归档 -->
<fileNamePattern>${log.path}/debug/log-debug-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>15</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录debug级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>DEBUG</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 时间滚动输出 level为 INFO 日志 -->
<appender name="INFO_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${log.path}/log_info.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 每天日志归档路径以及格式 -->
<fileNamePattern>${log.path}/info/log-info-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>15</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录info级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 时间滚动输出 level为 WARN 日志 -->
<appender name="WARN_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${log.path}/log_warn.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}/warn/log-warn-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<!-- 每个日志文件最大100MB -->
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>15</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录warn级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>WARN</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 时间滚动输出 level为 ERROR 日志 -->
<appender name="ERROR_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${log.path}/log_error.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}/error/log-error-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>15</maxHistory>
<!-- 日志量最大 10 GB -->
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy>
<!-- 此日志文件只记录ERROR级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 对于类路径以 com.example.logback 开头的Logger,输出级别设置为warn,并且只输出到控
制台 -->
<!-- 这个logger没有指定appender,它会继承root节点中定义的那些appender -->
<!-- <logger name="com.example.logback" level="warn"/> -->
<!--通过 LoggerFactory.getLogger("myLog") 可以获取到这个logger-->
<!--由于这个logger自动继承了root的appender,root中已经有stdout的appender了,自己这边
又引入了stdout的appender-->
<!--如果没有设置 additivity="false" ,就会导致一条日志在控制台输出两次的情况-->
<!--additivity表示要不要使用rootLogger配置的appender进行输出-->
<logger name="myLog" level="INFO" additivity="false">
<appender-ref ref="CONSOLE"/>
</logger>
<!-- 日志输出级别及方式 -->
<root level="DEBUG">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="DEBUG_FILE"/>
<appender-ref ref="INFO_FILE"/>
<appender-ref ref="WARN_FILE"/>
<appender-ref ref="ERROR_FILE"/>
</root>
</configuration>
这里注意项目名称和日志名称一致



6.3 访问
访问之前,添加日志的项目要重启

重启之后发现生成了文件

访问:
http://localhost:9000/order-service/order/1
结果如下:
服务网关打印信息:

[gateway-server,f82de2d68493f0cb,f82de2d68493f0cb]
商品服务打印信息

[product-service,f82de2d68493f0cb,93fc5e739328a597]
订单服务打印信息
[order-service,f82de2d68493f0cb,a94f977efaf08f05]

通过打印信息可以得知,
整个链路的 traceId为:f82de2d68493f0cb,
spanId 为:93fc5e739328a597 和 a94f977efaf08f05 。
查看日志文件并不是一个很好的方法,当微服务越来越多日志文件也会越来越多,查询工作会变得越来越麻烦,Spring 官方推荐使用Zipkin 进行链路跟踪。Zipkin 可以将日志聚合,并进行可视化展示和全文检索。
七、使用Zipkin进行链路跟踪
7.1. 什么是 Zipkin

ZIPKIN官网
ZIPKIN是 Twitter 公司开发贡献的一款开源的分布式实时数据追踪系统(Distributed TrackingSystem),基于 Google Dapper 的论文设计而来,其主要功能是聚集各个异构系统的实时监控数据。
它可以收集各个服务器上请求链路的跟踪数据,并通过 Rest API 接口来辅助我们查询跟踪数据,实现对分布式系统的实时监控,及时发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开发的 API 接口之外,它还提供了方便的 UI 组件,每个服务向 Zipkin 报告计时数据,Zipkin 会根据调用关系生成依赖关系图,帮助我们直观的搜索跟踪信息和分析请求链路明细。Zipkin 提供了可插拔数据存储方式:In-Memory、MySql、Cassandra 以及 Elasticsearch。
分布式跟踪系统还有其他比较成熟的实现,例如:Naver 的 PinPoint、Apache 的 HTrace、阿里的鹰眼 Tracing、京东的 Hydra、新浪的 Watchman,美团点评的 CAT,Apache 的 SkyWalking 等。

7.2 工作原理

共有四个组件构成了 Zipkin:
- Collector :收集器组件,处理从外部系统发送过来的跟踪信息,将这些信息转换为 Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
- Storage :存储组件,处理收集器接收到的跟踪信息,默认将信息存储在内存中,可以修改存储策略使用其他存储组件,支持 MySQL,Elasticsearch 等。
- Web UI :UI 组件,基于 API 组件实现的上层应用,提供 Web 页面,用来展示 Zipkin 中的调用链和系统依赖关系等。
- RESTful API :API 组件,为 Web 界面提供查询存储中数据的接口。
Zipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端,客户端也就是微服务的应用,客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。发送的方式有两种,一种是消息总线的方式如 RabbitMQ 发送,还有一种是 HTTP 报文的方式发送。
7.3 服务端部署
服务端是一个独立的可执行的 jar 包,官方下载地址:ZIPKIN下载地址,使用 java -jar zipkin.jar 命令启动,端口默认为9411 。我们下载的 jar 包为:zipkin-server-2.20.1-exec.jar。
资料中带这个jar包:

启动命令如下:
java -jar zipkin-server-2.20.1-exec.jar

启动后如下:

访问:
http://localhost:9411/
结果如下:
目前最新版界面。

之前旧版本界面。

7.4客户端部署
(1). 添加依赖
在需要进行链路追踪的项目中(服务网关、商品服务、订单服务)添加 spring-cloud-starter-zipkin 依赖。
<!-- spring cloud zipkin 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
(2). 配置文件
在需要进行链路追踪的项目中(服务网关、商品服务、订单服务)配置 Zipkin 服务端地址及数据传输方式。默认即如下配置。
spring:
zipkin:
base-url: http://localhost:9411/ # 服务端地址
sender:
type: web # 数据传输方式,web 表示以 HTTP 报文的形式向服务端
sleuth:
sampler:
probability: 1.0 # # 收集数据百分比,默认 0.1(10%)
这里type:web 是按照Http报文的方式发送的,后续会更改为其它方式。

更改玩之后重启项目
现在的调用链路如下:
client -> gateway -> order-service -> product-service
(3). 访问
访问:
http://localhost:9000/order-service/order/1
结果如下:

新版操作如下:访问:
http://localhost:9411/
根据时间过滤点击 搜索 结果如下:

点击后结果如下:

我们多访问几次订单或者库存,这里zipkin也会产生几条数据

点击对应的追踪信息可查看请求链路详细。

查看时间戳

还可以下载为JSON的数据

支持条件查询

通过依赖可以查看链路中服务的依赖关系。而且还有服务调度的动态展示,有个小球移动,非常人性化。

旧版操作如下:
访问:
http://localhost:9411/
点击查找结果如下:

点击对应的追踪信息可查看请求链路详细。

通过依赖可以查看链路中服务的依赖关系。

而目前我们的所有配置,只要重启都没有了,那我们就需要存储追踪服务。
7.5 存储追踪数据
Zipkin Server 默认存储追踪数据至内存中,这种方式并不适合生产环境,一旦 Server 关闭重启或者服务崩溃,就会导致历史数据消失。Zipkin 支持修改存储策略使用其他存储组件,支持 MySQL,Elasticsearch 等。
7.5.1 MySQL
(1).数据库脚本
打开 MySQL 数据库,创建 zipkin 库,执行以下 SQL 脚本。
官网地址:官网地址
脚本在资料中有,直接去mysql中运行即可

创建数据库
CREATE DATABASE zipkin;
USE zipkin;
之后执行脚本,出现3个表

(2). 部署 Zipkin 服务端
这里就不能通过jar的默认形式直接启动服务端了,而是要添加启动参数,重新部署服务端:
官网地址:Zipkin服务端用于MySql
java -jar zipkin-server-2.20.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=root --MYSQL_DB=zipkin

(3). 测试
访问:
http://localhost:9000/order-service/order/1
查看数据库结果如下:

在 MySQL 模式下,每次启动服务端时,服务端会从数据库加载链路信息展示至 Web 界面。
我们用CTRL + C,esc 退出Zipkin,然后此时访问zipkin服务端,发现无法访问,那之前的数据丢失了吗,我们重启zipkin服务端看看

访问
http://localhost:9411/zipkin/
发现因为保存到了mysql中之前的访问信息并没有丢失

7.5.2 RabbitMQ
之前的课程中我们已经学习过 RabbitMQ 的详细使用,这里不再过多赘述,直接开启使用即可。
目前的链路模式是:
client
(1).启动 RabbitMQ 服务器
开启虚拟机,通过以下命令启动 RabbitMQ 服务端。
systemctl start docker
docker start mq
访问
ip:15672
进入mq的图形界面,发现此时没有队列

(2).部署 Zipkin 服务端
添加启动参数,重新部署服务端:
官网地址:官网部署-mq
java -jar zipkin-server-2.20.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=root --MYSQL_DB=zipkin --RABBIT_ADDRESSES=192.168.10.101:5672 --RABBIT_USER=guest --RABBIT_PASSWORD=guest --RABBIT_VIRTUAL_HOST=/ --RABBIT_QUEUE=zipkin
启动参数中包含 MySQL 和 RabbitMQ 的配置,实现基于 MQ 并存储链路信息至 MySQL,如下图:

(3).查看队列
访问:http://192.168.10.101:15672/#/queues 可以看到已经创建好了 zipkin 队列。

这里为了看见消息消费的过程,我们停止服务端,并且清空mysql中zipkin数据库的表。


(4).客户端添加依赖
官网文档:官方文档
在网关、订单服务、产品服务都添加
<!-- 消息队列通用依赖 -->
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
(5).客户端配置文件
application.yml
spring:
application:
name: gateway-server # 应用名称
cloud:
gateway:
discovery:
locator:
# 是否与服务发现组件进行结合,通过 serviceId 转发到具体服务实例。
enabled: true # 是否开启基于服务发现的路由规则
lower-case-service-id: true # 是否将服务名称转小写
zipkin:
base-url: http://localhost:9411/ # 服务端地址
sender:
# ype: web # 数据传输方式,web 表示以 HTTP 报文的形式向服务端
type: rabbit # 数据传输方式,web 表示以 HTTP 报文的形式向服务端
sleuth:
sampler:
probability: 1.0 # # 收集数据百分比,默认 0.1(10%)
rabbitmq:
host: 192.168.10.101
port: 5672
username: guest
password: guest
virtual-host: /
listener:
direct:
retry:
enabled: true
max-attempts: 5
initial-interval: 5000
simple:
retry:
enabled: true
max-attempts: 5
initial-interval: 5000

配置完后重启服务
(6).测试
先关闭 Zipkin 服务端,访问:
http://localhost:9000/order-service/order/1
客户端已将链路追踪数据写入队列当中:
启动 Zipkin 服务端后,队列中消息被堆积

此时我们再此启动Zipkin的服务端
java -jar zipkin-server-2.20.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=root --MYSQL_DB=zipkin --RABBIT_ADDRESSES=192.168.10.101:5672 --RABBIT_USER=guest --RABBIT_PASSWORD=guest --RABBIT_VIRTUAL_HOST=/ --RABBIT_QUEUE=zipkin
启动后队列中消息被消费

链路追踪数据被存储至 MySQL。

7.5.3 ElasticSearch
之前的课程中我们已经学习过 Elasticsearch 的详细使用,这里不再过多赘述,直接开启使用即可。
(1).启动 Elasticsearch 集群
启动集群,访问:
http://192.168.10.101:9200/
结果如下:

启动 head 插件,访问:http://192.168.10.101:9100/ 结果如下:

(2).部署 Zipkin 服务端
添加启动参数,重新部署服务端:
官网地址:Zipkin服务端
java -jar zipkin-server-2.20.1-exec.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=http://192.168.10.101:9200/,http://192.168.10.102:9200/,http://192.168.10.103:9200/ --RABBIT_ADDRESSES=192.168.10.101:5672 --RABBIT_USER=guest --RABBIT_PASSWORD=guest --RABBIT_QUEUE=zipkin
启动参数中包含 Elasticsearch 和 RabbitMQ 的配置,实现基于 MQ 并存储链路信息至Elasticsearch。
(3).查看索引库
访问:http://192.168.10.101:9100 可以看到已经创建好了 zipkin 索引库。

(4).客户端添加依赖
官网文档:官方文档
<!-- 消息队列通用依赖 -->
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
(5).客户端配置文件
spring:
zipkin:
base-url: http://localhost:9411/ # 服务端地址
sender:
type: rabbit
rabbitmq:
queue: zipkin # 队列名称
rabbitmq:
host: 192.168.10.101 # 服务器 IP
port: 5672 # 服务器端口
username: guest # 用户名
password: guest # 密码
virtual-host: / # 虚拟主机地址
listener:
direct:
retry:
enabled: true # 是否开启发布重试
max-attempts: 5 # 最大重试次数
initial-interval: 5000 # 重试间隔时间(单位毫秒)
simple:
retry:
enabled: true # 是否开启消费者重试
max-attempts: 5 # 最大重试次数
initial-interval: 5000 # 重试间隔时间(单位毫秒)
sleuth:
sampler:
probability: 1.0 # 收集数据百分比,默认 0.1(10%)
(6).测试
访问:
http://localhost:9000/order-service/order/1
查看索引库结果如下:

八、使用ELK分析追踪数据
ELK 是 elastic 公司提供的一套完整的日志收集以及展示的解决方案,是三个产品的首字母缩写,分别是 ElasticSearch、Logstash 和 Kibana。
- Elasticsearch 简称 ES:实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
- Logstash:具有实时传输能力的数据收集引擎,将各种各样的数据进行收集、解析,并发送给ES。使用 Ruby 语言编写。
- Kibana:为 Elasticsearch 提供了分析和可视化的 Web 平台。它可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度表格、图形。
- Beats:一组轻量级采集程序的统称,使用 Go 语言编写。以下是 elastic 官方支持的 5 种 beats,事实上,伟大的开源力量早已创造出大大小小几十甚至上百种 beats,只有你没想到的,没有beats 做不到的:
- Filebeat:进行文件和目录采集,主要用于收集日志数据。
- Winlogbeat:专门针对 Windows 的 event log 进行的数据采集。
- Metricbeat:进行指标采集,指标可以是系统的,也可以是众多中间件产品的,主要用于监控系统和软件的性能。
- Packetbeat:通过网络抓包、协议分析,对一些请求响应式的系统通信进行监控和数据收集,可以收集到很多常规方式无法收集到的信息。
- Heartbeat:系统间连通性检测,比如 icmp,tcp,http 等系统的连通性监控。
8.1 环境准备
之前的课程中我们已经学习过 ELK 的详细使用,这里不再过多赘述,直接开启使用即可。文中使用的 ELK 版本统一为 7.5.2。
- 本文使用的 Elasticsearch 集群地址为:
192.168.10.101:9200
192.168.10.102:9200
192.168.10.103:9200 - 本文使用的 Logstash 的地址为:
192.168.10.101:9250 - 本文使用的 Kibana 的地址为:
192.168.10.101:5601
Logstash 运行时指定的配置文件 log-to-es.conf 内容如下:
# 数据入口
input {
tcp {
mode => "server"
host => "192.168.10.101"
port => 9250
}
}
# 处理数据
filter {
# 获取 @timestamp 的值并加上 8*60*60(北京时间比 logstash 中@timestamp 晚了 8 小
时),然后赋值给变量 timestamp。
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime +
8*60*60)"
}
# 将 timestamp 值重新赋值给 @timestamp
ruby {
code => "event.set('@timestamp', event.get('timestamp'))"
}
# 删除变量 timestamp
mutate {
remove_field => ["timestamp"]
}
}
# 数据出口
output {
elasticsearch {
hosts => ["192.168.10.101:9200", "192.168.10.102:9200",
"192.168.10.103:9200"]
index => "applog"
}
}
8.2 添加依赖
在需要进行链路追踪的项目中(服务网关、商品服务、订单服务)添加 logstash-logback-encoder 依赖。
<!-- logstash 编码依赖 -->
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.3</version>
</dependency>
8.3 日志配置
在需要进行链路追踪的项目中(服务网关、商品服务、订单服务)添加 logstash 输出 JSON 格式数据 。
logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="10 seconds">
...
<!-- 为 Logstash 输出 JSON 格式数据 -->
<appender name="LOGSTASH_PATTERN"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!-- 数据输出目的地 -->
<destination>192.168.10.101:9250</destination>
<!-- 日志输出编码 -->
<encoder
class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<!-- 日志输出级别及方式 -->
<root level="DEBUG">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="LOGSTASH_PATTERN"/>
<appender-ref ref="DEBUG_FILE"/>
<appender-ref ref="INFO_FILE"/>
<appender-ref ref="WARN_FILE"/>
<appender-ref ref="ERROR_FILE"/>
</root>
...
</configuration>
8.4 查看索引库
访问:http://192.168.10.101:9100 可以看到已经创建好了 applog 索引库。

8.5测试
访问:http://localhost:9000/order-service/order/1 查看索引库结果如下:

访问:http://192.168.10.101:5601/ Kibana 首页

添加 applog 索引库。

不使用时间过滤器。

搜索 gateway 结果如下:
