神经网络术语
感受野
感受野是指在神经网络中,一个神经元所能感受到的输入信号的区域大小。感受野的大小决定了网络对于输入图像的理解范围,从而影响到网络对图像的理解和表示。
对于一个卷积神经网络,可以通过计算每一层的卷积核大小和步长,以及池化层的大小和步长,来计算每个像素点的感受野大小。由于感受野随着网络深度的增加而增加,通常只需要计算前几层的感受野即可。
感受野图形分析即为分析每一层神经元的感受野范围,并可视化为图形。通常情况下,感受野范围越大的神经元可以理解更多的全局信息,而感受野范围较小的神经元则更关注局部信息。因此,在设计网络结构时需要综合考虑不同层次的感受野大小,以便网络能够更好地对图像进行理解和分类。
锚框
锚框(anchor box)是一种用于目标检测的辅助工具,其作用是在图像中生成多个固定大小和宽高比的矩形框,用来匹配目标物体。
在目标检测中,锚框通常与滑动窗口或者特征图上的某些位置相对应,以便在每个位置检测出物体。锚框通常被定义为一组基准框(base box),这些基准框可以通过在不同位置和大小的图像上进行缩放和平移得到。通过在不同大小和宽高比的锚框上进行检测,可以有效地适应不同大小和形状的物体。在目标检测中,锚框通常用来定义物体的位置和尺寸,并在训练过程中用于计算目标物体与锚框之间的匹配程度。
上采样
上采样是将特征图的尺寸放大,通常通过插值(interpolation)来实现。
上采样操作通常与卷积操作组合使用,用于将低分辨率的特征图恢复到原始图像大小。上采样操作也可以增加感受野,从而提高网络对目标的识别能力。
在目标检测中,上采样通常用于将低分辨率的特征图恢复到原始图像大小,以便进行目标定位和检测。
下采样
下采样通常被称为池化(pooling),是将输入特征图中的某一区域合并为一个值。
常用的池化操作有最大池化(max pooling)和平均池化(average pooling)。池化操作可以减少特征图的尺寸,从而减少计算量,同时提取特征。
在目标检测中,下采样通常用于从原始图像中提取特征,,以便进行目标定位和检测。
卷积层
卷积层(Convolutional Layer)是卷积神经网络的核心组成部分。它使用一组可学习的滤波器(也称为卷积核)来扫描输入数据,并在每个位置上计算点积。卷积层通常用于提取输入数据的特征。
池化层
池化层(Pooling Layer)是一种降采样操作,用于减小数据的维度。它通过在数据的局部区域上计算统计量(例如最大值或平均值)来减小数据的大小。池化层通常用于降低卷积层输出的维度,并增强对平移不变性的识别能力。
最大池化
最大池化是将输入特征图划分为若干个区域,然后在每个区域内取最大值作为输出。
首先将输入特征图划分为多个大小相等的矩形区域,每个矩形区域内的像素值取最大值作为该区域的输出,最终将所有区域的输出拼接起来作为池化层的输出。这样做的作用是可以减小特征图的空间大小,同时可以提取出最强的特征,因为在每个矩形区域内只选取一个最大值,而且最大值通常是在局部特征明显的位置上出现的。
最大池化通常用于卷积神经网络中,以降低特征图的空间分辨率,并帮助网络提取具有空间不变性的特征。
平均池化
平均池化(Average Pooling)是一种池化操作,用于减小输入张量的空间大小。它的操作是将输入张量的每个子区域取平均值,生成一个新的张量。这个过程可以看作是在输入张量上进行了降采样操作,减小了空间分辨率,同时保留了输入张量的通道数。
平均池化通常用于卷积神经网络中,在特征提取的过程中进行下采样操作,从而减小特征图的大小。常见的平均池化操作是2x2的池化窗口,步幅为2,这样可以将特征图的大小减半,同时保留了输入特征图的通道数。主要优点是它不会引入太多的参数,因为它没有可训练的权重,只是一个固定的算子。它还可以在一定程度上防止过拟合,因为它可以对输入特征图进行降采样操作,从而减少特征图中的冗余信息。
全局平均池化
全局平均池化常用于卷积神经网络的最后一层,将最后一层的特征图转化为一个固定长度的向量,以便进行分类等任务。
全局平均池化的操作非常简单,就是对整个特征图进行平均池化。具体地,假设最后一层的特征图的大小为 H × W × C H \times W \times C H×W×C,其中 H H H 表示高度, W W W 表示宽度, C C C 表示通道数,那么全局平均池化的输出就是一个 C C C 维的向量,第 i i i 维的值等于特征图中所有位置的第 i i i 个通道的值的平均值。
全局平均池化可以看做是一种无参数的特征压缩操作,因此可以有效地降低特征图的维度,并且不会引入额外的参数,因此非常适合用于卷积神经网络的最后一层。
最小池化
最小池化与最大池化和平均池化类似,也是对输入特征图进行区域采样和下采样操作。在最小池化中,对于每个池化区域,取该区域内所有元素的最小值作为该区域的输出值。
最小池化与最大池化和平均池化的区别在于,最小池化会保留输入区域内最小的特征值,而忽略其他特征值。因此,最小池化在一些特定的应用场景中可能会比最大池化和平均池化更有效。比如在图像中检测边缘、角点等局部特征时,使用最小池化可以增强这些局部特征并减少噪声的影响。
激活层
激活层(Activation Layer)是一种非线性操作,用于增加神经网络的表达能力。它将输入值传递给一个非线性函数(例如Sigmoid或ReLU),并生成一个新的输出值。激活层通常在卷积层和全连接层之间使用,用于引入非线性变换。
在卷积神经网络中,通常会将多个卷积层、池化层和激活层连接在一起,以构建深度神经网络。
全连接层
全连接层(Fully Connected Layer)是神经网络中一种常见的层类型,通常也称为稠密层(Dense Layer)。它的作用是将前一层的所有神经元都连接到当前层的每一个神经元上,可以看作是多个神经元之间的全连接。
在全连接层中,每个神经元都会对前一层的所有神经元进行加权求和,再通过激活函数进行非线性变换,输出到下一层网络。
全连接层常用于神经网络的最后一层,用于对前面层的特征进行分类或回归。然而,在较深的网络中,全连接层也可能出现在中间的某些层中。
特征金字塔
特征金字塔是一种用于多尺度目标检测的结构,旨在提高目标检测算法对于不同大小目标的检测性能。特征金字塔结构通常由多个尺度的特征图组成,这些特征图在不同的网络层级中提取,从而能够对不同尺度的目标进行检测。
在目标检测中,小目标往往需要更高分辨率的特征图才能被准确检测,而大目标则可以使用低分辨率的特征图进行检测。特征金字塔结构可以通过在不同层级的特征图之间进行上下采样操作,从而提取具有不同尺度的特征图,这些特征图可以在目标检测过程中被有效地利用。
特征金字塔结构有两种常见的实现方式,分别为自下而上和自上而下的方式。
自下而上
自下而上的特征金字塔结构通过在不同层次的特征图上进行卷积和池化操作来获取不同尺度的特征,然后将这些特征图融合起来以得到更加全面的信息。这种方法在处理较小目标时表现较好,但在处理较大目标时存在信息损失的问题。
自上而下
自上而下的特征金字塔结构通过在最高层的特征图上进行上采样操作,然后与低层的特征图进行融合,逐层向下传递融合后的特征图,以得到不同尺度的特征。这种方法能够更好地处理较大目标,但需要消耗较大的计算量。
SPP
SPP是空间金字塔池化,作用是一个实现一个自适应尺寸的输出。
它采用不同大小的池化窗口在不同的尺度下对输入图像进行池化操作,最终将这些池化结果拼接起来,形成一个固定大小的特征向量。具体来说,它将不同大小的特征图均匀划分成若干个不同大小的网格,对每个网格内的特征图进行池化操作,然后将所有池化后的特征向量连接起来作为网络的输入。这样,即使输入图像尺寸不同,也可以得到固定长度的特征向量进行网络训练和推理。SPP模块广泛应用于目标检测、图像分类等任务中,如Fast R-CNN、Faster R-CNN、YoloV3等。
SPPF
SPPF模块是一种在SPP模块基础上进一步改进的模块,用于解决SPP模块中输出特征图尺寸不固定的问题。SPPF模块通过增加一个池化层来控制输出特征图的尺寸,同时保证输入特征图的空间信息不被丢失。
与SPP模块不同的是,SPPF模块中的池化层不仅进行最大池化,还进行平均池化,这样可以更好地捕捉特征的统计信息。在池化层之后,SPPF模块还会添加一层卷积层,用于提取特征。
SPPF模块的输出特征图的尺寸是固定的,这使得它在一些对输出特征图尺寸要求比较严格的任务中表现更好。同时,SPPF模块也保留了SPP模块的优点,可以在不同尺度的特征图上进行特征提取,提高了网络的感受野和特征表达能力。
DarkNet53
DarkNet53是一种卷积神经网络架构,是YOLOv3网络的主干部分。它由53个卷积层和若干个Residual Block组成,是一个较为深层的神经网络。
DarkNet53采用了全新的残差结构,它的设计可以降低梯度消失,从而可以训练比较深的网络。此外,DarkNet53也采用了加宽卷积核的方式,来增加特征图的通道数,从而可以提升网络的表达能力。DarkNet53在YOLOv3中扮演着一个重要的角色,它负责提取输入图像的特征,以便后续的检测任务。由于DarkNet53具有较强的特征提取能力,因此它也可以被用于其他计算机视觉任务,如图像分类、物体识别等。
CSPDarknet
CSPDarknet是Darknet系列网络中的一种,是YoloV5的主干网络之一。CSPDarknet的全称为Cross Stage Partial Darknet,它是在Darknet53的基础上进行改进得到的网络。
CSPDarknet的改进主要在于两个方面:跨阶段连接和局部连接。跨阶段连接指的是在Darknet53的每个阶段中,将输入分为两个部分,并在其中一个部分中添加了一个跨阶段连接,以便增强网络的信息流动。局部连接指的是将输入和输出都分为多个部分,然后对每个部分进行卷积操作,这样可以减少网络的计算量,提高网络的计算效率。
CSPDarknet相较于Darknet53,在减少参数数量的同时,保证了网络的准确率和速度。
Residual Block
Residual Block(残差块)是深度学习中常用的一种网络结构,用于构建深层神经网络。
Residual Block的主要思想是在网络中插入“shortcut connections”(跨层连接),将网络中前一层的输出直接加到当前层的输入中。这样做的好处是可以解决深度神经网络的梯度消失问题,使得训练更加稳定和快速。此外,Residual Block还可以提高网络的拟合能力和泛化能力。
Residual Block的基本结构是:
输入 x x x 经过一个卷积层 f f f 后得到输出 y y y。
在 y y y 上再进行一次卷积,得到另外一个输出 z z z。
将 z z z 和 x x x 相加,得到最终的输出 y + z y+z y+z。
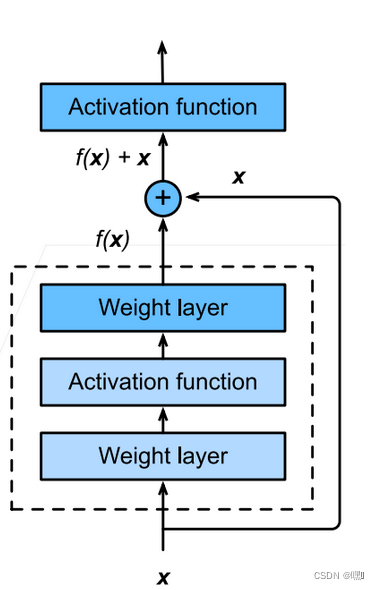
其中, ⊕ \oplus ⊕ 表示逐元素的加法, f f f 是一个卷积层, W W W 和 b b b 分别是卷积层的权重和偏置。 σ \sigma σ 是激活函数,可以是 ReLU、LeakyReLU 等。
在训练过程中,通过反向传播算法求得梯度,并利用梯度下降算法更新参数。这样就可以训练深度神经网络,提高模型的性能和泛化能力。
Shortcut connections
Shortcut connections是Residual Block的一个关键特征,它使得Residual Block能够更加有效地训练深度神经网络。在传统的卷积神经网络中,信息通过多层卷积后逐渐丢失,导致训练深度网络变得困难。Residual Block通过添加shortcut connections,将输入直接连接到输出,使得模型在学习残差时,能够更好地传递信息,加快训练速度,同时提高模型的准确率和泛化能力。
shortcut connections通常是通过在Residual Block中添加一个跨层连接来实现的,具体来说,就是将输入x和输出f(x)相加,然后送入下一层网络中进行处理。shortcut connections可以在各种深度神经网络中使用,包括ResNet、DenseNet等。
ResNet
ResNet主要目的是为了解决神经网络随着深度增加而产生的梯度消失和梯度爆炸的问题。在传统的神经网络中,随着网络层数的增加,网络的性能往往会出现退化现象,即训练误差不降反升。ResNet提出了残差学习的方法,使得网络可以更深更宽,同时获得更高的精度。
ResNet的核心思想是残差学习,即在网络中引入跳跃连接(skip connection)。传统的网络结构是逐层递进,信息必须经过每一层才能到达输出层。而引入跳跃连接后,信息可以在某些层之间直接传递,从而避免了信息的丢失和梯度的消失。
在ResNet中,一个残差块由两个卷积层和一个跳跃连接组成。具体来说,一个残差块的输入先经过一个卷积层,再经过一个ReLU激活函数,然后再经过另一个卷积层。这两个卷积层之间的输出与输入之间的跳跃连接相加,最后再经过一个ReLU激活函数输出。
ResNet的另一个重要的组成部分是残差模块。一个残差模块由多个残差块组成。在ResNet中,共有四个残差模块,分别包括18、34、50和101层四种不同的结构。这些残差模块通过不同的深度和宽度来实现不同的复杂度和性能。
ResNet和DarkNe的区别与联系
-
相同点:
都使用残差块,使得网络能够更好地学习深层次的特征。 都采用了卷积层、BN层和激活函数ReLU。 -
不同点:
DarkNet53相对于ResNet采用更小的卷积核,即3x3的卷积核。 DarkNet53采用了多个不同大小的卷积核,而ResNet使用的是一种更加传统的卷积核设计。 DarkNet53在卷积之前进行了一次1x1的卷积,目的是将输入通道数减小,从而减少计算量。 DarkNet53相对于ResNet采用了更少的层数,但是仍然能够达到较好的效果。
DarkNet53和ResNet都是常用的主干网络,它们各有优劣,选择哪个作为主干网络取决于具体的任务和需求。
DarkNet53是YOLOv3所使用的主干网络,相对于ResNet,它的计算量更小,参数更少,因此可以提供更快的训练速度和推理速度。而且DarkNet53在进行检测任务时的精度表现也比较优秀。
ResNet是ImageNet比赛上的冠军网络,其残差结构可以有效地解决梯度消失问题,可以训练非常深的神经网络,从而提高网络的表达能力和性能。在图像分类、目标检测和语义分割等任务中表现良好,尤其在非常深的网络中表现出色。
conv
"conv"是卷积操作的简称,通常在深度学习中用于提取特征或实现图像处理任务。卷积是一种数学运算,通过滑动一个卷积核(也称为过滤器或滤波器)在输入的图像或特征图上进行操作,从而得到新的特征图或图像。卷积可以有效地提取图像的局部特征,因此在图像处理和计算机视觉领域中被广泛应用。在深度学习中,卷积通常与其他操作(如激活函数、批归一化等)结合使用,构成神经网络的各个层。
conv2d
conv2d 是深度学习中常用的卷积操作之一。它是指对二维图像进行卷积运算,其中 2d 表示二维的意思。
在卷积神经网络中,conv2d 层用于对输入数据进行卷积运算,并且通过不同的卷积核进行特征提取。卷积操作可以学习到一些空间上的局部特征,通过不断地堆叠多个卷积层可以获得更加抽象和高级的特征表示,进而用于分类、目标检测等任务。
MLP
MLP是多层感知器(Multilayer Perceptron)的缩写,是一种常见的前馈神经网络模型,由多个神经元按照一定的层次结构连接而成。每个神经元都与上一层的所有神经元相连,每层之间的神经元数量可以不同,一般采用全连接方式。MLP通常被用于分类和回归任务。在分类任务中,MLP将输入映射到不同的类别上,而在回归任务中,MLP将输入映射到一个数值上。
MSA
MSA是Multi-Head Self-Attention的缩写,即多头自注意力机制。它是自然语言处理和计算机视觉中的一种关键技术,能够通过对输入序列中的不同位置进行交互,捕捉序列中的关键信息。MSA最早在Transformer模型中被引入,通过将输入序列分别映射到多个头(head)中,每个头独立地计算注意力权重,从而提高模型的表现力和泛化能力。MSA在文本分类、机器翻译、图像分类、物体检测等任务中得到了广泛应用。
CBL
CBL是Convolutions with Batch Normalization and Leaky ReLU的缩写,是一种常用于卷积神经网络中的基础模块。
CBL模块通常由卷积层、批归一化(Batch Normalization,简称BN)和LeakyReLU激活函数三部分组成。其中,卷积层负责特征提取,BN层用于加速训练过程,减少梯度消失和梯度爆炸等问题,而LeakyReLU激活函数则能够解决ReLU激活函数可能出现的神经元死亡问题。
CBL模块的优点在于它能够有效地减少过拟合,同时也可以提高模型的泛化能力,加速模型的训练过程。它的另一个好处是它相对于一些传统的卷积模块,可以更快地收敛到最优解,训练速度更快。
CBL模块在许多深度学习框架中都得到了广泛应用,如PyTorch、TensorFlow等。
C3模块
C3模块是YOLOv5中新增的模块之一,主要的作用是提高模型的感受野(receptive field),增加模型的深度,从而提升检测精度。C3模块是由三个卷积层组成的块,其中前两个卷积层使用1x1的卷积核进行通道数的降维和升维,第三个卷积层使用3x3的卷积核进行特征提取,这种设计能够有效地减少模型参数量,并且在一定程度上缓解了过拟合问题。C3模块可以被嵌套多次,形成不同的层级结构,以逐步提高感受野和深度,从而提高检测性能。
CA模块
CA模块(Channel Attention Module)是一种在通道维度上对特征图进行自适应加权的方法。它通过使用全局平均池化来计算每个通道的权重,然后将这些权重应用于该通道中的所有像素。具体来说,给定一个特征图 F ∈ R C × H × W F\in \mathbb{R}^{C\times H \times W} F∈RC×H×W,CA模块的计算过程如下:
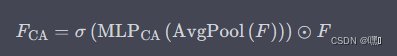
其中, M L P \mathrm{MLP}{\mathrm{}} MLP 是一个包含两个全连接层的多层感知机(MLP), σ \sigma σ 表示 sigmoid 函数, ⊙ \odot ⊙ 表示逐元素乘积。 F F{\mathrm{}} F 表示经过 CA 模块处理后的特征图。
SE模块
SE模块(Squeeze-and-Excitation Module)是一种在空间和通道维度上对特征图进行自适应加权的方法。它通过使用全局平均池化来计算每个通道的权重,然后将这些权重应用于该通道中的所有像素。具体来说,给定一个特征图 F ∈ R C × H × W F\in \mathbb{R}^{C\times H \times W} F∈RC×H×W,SE模块的计算过程如下:

其中, M L P \mathrm{MLP}{\mathrm{}} MLP 是一个包含两个全连接层的多层感知机(MLP), σ \sigma σ 表示 sigmoid 函数, ⊙ \odot ⊙ 表示逐元素乘积。 F F{\mathrm{}} F 表示经过 SE 模块处理后的特征图。
总体来说,CA模块和SE模块都是通过对通道维度上的特征进行加权来增强模型的注意力机制,提高模型的性能。其中,CA模块只考虑通道维度上的特征,而SE模块则同时考虑通道和空间维度上的特征。
两种注意力机制都有各自的优点和适用性。一般来说,如果任务重点在于对不同通道的特征进行加权,那么CA模块可能更适合;如果需要关注空间维度的特征,则SE模块可能更适合。当然,在实际应用中也可以根据具体情况进行选择或者结合使用,以达到更好的效果。
BiFPN
BiFPN(Bilateral Feature Pyramid Network)是一种用于目标检测的特征金字塔网络。其主要思想是通过多级特征融合和双边连接,实现高质量的特征提取和目标检测。其网络结构及与FPA、PAN结构如下:
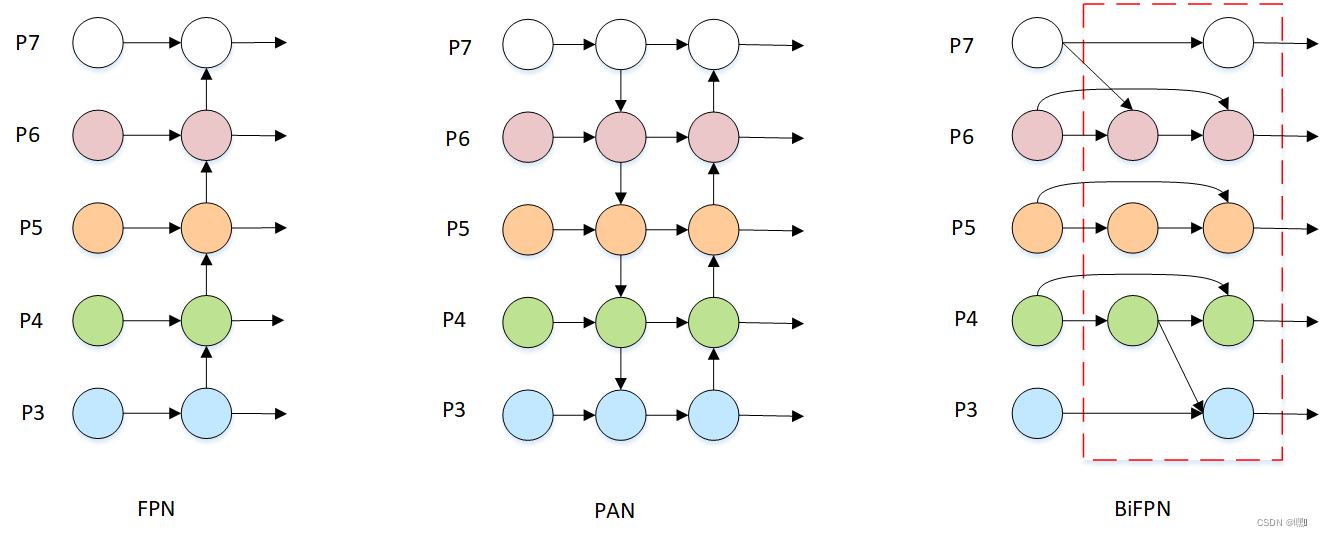
BiFPN的公式如下:
y l , i = { x l , i , l = l m i n 1 2 ( y l + 1 , i + x l , i ) × w 1 + ∑ j = i i + 3 1 4 ( y l + 1 , j + x l , j ) × w 2 , l m i n + 1 ≤ l ≤ l m a x 1 2 ( y l − 1 , i + x l , i ) × w 1 + ∑ j = i − 3 i 1 4 ( y l − 1 , j + x l , j ) × w 2 , l m i n ≤ l < l m i n + 1 y_{l,i}=\begin{cases}x_{l,i},& l=l_{min}\ \frac{1}{2}(y_{l+1,i}+x_{l,i})\times w_{1}+\sum_{j=i}^{i+3}\frac{1}{4}(y_{l+1,j}+x_{l,j})\times w_{2},&l_{min}+1\leq l\leq l_{max}\ \frac{1}{2}(y_{l-1,i}+x_{l,i})\times w_{1}+\sum_{j=i-3}^{i}\frac{1}{4}(y_{l-1,j}+x_{l,j})\times w_{2},&l_{min}\leq l<l_{min}+1\ \end{cases} yl,i={ xl,i,l=lmin 21(yl+1,i+xl,i)×w1+∑j=ii+341(yl+1,j+xl,j)×w2,lmin+1≤l≤lmax 21(yl−1,i+xl,i)×w1+∑j=i−3i41(yl−1,j+xl,j)×w2,lmin≤l<lmin+1
其中, y l , i y_{l,i} yl,i是BiFPN中第 l l l级特征图的第 i i i个位置的输出, x l , i x_{l,i} xl,i是输入特征图, l m i n l_{min} lmin和 l m a x l_{max} lmax是特征金字塔中最小和最大的级别, w 1 w_1 w1和 w 2 w_2 w2是可学习的参数。BiFPN可以在多级特征图之间进行自适应的双边连接,使得多级特征图能够同时获取全局和局部信息,从而提高目标检测的精度和效率。
f up ( P i ) f_{\text{up}}(P_i) fup(Pi):对特征图 P i P_i Pi 进行上采样和 2D 卷积,得到一个新的特征图 U i U_i Ui
假设输入的特征图为 x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn,其中 n n n 表示输入的特征图的数量。BiFPN 模块的计算公式可以表示为:
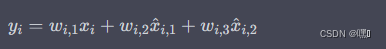
其中 y i y_i yi 表示输出的特征图, x ^ i , 1 \hat{x}_{i,1} x^i,1 表示上采样后的特征图, x ^ i , 2 \hat{x}_{i,2} x^i,2 表示下采样后的特征图, w i , 1 w_{i,1} wi,1、 w i , 2 w_{i,2} wi,2、 w i , 3 w_{i,3} wi,3 是相应的权重,它们可以通过学习得到。
具体地,上采样后的特征图 x ^ i , 1 \hat{x}_{i,1} x^i,1 和下采样后的特征图 x ^ i , 2 \hat{x}_{i,2} x^i,2 可以通过以下公式计算:

其中 Upsample ( ⋅ ) \text{Upsample}(\cdot) Upsample(⋅) 表示上采样, Downsample ( ⋅ ) \text{Downsample}(\cdot) Downsample(⋅) 表示下采样。
在计算权重时,可以通过以下公式计算:
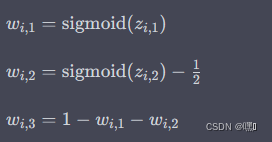
其中 z i , 1 z_{i, 1} zi,1、 z i , 2 z_{i, 2} zi,2 是可学习的偏置参数,它们通过反向传播进行训练。