本系列是对入门书籍《Python编程:从入门到实践》的笔记整理,属于初级内容。标题顺序采用书中标题。
本篇是Python数据处理的第二篇,本篇将使用网上下载的数据,对这些数据进行可视化。
1. 前言
本篇将访问并可视化以两种常见格式存储的数据:CSV和JSON:
- 使用Python的
csv模块来处理以CSV(逗号分隔的值)格式存储的天气数据,找出两个不同地区在一段时间内的最高温度和最低温度; - 使用
json模块来访问以JSON格式存储的交易收盘价数据。
本文数据均可从图书官网下载( http://www.ituring.com.cn/book/1861 )。
2. CSV文件格式
新建一个项目,将文件death_valley_2014.csv复制到项目根目录,并新建highs_lows.py文件,改程序读取加州死亡谷2014年的温度数据,提取出每天的最高和最低气温,并绘制出折线图:
import csv
from datetime import datetime
from matplotlib import pyplot as plt
filename = "death_valley_2014.csv"
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], []
for row in reader:
try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
high = int(row[1])
low = int(row[3])
except ValueError:
print(current_date, "missing data")
else:
dates.append(current_date)
highs.append(high)
lows.append(low)
fig = plt.figure(dpi=141, figsize=(10, 6))
# 绘制最高气温折线图
plt.plot(dates, highs, c="red")
# 绘制最低气温折线图
plt.plot(dates, lows, c="blue")
# 填充两个折现之间的空间,alpha为透明度,0为全透明,1为不透明
plt.fill_between(dates, highs, lows, facecolor="blue", alpha=0.1)
plt.title("Daily high and low temperatures - 2014\nDeath Valley, CA", fontsize=20)
plt.xlabel("", fontsize=16)
# 自动排版x轴的日期数据,避免重叠
fig.autofmt_xdate()
plt.ylabel("Temperature(F)", fontsize=16)
plt.tick_params(axis="both", which="major", labelsize=16)
plt.show()代码现将文件打开,然后通过csv.reader()函数创建一个CSV文件阅读器,参数就是刚才打开的文件;通过next()函数读取文件的一行,并自动将数据转换为列表;然后通过一个for循环读取全部数据。for循环中还添加了错误检查,以防文件中数据丢失等问题造成程序终止。我们还通过fill_between()函数将两个折现之间的区域着色。最后得到的图像如下:
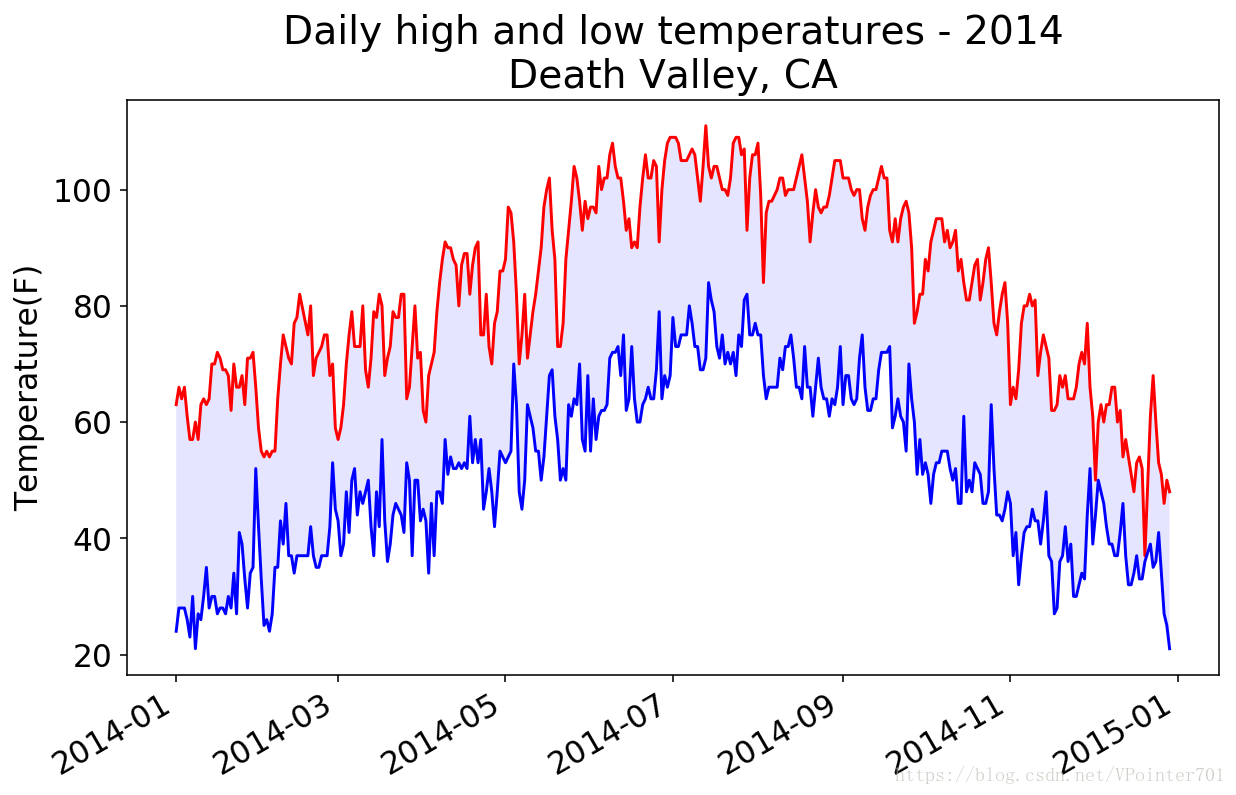
同时我们还得到了一条信息输出:
2014-02-16 00:00:00 missing data即该日的数据丢失了。
3. 制作交易收盘价走势图:JSON格式
现将将btc_close_2017.json拷贝到项目根目录下。本节中将绘制5幅图像:收盘折线图,收盘价对数变换,收盘价月日均值,收盘价周日均值,收盘价星期均值。均使用Pygal绘制。
3.1 绘制收盘价折线图
import json
import pygal
# 将数据加载到一个列表中,列表中的元素是字典
filename = "btc_close_2017.json"
with open(filename) as f:
btc_data = json.load(f)
dates, months, weeks, weekdays, close = [], [], [], [], []
for btc_dict in btc_data:
dates.append(btc_dict["date"])
months.append(int(btc_dict["month"]))
weeks.append(int(btc_dict["week"]))
weekdays.append(btc_dict["weekday"])
close.append(int(float(btc_dict["close"])))
# x轴坐标上的刻度顺时针旋转20度
line_chart = pygal.Line(x_label_rotation=20, show_minor_x_labels=False)
line_chart.title = "收盘价(¥)"
line_chart.x_labels = dates
N = 20 # x轴坐标每隔20天显示一次
line_chart.x_labels_major = dates[::N]
line_chart.add("收盘价", close)
line_chart.render_to_file("收盘价折线图(¥).svg")最后得到的图像如下:
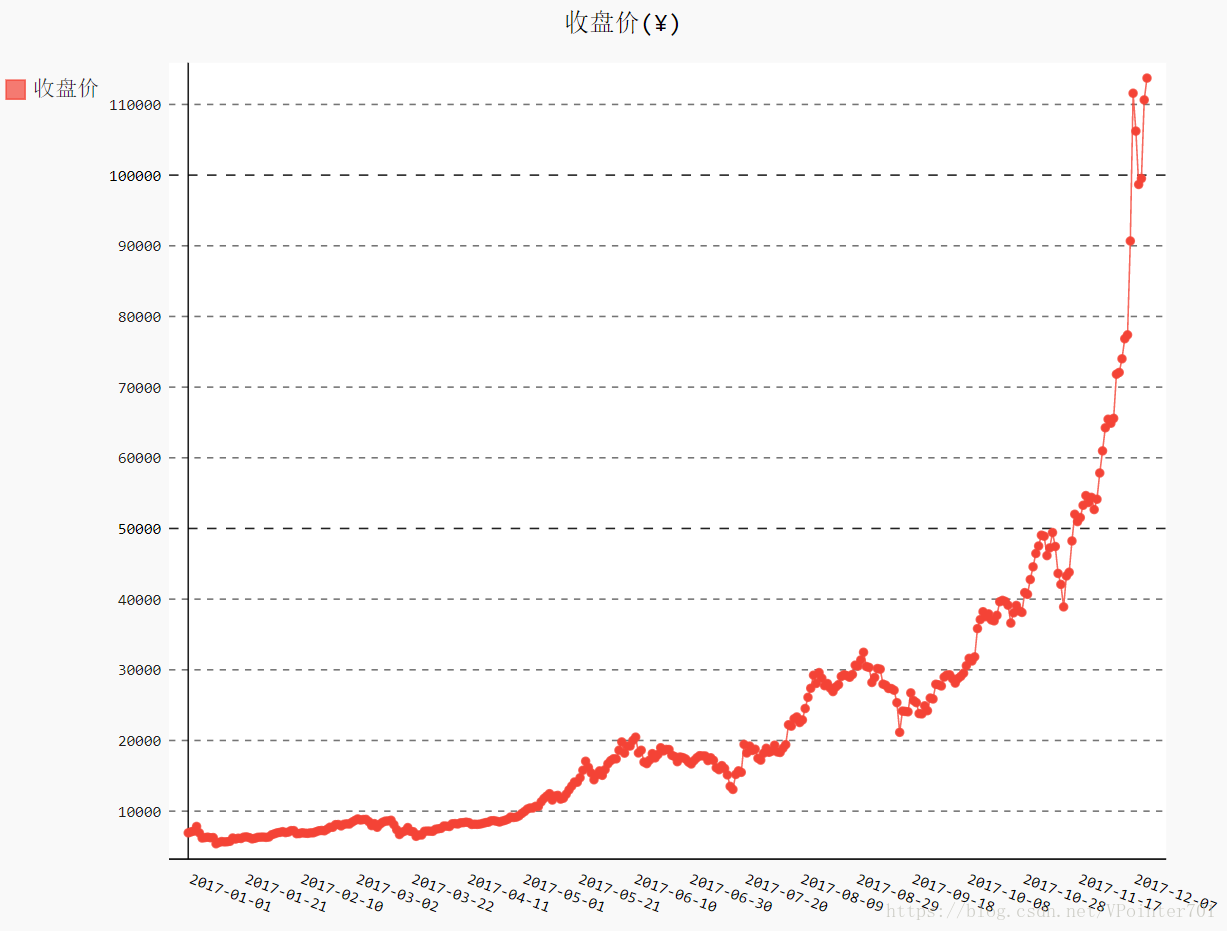
3.2 收盘价对数变换
从上图可以看出,收盘价基本呈指数增长,但其中有一些相似的波动(3,6,9月)。尽管这些波动被增长的趋势掩盖了,但也许其中有周期性。为了验证周期性的假设,需要首先将非线性的趋势消除。对数变换是常用的处理方法之一。我们使用Python标准库中的math模块来解决此问题。
-- snip --
import math
line_chart = pygal.Line(x_label_rotation=20, show_minor_x_labels=False)
line_chart.title = "收盘价对数变换(¥)"
line_chart.x_labels = dates
N = 20 # x轴坐标每隔20天显示一次
line_chart.x_labels_major = dates[::N]
# 对数变换
close_log = [math.log10(_) for _ in close]
line_chart.add("log收盘价", close_log)
line_chart.render_to_file("收盘价对数变换折线图(¥).svg")得到了如下图像:
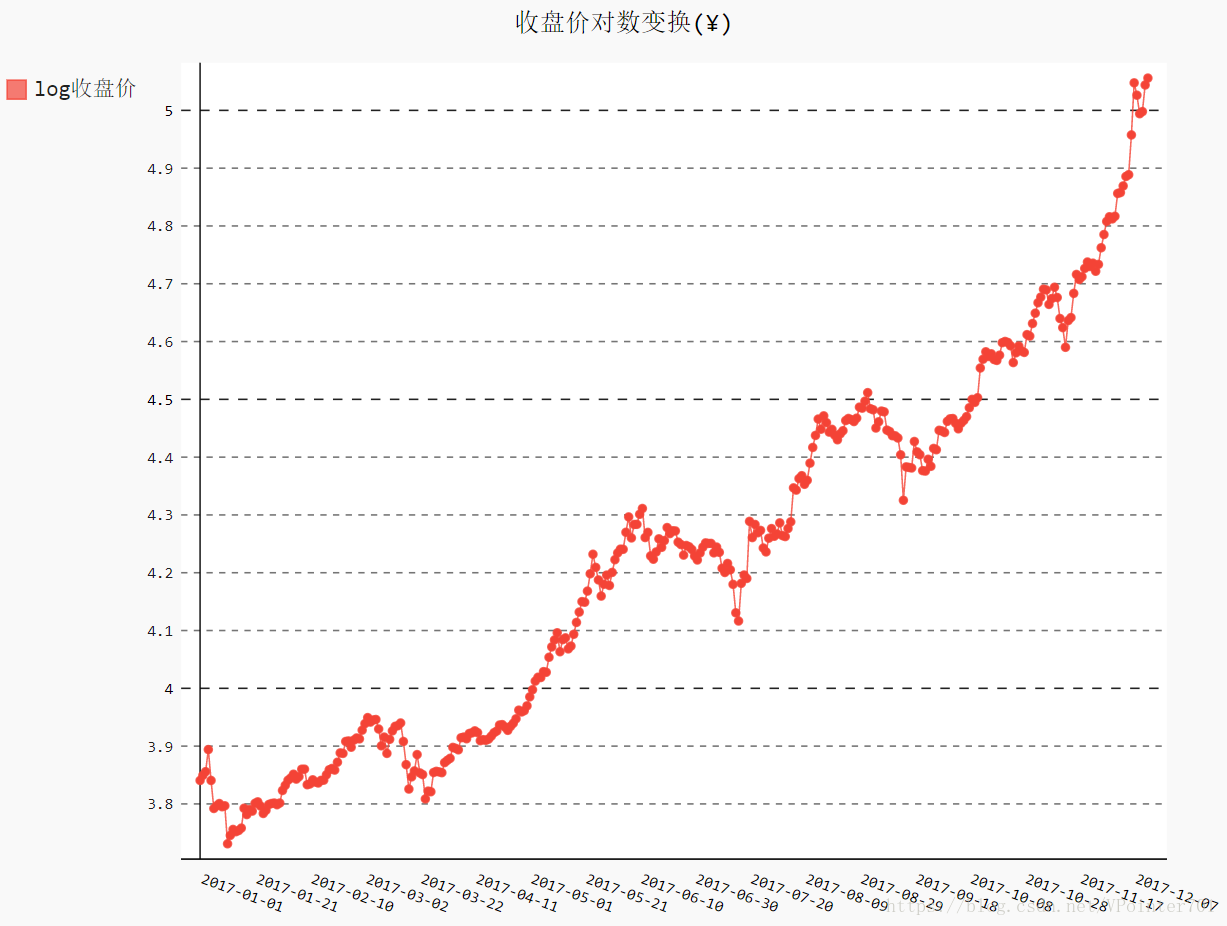
可以看出,3,6,9月都出现了剧烈的波动。下面再看看收盘价的月日均值和周日均值。
3.3 收盘价均值
3.3.1 月日均值
在继续新的代码之前,需要补充一些知识:对于zip()函数,它将多个列表按照元素的位置组成新的列表,而新列表的元素是元组。如下:
# 代码
a = [1, 2, 3]
b = [4, 5, 6]
c = [7, 8, 9, 10]
zipped_1 = zip(a,b)
zipped_2 = zip(a, b, c)
print(zipped_1)
print(list(zipped_1))
print(list(zipped_2))
# 结果
<zip object at 0x0000021D732DCDC8>
[(1, 4), (2, 5), (3, 6)]
[(1, 4, 7), (2, 5, 8), (3, 6, 9)]在python2中,zip()直接返回一个列表,但在python3中,zip()返回一个可迭代的zip对象,这里我们将其转化为列表。也在前面加星号对zip对象进行“解压”(解包):
# 代码:
print(*zipped_1)
# 结果:
(1, 4) (2, 5) (3, 6)星号不止能对zip对象进行解包,还可以对list等类型进行解包。
我们还会用到groupby()函数,但在使用该函数之前,需要对列表进行排序。我们使用sorted()函数进行排序,python3中sorted()函数默认按照元素顺序进行比较,比如这里的列表的元素是元组,则sorted()先比较元组中第一个元素的值,再比较第二个元素的值,如下:
# 代码:
test = [(1, 5), (1, 4), (1, 3), (1, 2), (2, 3)]
print(sorted(test))
# 结果:
[(1, 2), (1, 3), (1, 4), (1, 5), (2, 3)]接下来通过groupby()函数对这些数据进行分组,通过关键字参数key=itemgetter(0)指定根据列表元素(即元组)的第一个值进行分组。也可以将这里的itemgetter()函数替换为lambda表达式,如等价的lambda表达式为lambda x: x[0]。在python3中,groupby()返回一个可迭代的groupby对象,如果将其转换成list,list中的每个元素的第二个值也是个可迭代对象:
# 代码:
test = [(1, 5), (1, 4), (1, 3), (1, 2), (2, 4), (2, 3), (3, 5)]
temp = groupby(sorted(test), key=itemgetter(0))
print(temp)
print(list(temp))
for a, b in temp:
print(list(b))
# 结果:
<itertools.groupby object at 0x0000013CD9A4D458>
[(1, <itertools._grouper object at 0x0000013CE8AAE160>),
(2, <itertools._grouper object at 0x0000013CE8AAE128>),
(3, <itertools._grouper object at 0x0000013CE8AAE198>)]
[(1, 2), (1, 3), (1, 4), (1, 5)]
[(2, 3), (2, 4)]
[(3, 5)]从上面的for循环的结果来看,可以将groupby()返回的对象看做一个字典,该字典的键为上面的key的值,该字典的值为还没分组时列表中的部分元素(可能组成了列表,也可能组成了元组)。
现在言归正传,回到主线。
绘制2017年前11个月的日均值,前49周的日均值,以及每周中各天(Monday~Sunday)的日均值。首先我们需要封装一些代码:
from itertools import groupby
from operator import itemgetter
def draw_line(x_data, y_data, title, y_legend):
xy_map = []
# 本段见后面解释
for x, y in groupby(sorted(zip(x_data, y_data)), key=itemgetter(0)):
y_list = [v for _, v in y]
xy_map.append([x, sum(y_list) / len(y_list)])
x_unique, y_mean = [*zip(*xy_map)]
line_chart = pygal.Line()
line_chart.title = title
line_chart.x_labels = x_unique
line_chart.add(y_legend, y_mean)
line_chart.render_to_file(title + ".svg")
return line_chart本段代码有些绕。从前面的介绍可以知道,for循环中的变量y相当于一个list,这个list的元素是tuple,tuple的第一个元素是x_data中的值,不再重复需要,所以取第二个值组成list,即第8行代码。xy_map是个list对象,而它的元素也是list,即它是一个二维数组。注意第10行的操作,*xy_map将list进行解包,zip()函数将解包后的元素再次打包成一个zip对象,如果将其看做list对象,则这个对象含有两个tuple元素,然后将这个zip对象也解包,最外面再套一层list,得到一个含两个tuple元素的list,最后再平行赋值。为了更具体的体现这段操作,下面用一些简单数据进行模拟:
# 代码:
temp = [[1, 2], [3, 4], [5, 6]]
x, y = [*zip(*temp)]
print(x)
print(y)
# 结果:
(1, 3, 5)
(2, 4, 6)最后,终于到了画图阶段:
-- 读取文件内容的代码和前面一样 --
idx_month = dates.index("2017-12-01")
line_chart_month = draw_line(months[:idx_month], close[:idx_month],
"收盘价月日均值(¥)", "月日均值")得到的结果如下:
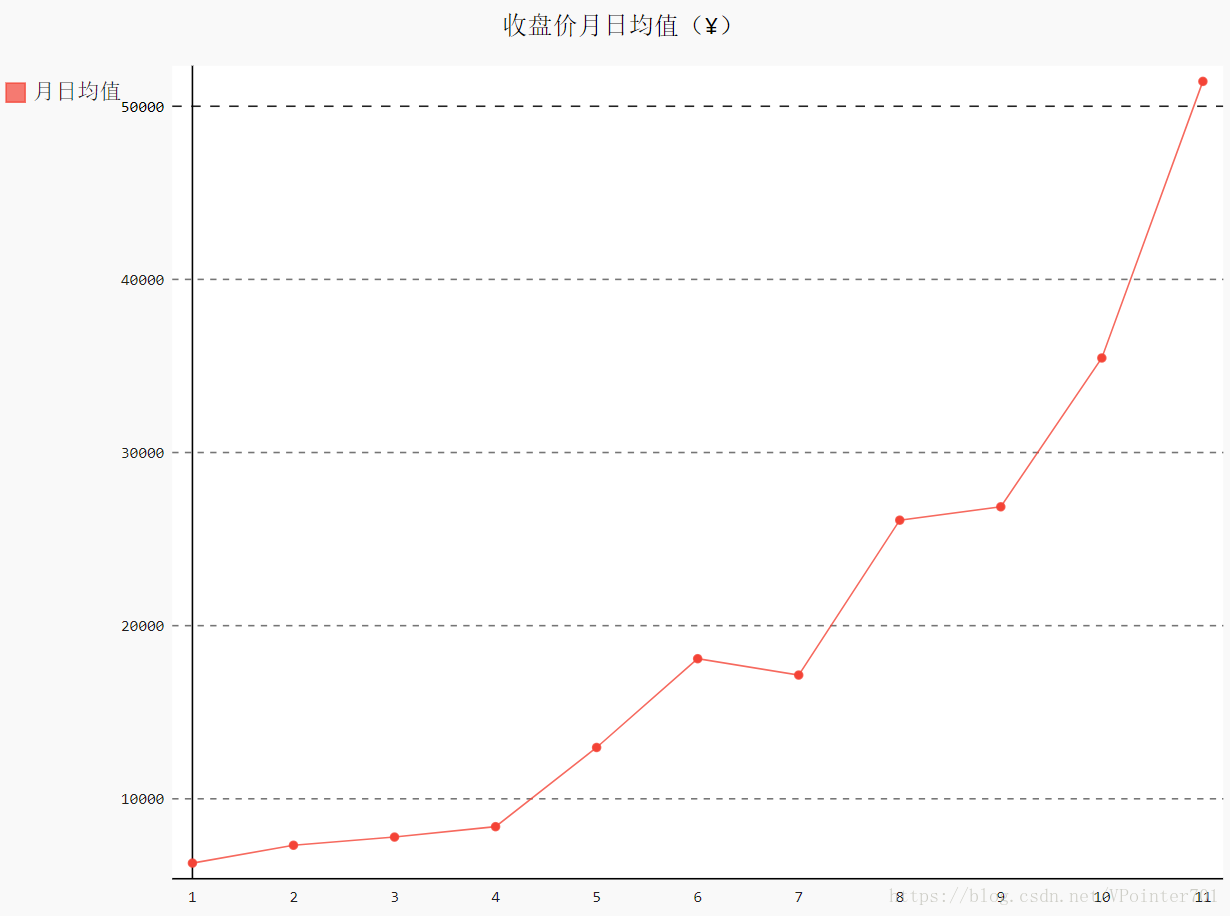
3.3.2 周日均值
2017年的第一周从2017年1月2日开始,第49周周日是2017年12月10日。
-- 读取文件内容的代码和前面一样 --
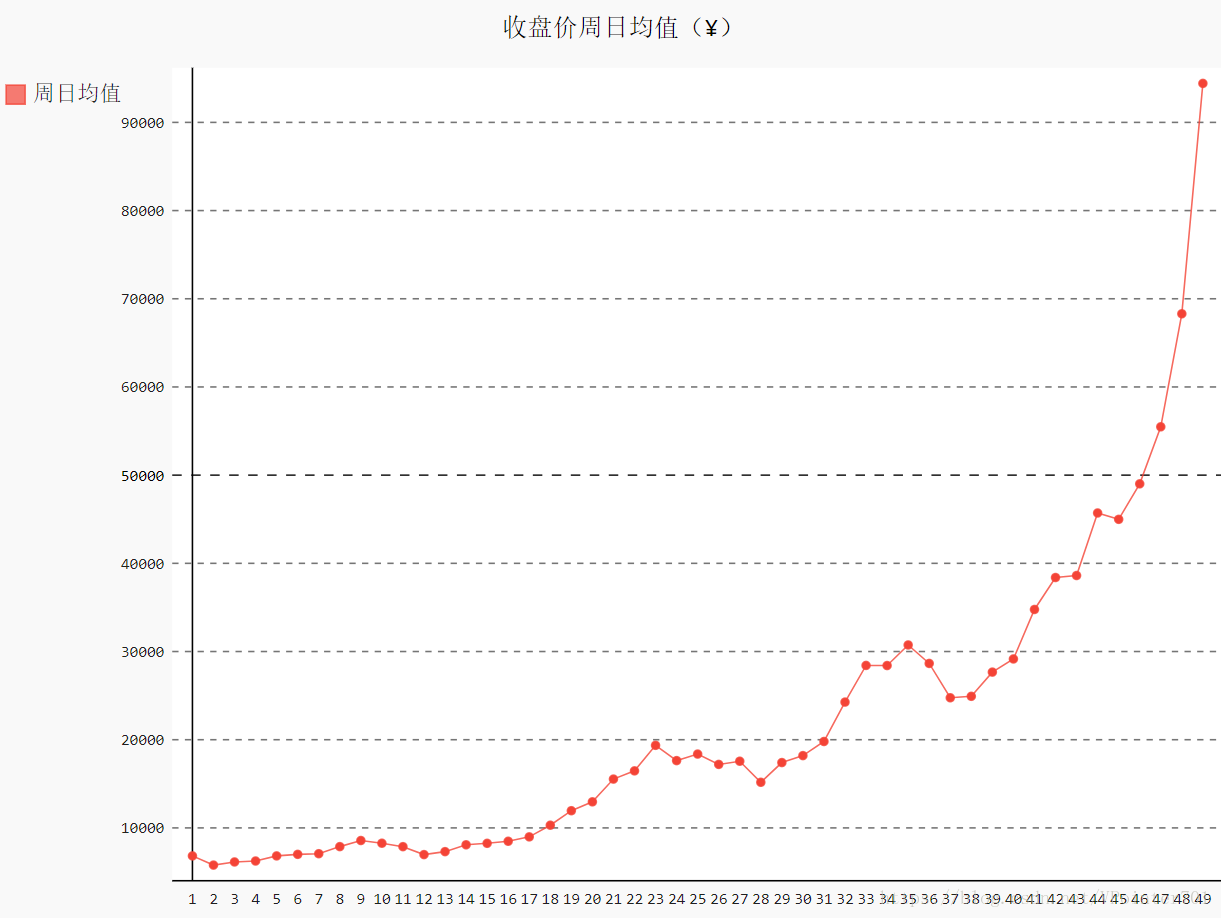
idx_week = dates.index("2017-12-11")
line_chart_week = draw_line(weeks[1:idx_week], close[1:idx_week], "收盘价周日均值(¥)", "周日均值")结果如下:
3.3.3 每周中各天的均值
如果直接用weekdays这个列表生成图表,由于该列表存储的是字符串,排序的时候是按ASCII码进行排序,最后生成的图表星期的顺序会出错,所以将其转换成数字。
idx_week = dates.index("2017-12-11")
wd = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday",
"Sunday"]
weekdays_int = [wd.index(w) + 1 for w in weekdays[1:idx_week]]
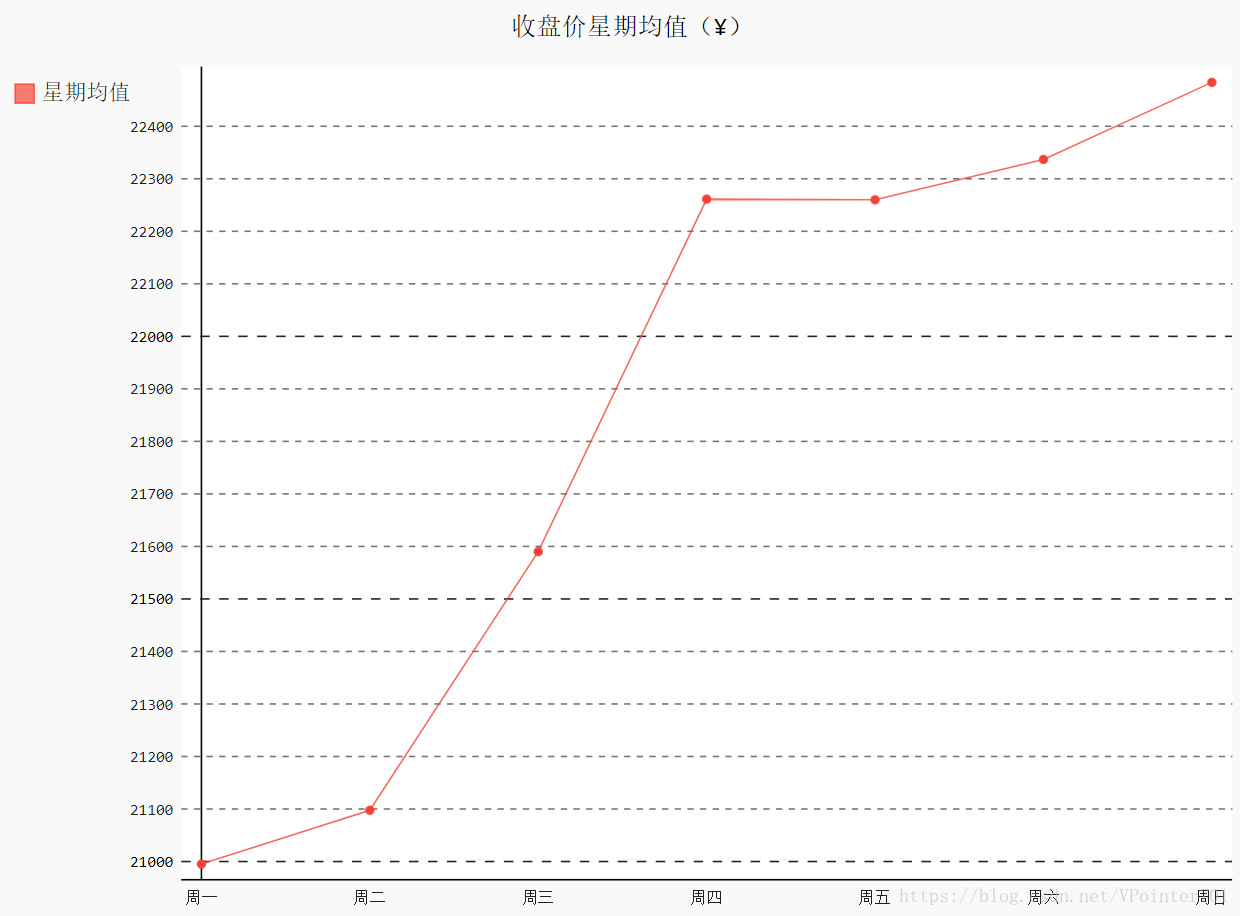
line_chart_weekday = draw_line(weekdays_int, close[1:idx_week], "收盘价星期均值(¥)", "星期均值")
line_chart_weekday.x_labels = ["周一", "周二", "周三", "周四", "周五", "周六", "周日"]
line_chart_weekday.render_to_file("收盘价星期均值(¥).svg")最后的结果如下:
3.4 收盘价数据仪表盘
最后我们将五张表整合到一个文件中,做成一个仪表盘:
with open('收盘价Dashboard.html', 'w', encoding='utf8') as html_file:
title = '<html><head><title>收盘价Dashboard</title><meta charset="utf-8"></head><body>\n'
html_file.write(title)
for svg in [
'收盘价折线图(¥).svg', '收盘价对数变换折线图(¥).svg', '收盘价月日均值(¥).svg',
'收盘价周日均值(¥).svg', '收盘价星期均值(¥).svg'
]:
html_file.write(
' <object type="image/svg+xml" data="{0}" height=500></object>\n'.format(svg))
html_file.write('</body></html>')效果如下:
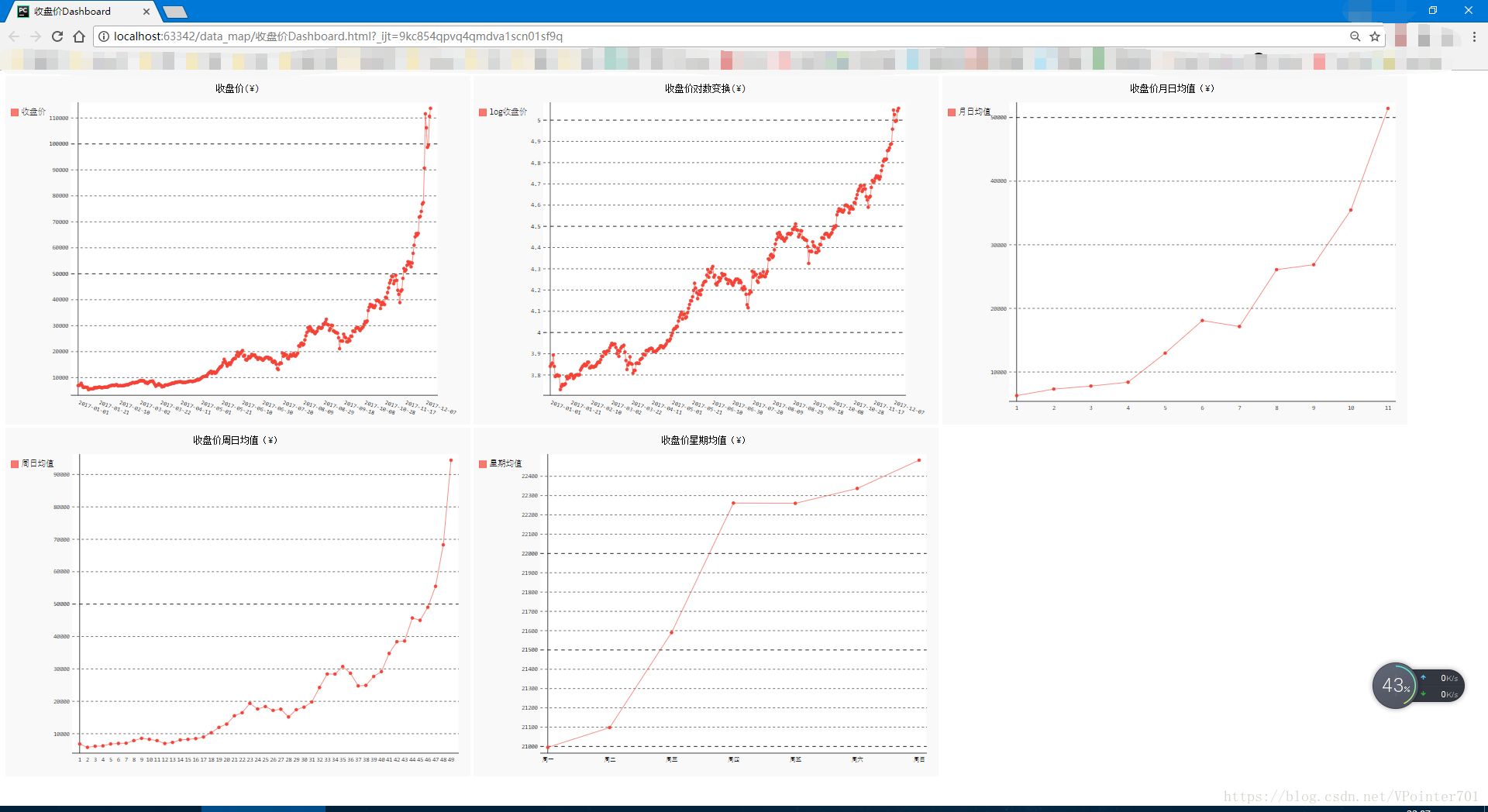
这是将浏览器放大后的效果,默认100%的话这五张图都在同一行,且非常小。
4. 小结
本篇中主要内容有:
- 如何使用网上的数据集;
- 如何处理CSV和JSON文件,以及如何提取你感兴趣的数据;
- 如何使用
matplotlib来处理以往的天气数据,包括如何使用datetime模块,以及如何在同一个图表中绘制多个数据系列; - 如何
json模块来访问JSON格式存储的交易收盘价数据,并使用Pygal绘制图形以探索价格变化的周期性,以及如何将Pygal图形组合成数据仪表盘。
下一篇将从网上采集数据并对其进行可视化。