
每日好店作为一个独特的店铺导购场景,希望能够“帮助用户发现更多好店”。目前每日好店的主要入口包括首页宫格和信息流,用户在店铺精选流中发生点击行为后,会进入主题二级承接页,店首页以及全部宝贝等页面。
本系列共两篇内容,上篇:每日好店——淘宝店铺推荐系统实践

问题概述
目前,店铺展示形式主要还是以商品卡片为主,包含店招区域(店铺标题、店铺背书、背景图、回头客评论等)和商品区域(可滑动查看多个商品),如下图所示。

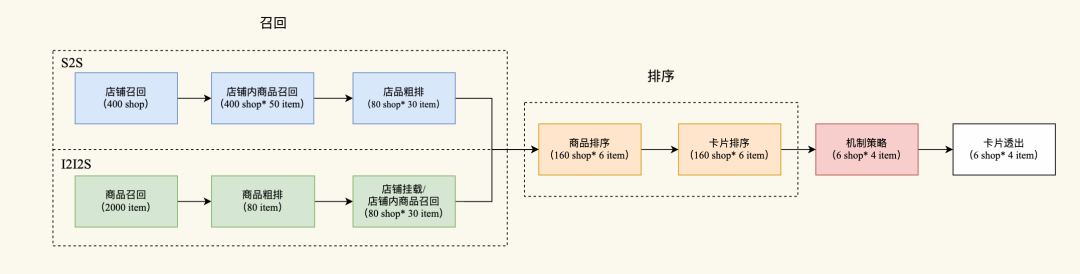
卡片排序是本场景比较独特的一环:相比于商品和店铺,卡片是一个两级结构,排序时需要同时考虑商品和店铺。我们将卡片排序建模为级联模型:商品排序和卡片排序,商品排序用于选择卡片内的商品从而组装卡片,卡片排序用于对组装好的卡片进行排序。

卡片精排
卡片精排部分主要包括店品两级建模和多目标优化:
店品两级建模:基于店品召回引擎返回的候选卡片(一店+N品),店品排序模型采用级联的方式端到端地对商品和卡片进行两级打分,并最终实现卡片组装(一店+三品)和卡片排序。
多目标优化:同时建模一跳和二跳指标,实现点击和引导类指标双增长;
▐ 店品两级建模
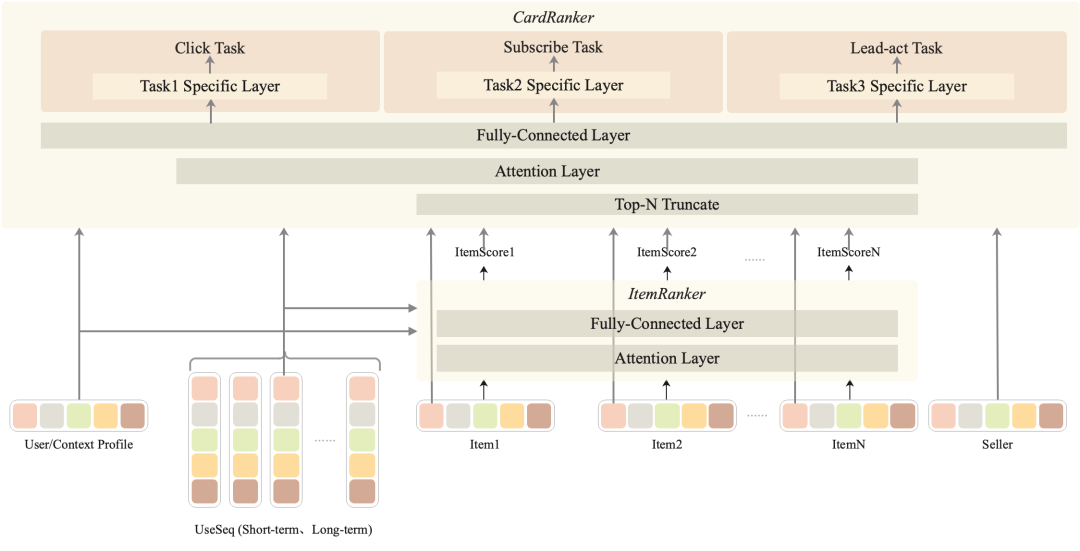
卡片是一个两级结构:包含店铺和商品。一开始我们尝试对卡片整体进行建模,模型输入包括 商品、店铺、用户侧特征。模型结构如图所示,但是鉴于本场景流量较少,初期训练数据不够,从头训练一个复杂的卡片排序模型难度较大。因此我们考虑将卡片排序分解为两部分:商品排序和卡片排序。其中,商品排序预估用户对目标商品的点击率,可以借鉴其他成熟场景的商品预估模型,我们这里借鉴了首猜的商品排序模型;而卡片排序在接收到商品排序的分数后,首先根据商品分数截取 top3商品用于组装卡片,然后预估用户对卡片整体的点击率。我们称之为 ItemAwareShopRankingModel(简称为IASM),其模型结构如下图所示:
商品排序
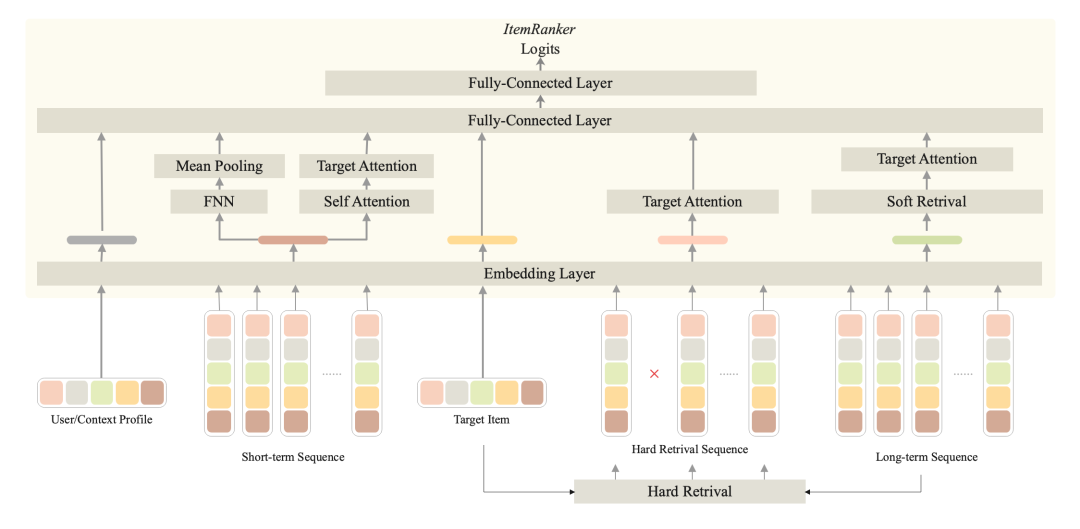
对于商品排序模型,用户的行为序列是非常重要的特征;而用户的行为序列越长,模型对用户的兴趣捕捉的更为精准,因此如何利用用户长期行为成为一个研究热点;例如阿里妈妈团队的 SIM [1]、淘宝首猜团队的 ETA[2] 都取得不错的效果。
我们借鉴了SIM 和 ETA 两种模型,实现对用户长周期兴趣建模,具体模型结构如下:
但是实践中发现,基于首猜模型直接finetune负向效果明显。分析发现首猜样本和好店商品样本差异较为明显,且本场景样本数据量较少而模型参数量较大,因此,因此在实践中只训练揽月模型的LogitsLayer和BiasNet部分,具体实验结果如下。

卡片排序
卡片排序模型主要有两个能力:
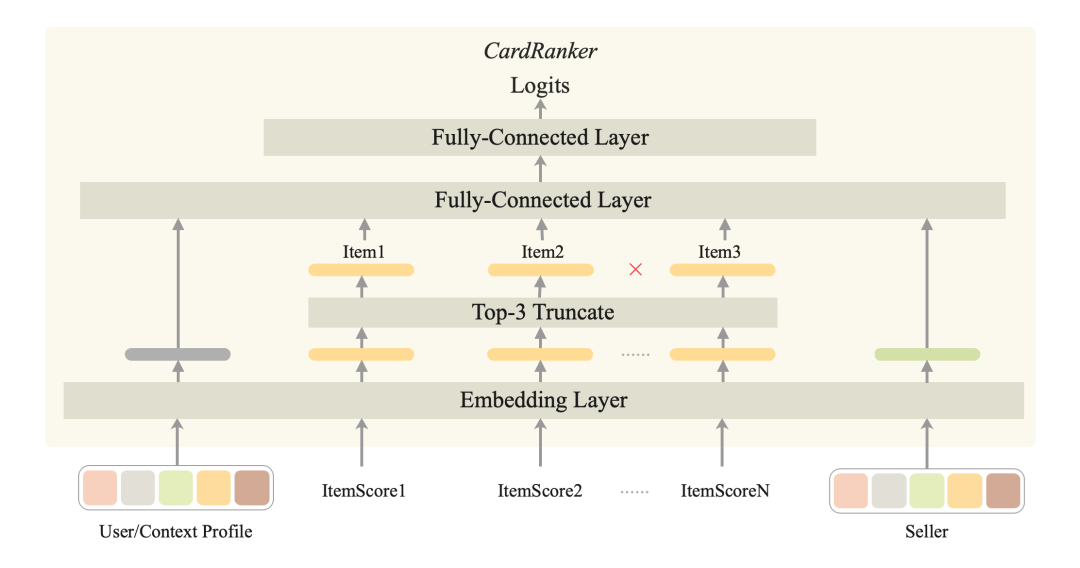
组装卡片:基于商品排序的分数,卡片排序模型选择 top3 用于组装卡片;
卡片排序:引入商品分、用户特征以及店铺特征,经过若干层全连接后,得到卡片的 ctr 分。
base 版的卡片排序的模型结构如下所示:
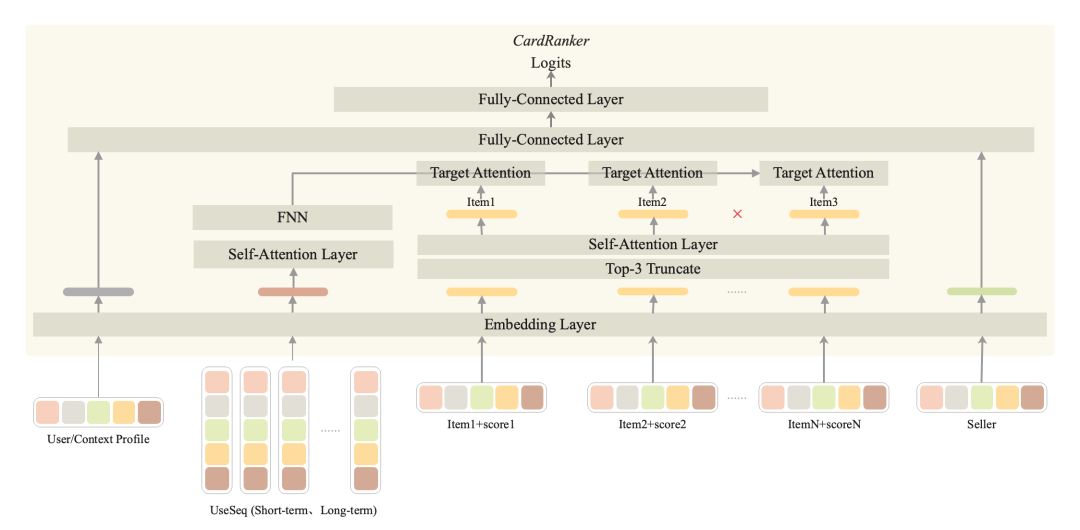
我们还尝试对卡片内店和品进行联合建模,主要改进点如下:
考虑除了店铺特征外,增加更多商品特征;
增加用户近期行为序列,与3个商品做 target attention,建模用户对商品的偏好;
增加 self-attention 建模 3个商品之间的联系;
模型结构如下图所示:
但改进后的版本在离线评测上无明显提升,线上效果亦不明显;我们猜测可能的原因:
商品特征中的 ctr 分已经代表了用户对品的喜好程度(商品特征、用户近期行为序列在商品排序模型中已经存在),增加商品特征和用户行为序列不能带来额外收益;
经过数据分析发现,3个商品的类目是否一致对卡片整体 ctr 无明显影响 ,推测用户对卡片整体的感知并不强烈。另外,经过统计,卡片内3个商品的点击数比例约为 7:2:2,用户还是对第一个商品的感知比较强烈。
▐ 多目标建模
作为店铺导购场景,我们的核心目标是为了帮助用户找到其感兴趣的好店。因此为了增强用户对“好店”的认知,让用户进店后“逛起来”,我们尝试去优化场景的引导类指标(包括引导订阅、引导ipv和引导停留时长等)。另一方面,我们对一跳点击指标和引导指标进行相关性分析,发现点击和引导ipv以及引导停留时长等任务相关系数较高(0.895),两者联合建模可能会有正向收益,具体数据如下:
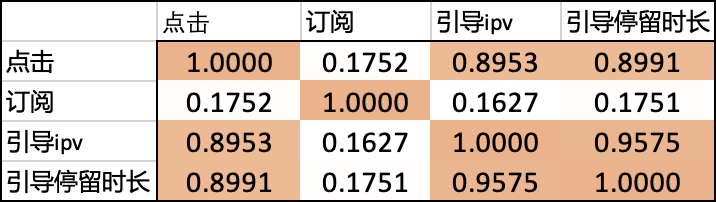
另外,考虑到引导ipv和引导停留时长任务相关度很高(0.957),因此选择只对引导ipv进行建模;最终,我们选择对点击、引导订阅以及引导ipv等任务进行多目标联合建模。
建模思路:将点击、和订阅任务建模为二分类,将引导ipv任务建模为多分类(需预先对引导ipv进行等频分桶);直接建模 从曝光到点击的概率(click)、从曝光到订阅的概率(subscribe)、从曝光到引导ipv(lead_ipv);
训练数据:
点击任务:点击样本作为正样本,曝光未点击样本为负样本;
订阅任务:点击且订阅样本为正样本,曝光未点击以及点击未订阅样本为负样本;
引导ipv任务:预先对引导ipv等频分为五个桶,再加上负类(曝光未点击),将所有曝光样本分为六类;
模型结构:采用 shared-bottom 网络结构,底层参数共享,顶层 每个任务有单独的 tower,期望能够学习到不同任务特有的 feature,模型结构参考参考图1。
多任务模型

除此shared-bottom网络结构之外,我们还尝试了其他的多任务模型,包括 ESMM[3] 和 MMOE[4] 等,但离线训练并未取得明显提升,因此没有上线。
最终 shared-bottom版 模型上线后,二跳引导类指标有大幅提升,一跳点击指标亦有明显提升:人均点击数 +2.65%,引导订阅 +34.29%,引导ipv +32.88%,引导停留时长 +21.56%。
多目标分数融合
我们在融合多个任务分数时,尝试了公式法和模型融合两种方法:
公式法融合:参考 ctr 和 cvr 的融合公式
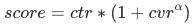 ,我们将其推广到融合点击分、订阅分和 引导ipv分:
,我们将其推广到融合点击分、订阅分和 引导ipv分: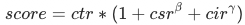 ,其中
,其中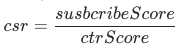 表示店铺从点击到订阅的概率,
表示店铺从点击到订阅的概率,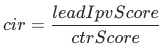 表示 引导ipv分数和 ctr 的比值。经线上AB实验,最终确定一组最优参数
表示 引导ipv分数和 ctr 的比值。经线上AB实验,最终确定一组最优参数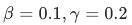 。
。ltr 模型融合:将多个目标加权组合得到最终目标,然后使用 gbdt 回归模型去拟合最终目标:
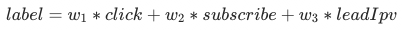 。相比于公式法,ltr模型提升明显:人均曝光卡片数+1.39%,人均点击卡片数+1.36%,引导停留时长+7.13%,全引导IPV+7.95%,全引导订阅-0.24%。
。相比于公式法,ltr模型提升明显:人均曝光卡片数+1.39%,人均点击卡片数+1.36%,引导停留时长+7.13%,全引导IPV+7.95%,全引导订阅-0.24%。

卡片重排
浏览深度在一定程度上能代表用户对于本场景的心智,浏览深度越高,表明用户对于本场景的心智越强;因此我们在后期尝试去优化整体信息流的下翻深度,期望通过卡片重排来提升用户的浏览深度。
▐ 下翻概率建模
为了优化浏览深度,我们尝试对用户下滑概率进行建模。
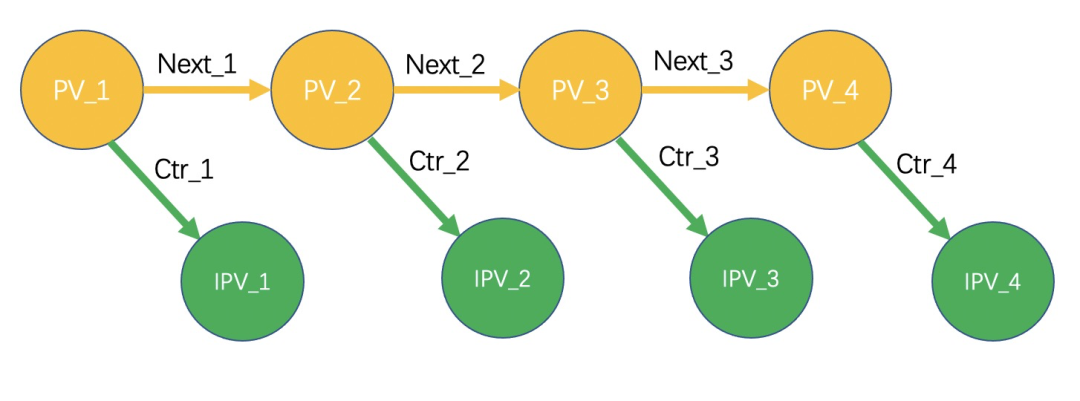
假设一次请求返回 个卡片,
个卡片, 表示卡片
表示卡片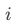 的下滑率,
的下滑率,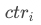 表示卡片
表示卡片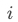 的点击率,则卡片
的点击率,则卡片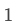 的IPV价值为
的IPV价值为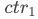 ,卡片
,卡片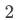 的价值为
的价值为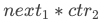 ...
...
则整页ipv价值为:
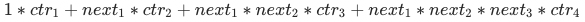
这里用Beam Search方法进行序列搜索,在每个坑位保留累积到当前位置整体累积收益最大的Beam Size个序列,最终挑选出K个序列,
候选序列生成:采用 beam-search算法,在每个位置保留整体累积收益最大的BeamSize个序列;
序列选择:选择整页ipv价值最大的序列,作为最终透出序列;
样本构建:我们一开始使用跳失样本作为负样本,其余曝光样本作为正样本,但是在实践中效果未达预期;经过数据分析发现,跳失样本中约 44.2% 样本是点击跳失,考虑到点击属于正向行为,因此把这部分样本从负样本中剔除,只保留曝光调失。
模型结构:为了减少卡片重排阶段的耗时,因此将 用户是否下翻 作为卡片排序模型的一个子任务;
线上效果:卡片重排能显著增加人均曝光卡片数、曝光类目数,人均点击卡片数亦有一定提升:人均曝光店铺数+1.45%,人均点击店铺数+0.35%,人均曝光叶子类目数+3.70%,人均曝光一级类目数+2.52%;

总结和展望
经过一个S的努力,我们在卡片排序模型上取得了较为明显的效果,但是仍有提升空间:
卡片组装:目前是通过贪心的方法选择分数最高的 3个商品用于组装卡片,但是这样并不一定能得到全局最优解,因此卡片组装是一个值得探索的方向。在这个问题上,我们有两种思路:
-
一店多卡:对于1个店铺组装多个卡片,然后使用卡片排序模型去选择最优的一个;
卡片内商品重排:借鉴重排技术,实现从N个商品中选择3个组装成卡片使卡片整体的点击率最高。
卡片重排:
-
目前卡片重排是 point-wise 建模,未考虑上下文卡片之间的关系,未来可以升级到 list-wise;
目前卡片重排 仅考虑卡片之间顺序,可以同时考虑卡片内商品的顺序,做成两级重排;

引用
[2] 阿里定向广告新一代主模型:基于搜索的超长用户行为建模范式
[3] Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1137-1140.
[4] Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 1930-1939.

团队介绍
我们是大淘宝技术的好货&好店技术团队,主要服务淘宝两大导购业务:有好货和每日好店,为上亿消费者提供导购服务,为千万商家、机构和达人提供内容运营平台和商业化方案,致力于通过技术和业务创新提升淘宝导购效率。团队研究方向主要包含商品推荐、内容推荐、AIGC等,我们在推荐算法领域也有很深的技术沉淀,在国际会议和杂志上发表数十篇学术论文。
大淘宝春季 2024 届实习生招聘已正式启动,欢迎对导购业务感兴趣的同学加入我们,可将简历发送到 [email protected]
¤ 拓展阅读 ¤