背景
随着弹幕数量越来越多,以及我们会不断的往视频上面添加越来越多的动画,如何让各种弹幕流畅的展示给我们的用户,成为了我们必须要考虑的问题。这要求我们需要了解浏览器底层的渲染原理,才能以最低的性能消耗来实现我们的各种弹幕效果,知道哪些性能消耗是我们前端可以避免的。
目标
通过此篇介绍,可以了解到:我们实现的动画,在浏览器上具体是怎么显示到屏幕上,以及可以通过减少哪些地方的消耗,来实现更加流畅的动画。
正文
(一)chrome多进程模型
1.1 主要进程
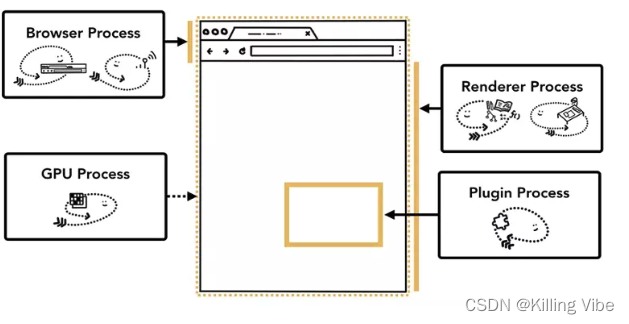
各个进程具体负责的工作内容:
- Browser 负责浏览器的“Chrome”部分, 包括导航栏,书签, 前进和后退按钮。同时这个进程还会控制那些我们看不见的部分,包括网络请求的发送以及文件的读写
- Renderer 默认每个Tab页面都会开启一个渲染进程,主要负责我们的html解析,js的执行
- Plugin 主要是负责插件的运行,因为我们每个人都可以编写插件,chrome 为了不使插件的崩溃影响到整个浏览器,它给每个插件都开启了一个独立的进程
GPU Chrome 刚开始发布的时候是没有 GPU 进程的,而 GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器的普遍需求
除了上面列出来的进程,Chrome还有很多其他进程在工作,例如扩展进程(Extension Process)和工具进程(utility process)。
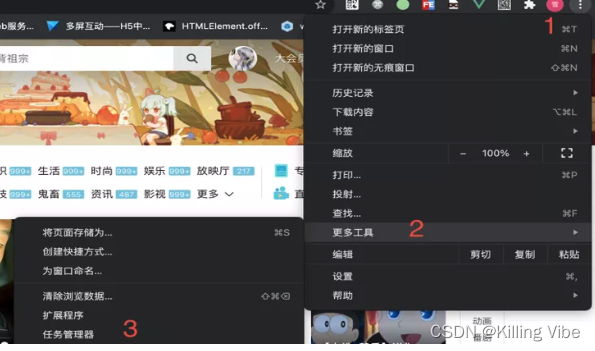
我们可以在浏览器右上角 > 更多工具 > 任务管理器,看到每个进程使用的cpu和内存情况:

1.2 Chrome多进程架构的优劣
好处:
一: 多进程可以使浏览器具有很好的容错性。
假如你有三个tab,你就会有三个独立的渲染进程。当其中一个tab的崩溃时,你可以随时关闭这个tab并且其他tab不受到影响。可是如果所有的tab都跑在同一个进程的话,它们就会有连带关系,一个挂全部挂。
二:可以提供安全性和沙盒性。
因为操作系统可以提供方法让你限制每个进程拥有的能力,所以浏览器可以让某些进程不具备某些特定的功能。例如,由于tab渲染进程可能会处理来自用户的随机输入,所以Chrome限制了它们对系统文件随机读写的能力。
劣处:
由于每个进程都有各自独立的内存空间,会占用大量内存。
改进:
一:为了节省内存,Chrome会限制被启动的进程数目,当进程数达到一定的界限后,Chrome会将访问同一个网站的tab都放在一个进程里面跑。
二: 当Chrome在一些性能比较好的硬件中运行时,浏览器进程相关的服务会被放入不同的进程运行以提高系统的稳定性。相反如果硬件性能不好,这些服务就会被放在同一个进程里面执行来减少内存的占用。
(二)从输入URL到显示页面发生了什么?
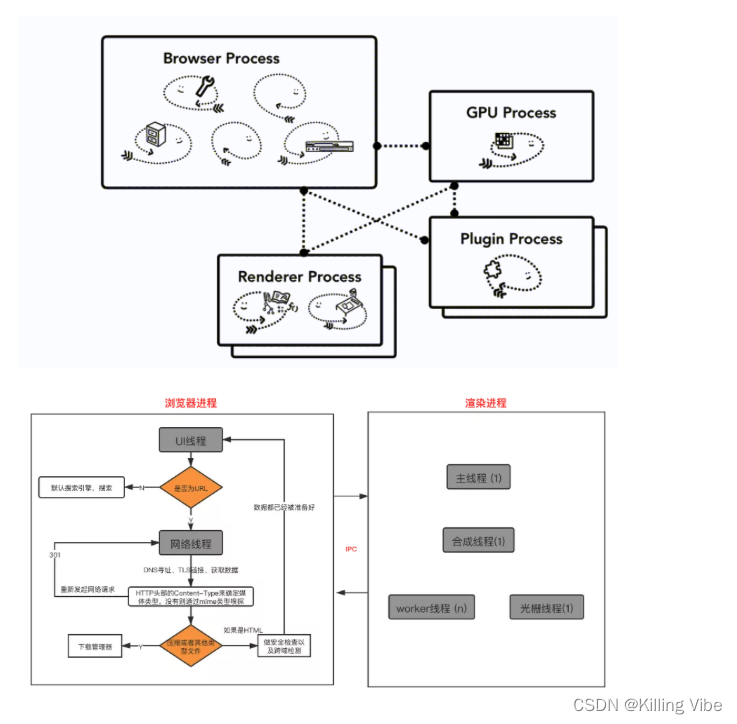
2.1 浏览器进程里执行了哪些任务
第一步:处理输入
浏览器的UI 线程会进行一系列的解析来判定:输入的字符串是搜索的关键词还是一个 url 地址。
如果不是url地址,会调用浏览器的默认搜索引擎,执行搜索操作。
第二步:开始导航
如果是url地址:UI线程会叫网络线程初始化一个网络请求来获取站点的内容,也就是dns寻址、tcp三次握手、arp寻址等类似操作。
这时候tab上会展示一个资源正在加载中的loading图标。
ui线程也会通知浏览器进程去开启一个渲染进程,为渲染页面做准备。
第三步:读取响应
在获取到响应之后:如果网络线程收到服务器的301重定向,它就会告知UI线程进行重定向,然后它会再次发起一个新的网络请求。
如果是数据内容,它会先检测响应数据的具体媒体类型。
响应主体的媒体类型一般可以通过HTTP头部的Content-Type来确定,不过Content-Type有时候会缺失或者是错误的,这种情况下浏览器就要进行MIME类型嗅探来确定响应类型了。
如果拿到的响应数据是一个压缩文件,响应数据就会交给下载管理器来进行下载操作。
第四步:寻找一个渲染进程
如果响应的主体是一个 HTML 文件,网络线程会对内容做一些必要的安全检测,并寻找一个渲染进程。
第五步:提交导航
数据和渲染进程都已经准备好了,浏览器进程会通过IPC告诉渲染进程去提交本次导航。
除此之外浏览器进程还会将刚刚接收到的响应数据流传递给对应的渲染进程让它继续接收到来的HTML数据。
一旦浏览器进程收到渲染线程的回复说导航已经被提交了,导航这个过程就结束了,文档的加载阶段会正式开始。
到了这个时候,导航栏会被更新,也会生成当前 tab 的会话历史。
第六步:渲染进程继续接收数据并解析
当导航提交完成后,渲染进程会继续接收html数据,并解析、加载页面相关的资源,一旦所有资源都onload之后,渲染进程会通知浏览器进程,所有资源已经加载完成,这时候,UI 线程就会停止导航栏上的loading图标。
(三)渲染进程与gpu进程执行的任务
3.1 渲染进程作用
渲染进程的主要任务是将HTML,CSS,以及JS转变为我们可以进行交互的网页内容。
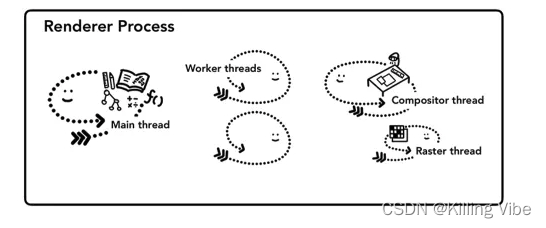
渲染进程里面的主要线程:
- 一个主线程 负责html、css解析以及js的执行
- 一个合成线程 负责分割,生成帧数据,接收用户事件
- 一个光栅线程池 将分割的图块转换为位图
- 几个工作线程 例如web worker和service worker线程
3.2 主线程任务
渲染进程在接收到html数据后,首先会在主线程执行:转换成字符流,经过词法分析,生成token序列(这时候,浏览器会做一个优化,会把识别出来的资源地址,提前交给网络线程去加载数据),然后是语法分析,解析html,生成DOM树,解析css生成css规则树。
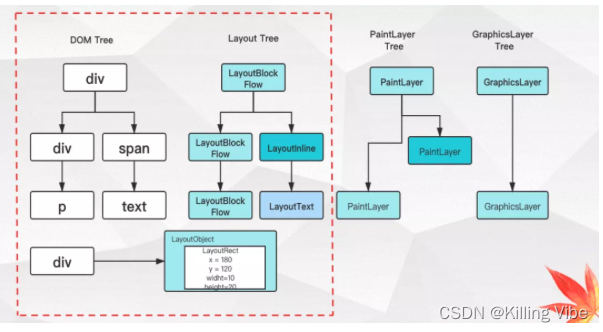
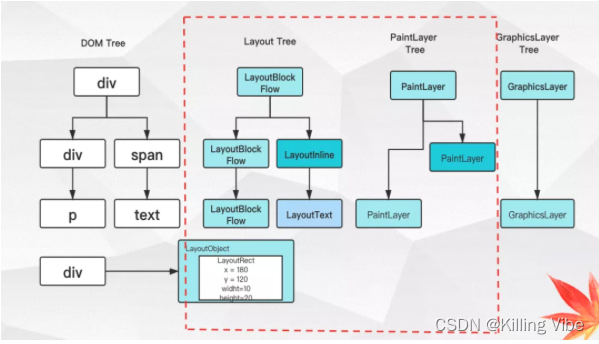
3.2.1 生成DOM树之后,会逐次生成的4种树结构,首先是结合DOM树和css规则树生成的布局树
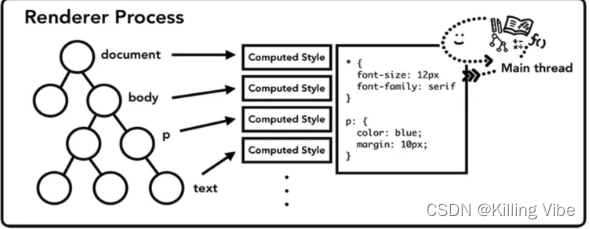
主线程会遍历DOM树,结合css规则树,确定每个DOM节点的计算样式。
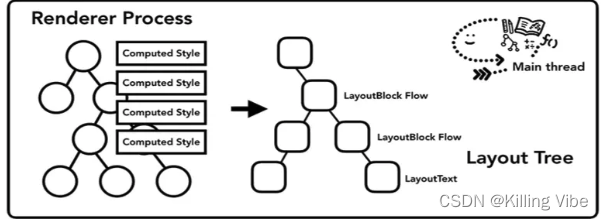
然后还会再遍历一次DOM树,根据DOM节点的计算样式计算出一个布局树。布局树上每个节点会有它在页面上的x,y坐标以及盒子大小的具体信息。布局树长得和先前构建的DOM树差不多,不同的是这颗树只有那些可见节点的信息。
举个例子,如果一个节点被设置为了display:none,这个节点就不会出现在布局树上面但是visibility:hidden的节点会出现在布局树上面。同样的,如果有一个伪元素节点是显示状态,它也会出现在布局上,但不会出现在DOM树上。
3.2.2 绘画阶段,由布局树生成绘画树
主线程会遍历之前得到的布局树来生成一系列的绘画记录。绘画记录是对绘画过程的注释,例如“首先画背景,然后是文本”,类似我们用canvas绘画图形的时候,从一个点画到另一个点的操作记录。
如图,我们可以看到,布局树生成绘画树会少一些节点:
这里,我们先看一个现象:
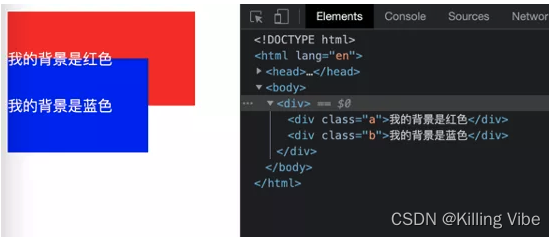
如图所示,a节点和b节点在文档结构上是并列的关系,然后我们通过负margin来把a,b节点设置为重叠,然后会出现这种情况:b的背景会盖到a的背景上,但是却没有覆盖到a的文字上,这是由于a和b不满足下面列的几点要求,没有形成自己的绘画层,他们公用一个绘画层,而绘画记录生成的顺序是先画背景再画文字,所以就会出现这种情况。
要想拥有独立的绘画层,需要满足以下条件:
-
页面的根对象
-
具有显式 CSS 位置属性(相对、绝对或转换)
-
是透明的
-
有 CSS 过滤器
-
具有三维(WebGL)上下文或加速二维上下文的 canvas 元素
-
video 元素
3.2.3 合成阶段,由绘画树生成图形树,每个图形层也就是我们平时所说的合成层
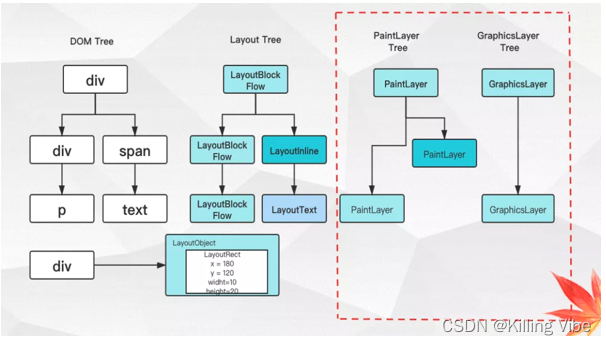
它和上面介绍的布局树到绘画树的过程类似,只有满足特殊条件的绘画层,才能形成自己的图形层,否则,会使用它第一个祖先元素的图形层。
要想拥有独立的合成层,需要满足以下条件:
-
层具有三维或透视变换 CSS 属性
-
层由使用加速视频解码的 video 元素使用
-
层由具有 3D 上下文或加速 2D 上下文的 canvas 元素使用
-
层用于合成插件
-
层使用 CSS 动画作为其不透明度,或使用动画 webkit 变换
-
层使用加速 CSS 过滤器
-
层的子体是合成层
-
层有一个具有较低 z 索引的同级,该同级有一个合成层(换句话说,该层与合成层重叠,应在其上渲染)
像我们平时使用的:

我们可以在chrome的控制台 查看当前页面的所有图形层。
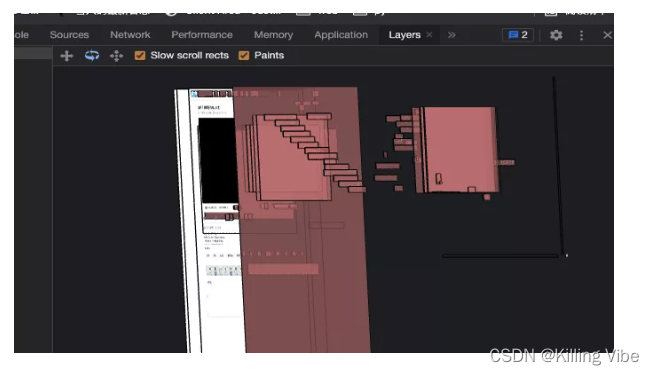
css3动画在执行的时候,浏览器其实只是移动对应的图形层。
3.3 合成线程任务
- 分割 将图层分割为256x256 或者 512x512的图块
- 栅格化 是指将图块上的绘画记录转换为位图,位图存在gpu的内存里
- 绘画四边形 包含图块在内存的位置以及图层合成后图块在页面的位置之类的信息
- 合成帧 代表页面一个帧内容的绘画四边形集合
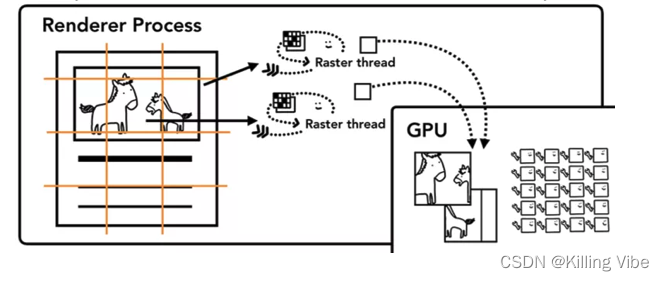
合成线程会将每个图层分别分割为图块,然后把图块数据发送给一系列光栅线程,合成线程也会给不同的光栅线程赋予不同的优先级,进而使那些在视窗中的或附近的图块可以先被栅格化。光栅线程会栅格化每个图块并且把它们存储在GPU的内存中。当我们使用css3动画,并提升合成层之后,每个合成层在做动画的时候,直接操作的是栅格化后的图层,而不需要每次都栅格化。
顺便说一下:栅格化分为软件栅格化,和硬件栅格化,现在的新版浏览器基本上都是采用GPU硬件栅格化,又称为快速栅格化。当图层上面的图块都被栅格化后,合成线程会收集图块上面叫做绘画四边形的信息来构建一个合成帧,然后合成线程会生成一系列的指令调用。由于沙盒的限制,渲染器进程不能直接调用操作系统提供的 3D api。因此,需要一个单独的进程来访问,这就是前面所说的GPU 进程。
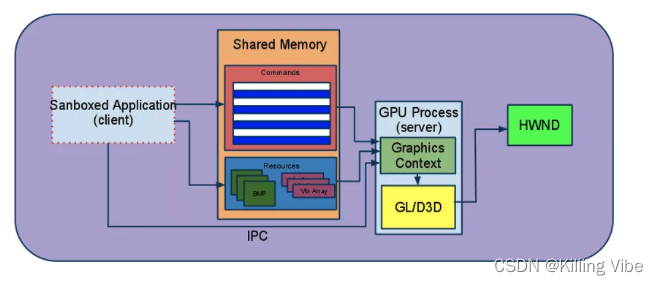
3.4 gpu进程
合成线程生成一系列的指令调用都会被序列化并存入一个共享内存中,然后gpu进程从共享内存中提取序列化命令,解析它们并执行适当的图形调用。
GPU 渲染完成后会将渲染结果存入帧缓冲区,视频控制器会按照 VSync 信号逐帧读取帧缓冲区的数据,经过数据转换后最终由显示器进行显示。
(四)弹幕实现原理
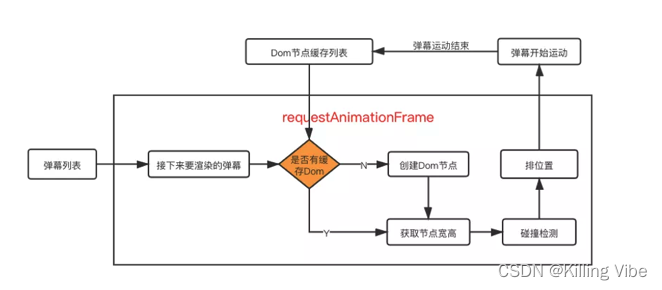
首先,我们会有一个弹幕列表,用来维护当前视频的所有弹幕,然后我们会逐帧去获取下一帧将要展示的弹幕,这边有个判断,是否有缓存的dom节点,如果没有,我们会创建一个dom节点,并把弹幕填充进去。然后,获取该条弹幕的宽高,来和已经出现在屏幕上的弹幕做碰撞检测,确定该条弹幕应该展示在哪一条轨道上,之后开始做位移动画。当弹幕已经完全运动出显示区域,我们会把这条弹幕的dom节点缓存起来,然后给后面的弹幕复用(因为创建dom节点也是一个很消耗性能的操作)。
转载请注明:
转载自雪人大佬的文章,仅学习使用(无商业用途),搬运侵删,可私信博主。