
众所周知,ChatGPT模型它所学习到的知识都是截止到2021年,所以当我们向ChatGPT询问2021年以后发生的事情时,ChatGPT往往会给出完全错误的答案,另外我们还发现ChatGPT对一些常识性的问题,如历史或文学方面的问题,有时候也会给出一些错误答案,这有可能是ChatGPT模型没有学习到相关知识所造成的。
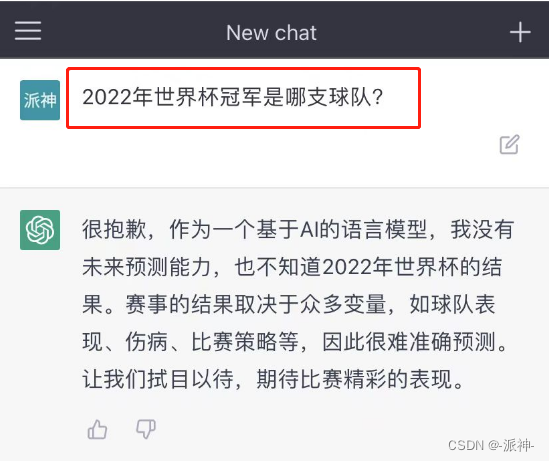
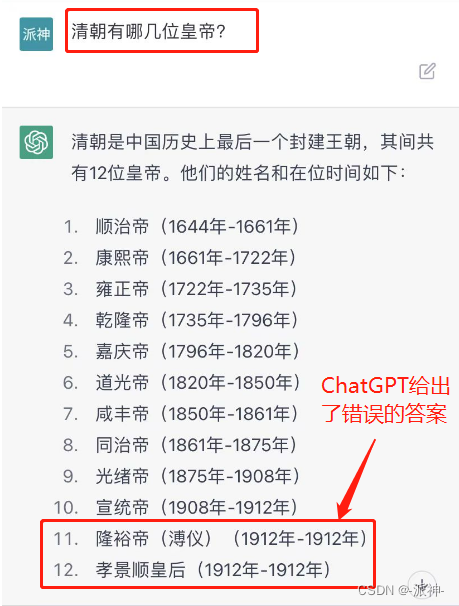
但是百度搜索却能给出我们正确答案:

如何让ChatGPT学习到2021年以后的知识?
如何让ChatGPT不犯常识性错误?
因为百度搜索能够提供最新最及时的信息,所以我们可以开发一个网页爬虫爬取百度搜索结果,再将它送给ChatGPT进行学习,这样ChatGPT就能掌握最新,最及时的信息,同时ChatGPT也可能不再会犯常识性错误!
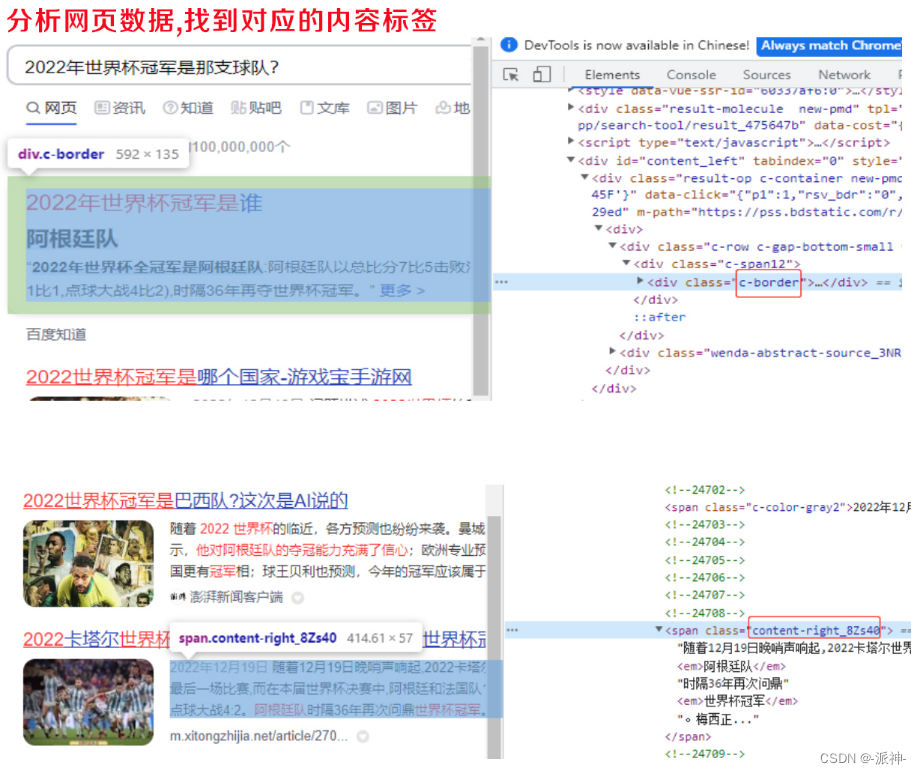
开发网页爬虫,爬取百度搜索的的结果
这里我们的思路是先开发一个百度搜索的网页爬虫,当用户向ChatGPT询问2021年以后发生的事情时,我们可以先对问题进行百度搜索,得到搜索结果以后,我们再将它喂给ChatGPT进行学习,这样ChatGPT就能学习到最新最及时的信息了,从而可以避免ChatGPT给出错误的答案,不过首先我们需要安装两个python包:
pip install openai
pip install selenium
接下来我们需要发一个百度搜索的网页爬虫函数:scraping_data(),该函数通过参数question来进行后台浏览器的百度搜索,在得到搜索结果后我们提取class name等于“c-border”的标签内的文字信息,c-border标签内的信息一般是位于百度搜索结果顶部的信息,这些置顶信息是经过百度提炼过的准确的信息:
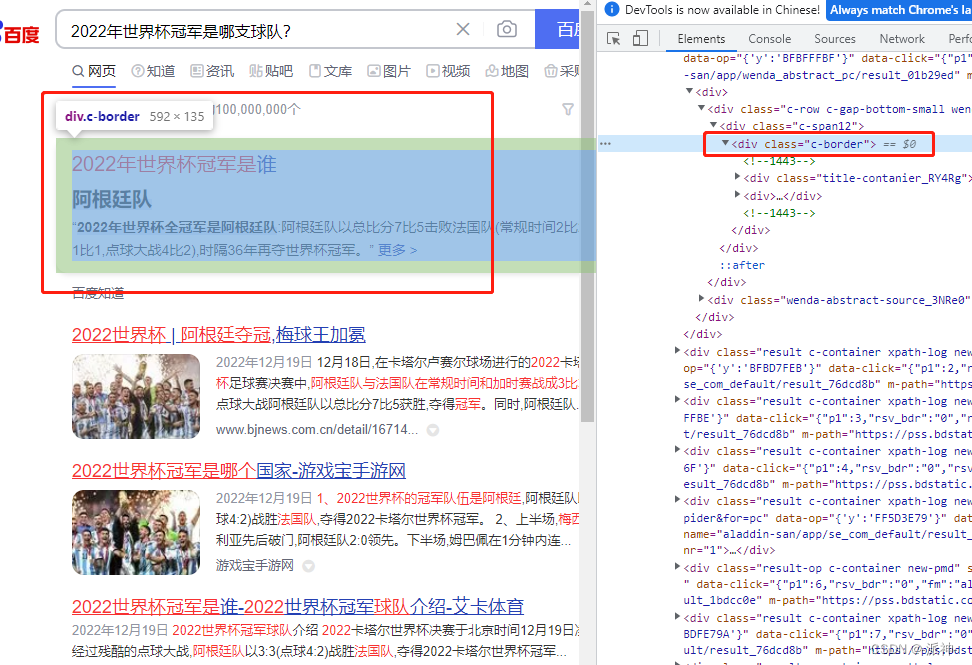
我们首先获取置顶信息,如果置顶信息不存在,那么我们再获取剩下每一条搜索结果内容,而所有的搜索结果内容都存放在class name等于“'content-right_8Zs40'”的标签内:
import openai
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import warnings
warnings.filterwarnings("ignore")
#爬取百度搜索的结果
def scraping_data(question):
options = webdriver.chrome.options.ChromiumOptions()
options.headless=True
url="https://www.baidu.com/s?wd="+question
brower=webdriver.Chrome(options=options)
brower.get(url)
brower.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(3)
data=[]
#爬取 c-border的内容
border=brower.find_elements(By.CLASS_NAME ,'c-border')
for item in border:
data.append(item.text)
#如果c-border数据不存在,则爬取 content-right_8Zs40 的内容
if len(data)==0:
content=brower.find_elements(By.CLASS_NAME ,'content-right_8Zs40')
for item in content:
data.append(item.text)
return data
question='2022年世界杯冠军是那支球队?'
result=scraping_data(question)
print(result)
让LLM与网页爬虫相结合
这里我们要将大型语言模型如ChatGPT和网页爬虫相结合,我们要做的是首先对用户提出的问题进行百度搜索,然后将搜索结果和当前问题一起喂给ChatGPT,这样ChatGPT就可以学习到最新最及时的信息,从而不再会给出错误的答案。
#申请的api_key
openai.api_key = "你的API_key"
def get_answer(data):
response = openai.Completion.create(
model="text-davinci-003",
prompt="\n".join(data),
temperature=0.5,
max_tokens=2048)
return response.choices[0].text
def ask_question():
flag=True
print()
greeting="\033[1;31mChatGPT: 我是ChatGPT聊天机器人,我可以回答您的任何问题!如果您想退出,请输入:quit\033[0m"
print(greeting)
print()
while(flag==True):
question = input()
if(question!='quit'):
#爬取百度搜索的结果
data = scraping_data(question)
data.append(question)
#将百度搜索的结果和当前问题一起喂给ChatGPT
answer=get_answer(data)
answer = answer[1:]
print(f"\033[1;31mChatGPT:{answer}\033[0m")
print()
else:
flag=False
print()
print("\033[1;31mChatGPT:后会有期,bye!\033[0m")
ask_question() 
这里可以发现当我们向ChatGPT提出关于2022年世界杯冠亚军球队问题时,ChatGPT总能给出正确的答案,这是因为ChatGPT学习了我们的百度搜索结果并从中提炼出了正确的答案。
总结
由于当前ChatGPT模型所学习到的知识是截止到2021年,那么当用户向ChatGPT询问2021年以后发生的事情时,ChatGPT往往会给出千奇百怪的错误答案,为了避免这样的问题,我们可以可以利用百度搜索的结果来让ChatGPT学习,从而可以在很大程度上降低ChatGPT给出错误答案的概率。