KMP算法常用于字符串匹配,在匹配介绍KMP算法之前,先介绍如何暴力地匹配字符串
对两个字符串,用两个指针依次比较,代码:
for (int i = 1; i <= n; i ++ )
{
bool flag = true;
for (int j = 1; j <= m; j ++ )
{
if (s[i + j - 1] != p[j])
{
flag=false;
break;
}
}
}如果不匹配,相当于将短的那个字符串向右移动一位继续匹配,但这样依次比较的效率是非常低的

而KMP则是利用已经匹配好的字符串这个有效信息来减少重复的匹配

例如有图中,当长串和短串匹配成功了一段区间之后,在图中i和j+1的位置匹配失败了,按照常规思路我们是需要将短串向后移动一个位置继续重新开始匹配,但kmp就是利用好已经匹配好了的信息来减少匹配次数,就是令j=ne[j],从ne[j]的位置开始匹配,因为在图中我们用黑线画的部分其实是等效的,所以这一部分我们是不需要去匹配的,那么如何求这个ne[j]数组呢
这里要引入一个概念,就是前缀和后缀:

现在思路我们知道了,那么如何用代码来实现呢?
思路:

代码:
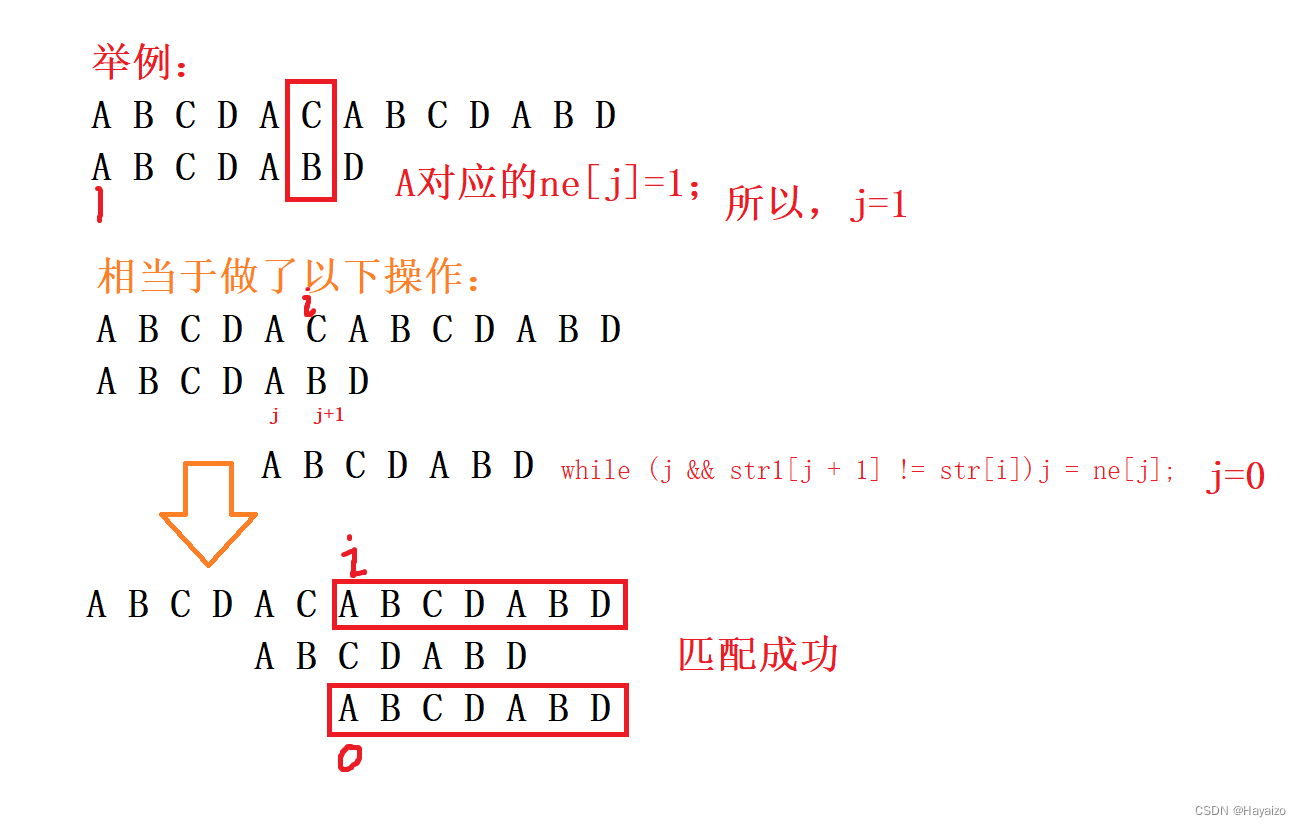
for (int i = 2, j = 0; i <= m; i++)
{
while (j && str1[i] != str1[j + 1])j = ne[j];
if (str1[j + 1] == str1[i])j++;
ne[i] = j;
}接下来来模拟一个样例:
题目:

AC代码:
#include<iostream>
#include<cstring>
using namespace std;
const int N = 1000010, M = 10010;
char str[N], str1[M];
int ne[N], n, m;
int main(void)
{
cin >>(str + 1) >>(str1 + 1);
int n = strlen(str+1), m = strlen(str1+1);
//获取ne数组
for (int i = 2, j = 0; i <= m; i++)
{
while (j && str1[i] != str1[j + 1])j = ne[j];
if (str1[j + 1] == str1[i])j++;
ne[i] = j;
}
//开始匹配
for (int i = 1, j = 0; i <= n; i++)
{
while (j && str1[j + 1] != str[i])j = ne[j];
if (str[i] == str1[j + 1])j++;
if (j == m)
{
printf("%d\n", i - m+1);
}
}
for (int i = 1; i <= m; i++)
{
printf("%d ", ne[i]);
}
return 0;
}