继续填坑,这回到SHAP,这个是选修,有兴趣可以看看。
我们建立了十个ML模型,如果选出了Xgboost、LightGBM、Catboost这种树模型(大概率也是这些最厉害了),那就可以用SHAP进行模型可视化。
(1)首先,使用pip install shap进行安装,记得是在Anconda Prompt敲入:

(2)然后,我们以Xgboost为例子,开整:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('X disease code fs.csv')
X = dataset.iloc[:, 1:14].values
Y = dataset.iloc[:, 0].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.30, random_state = 666)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
import xgboost as xgb
param_grid=[{
'n_estimators':[35],
'eta':[0.1],
'max_depth':[1],
'gamma':[0],
'min_child_weight':[5],
'max_delta_step':[1],
'subsample':[0.8],
'colsample_bytree':[0.8],
'colsample_bylevel':[0.8],
'reg_lambda':[9],
'reg_alpha':[5],
},
]
boost = xgb.XGBClassifier()
classifier = xgb.XGBClassifier()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, n_jobs = -1, verbose = 2, cv=10)
grid_search.fit(X_train, y_train)
classifier = grid_search.best_estimator_
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
print(cm_train)
print(cm_test)
#绘画SHAP相关图:使用前先安装SHAP:pip install shap
import shap
explainer = shap.TreeExplainer(classifier)
shap.initjs()
shap_values = explainer.shap_values(X_train)
shap.summary_plot(shap_values, X_train)输出如下:
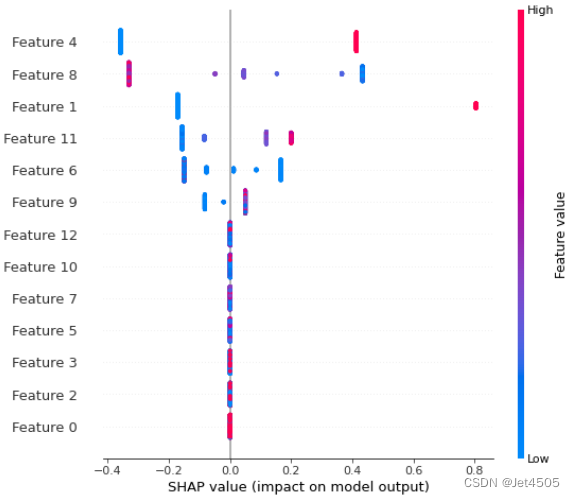
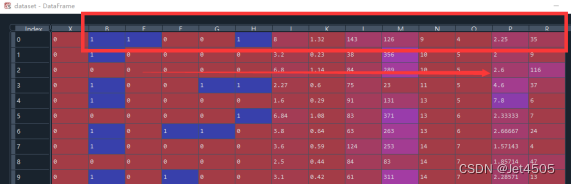
这里的Feature 0 就是当初导入的第一个特征B,从左到右的顺序:
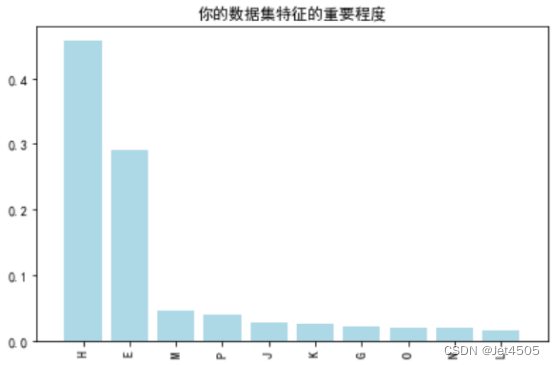
 可以和Xgboost自带的重要指数相比较,大同小异:
可以和Xgboost自带的重要指数相比较,大同小异:
具体理论和解释见以下网址,就不细说了:
② https://www.kaggle.com/code/dansbecker/shap-values/tutorial