1 简介
本文根据2022年10月《WEKWS: A PRODUCTION FIRST SMALL-FOOTPRINT END-TO-END KEYWORD SPOTTING TOOLKIT 》翻译总结的。作者为西北工业大学航海学院张晓雷老师团队、西工大音频语音与语言处理研究组谢磊老师团队、WeNet 开源社区等。
WeKWS是一个可以投入生产使用、容易构建、易应用的端到端(end-to-end (E2E) )关键词识别工具(Keyword spotting )。Keyword spotting(KWS)指从连续语音流中识别预定义的关键词。唤醒词识别(wake-up word(WuW))是KWS的一种。
开源地址:GitHub - wenet-e2e/wekws: Production First and Production Ready End-to-End Keyword Spotting Toolkit
在物联网(IoT)等设备进行语音唤醒需要使用一个占用内存小的脚本、低计算成本,同时低延迟、高准确率。而目前的工具太复杂,如Kaldi、Fariseq、Honk等。为此,我们建设了WeKWS,其有如下条件:
- 免对齐(Alignment-free ):不需要使用自动语音识别(ASR)或者语音活动检测(speech activity detection :SAD)来进行关键词对齐或者关键词结束时间戳,简化了KWS训练。
- 可以投入生产使用(Production ready ):跨越研究和投入生成使用的鸿沟。可以采用Torch Just In Time (JIT) 导出,转换为Open Neural Network Exchange(ONNX) 格式,容易在多个开发环境中采用。(Pytorch模型中2种常用的推理加速方案:ONNX 和 TorchScript)。
- 轻量化(Light weight):只依靠Pytorch;
- 高准确率。
2 WeKWS
2.1系统设计
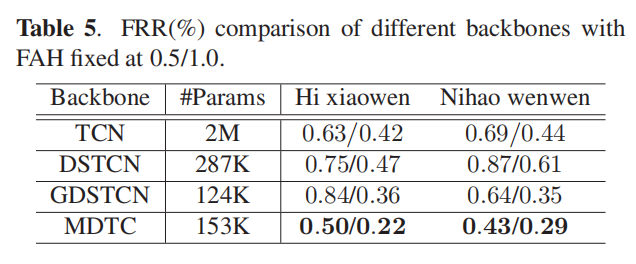
如下图包括3层。
2.1.1第一层: Data preparation module and an on-the-fly feature extraction and argumentation.
在数据准备模块,是准备语音清单和话语水平的关键词标签,方便模型训练。WeKWS使用在线(on-the-fly)特征提取。每个语音首先被重采样到某个特定的采样率,然后速率扰动和梅尔滤波特征提取( speed perturbation and Mel-filter bank feature extraction)。输入采用了Feature-level Specaugment 的数据扩充方法。相比离线方法,这种在线方法节省磁盘使用,而且丰富了训练样本的多样性,提升了模型的健壮性。
2.1.2 第二层:Model training and testing
我们可以使用多种流行的KWS 骨干网络(backbone)和一个精炼的max-pooling KWS目标函数。 骨干网络可以选择RNN、temporal convolutional network (TCN) 、multiscale depthwise temporal convolution (MDTC) 等。
2.1.3 第3层:Model exportation and development.
训练的模型支持TorchScript和ONNX输出,所以可以很容易的应用于不同的平台。现在我们支持3个主要的平台,如x86、安卓、树莓派(Raspberry Pi)。而且支持float32模型和量化的int8模型,量化的int8模型在嵌入式设备如ARM的安卓和树莓派上可以提升预测速度。
2.2 模型结构
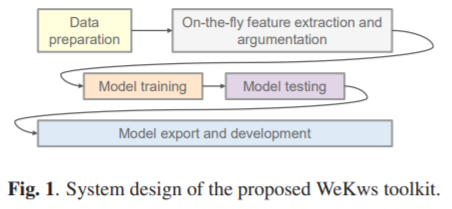
如上图所示,模型包括4部分,包括全局倒频谱均值和方差归一化层(global cepstral mean and variance normalization (CMVN) )、线性层(将输入的特征维度转换为骨干网络需要的维度)、骨干网络、多个二值分类器。每一个二值分类器采用sigmoid来预测一个关键词的后验概率,多个二值分类器就支持多个关键词。
WeKWS 骨干网络(backbone)目前支持如下3中:1)RNN或者其改进版本LSTM;2)TCN,或者其轻量化版本深度分离TCN,即DS-TCN(depthwise separable TCN);3)MDTC。
在所有基于卷积的神经网络中,我们使用因果卷积(causal convolutions)。
2.3 精炼的max-pooling KWS目标函数
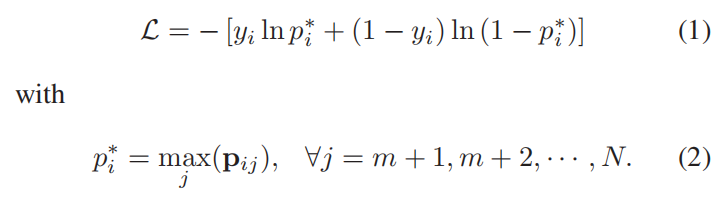
其中p是预测的后验概率。m是关键词的最小持续时间帧,m是在训练集中统计计算出来的。N是第i个话语的帧的数量。
通过使用max-pooling 损失函数,模型自动学习关键词的结束时间戳,所以不用依赖关键词的对齐和关键词的结束时间戳。特别地,对于正样本,max-pooling 损失仅优化高后验概率的帧,忽略其他帧。对于负样本,max-pooling 损失会最小化高后验概率的帧,所以负样本的所有帧的后验会被最小化。
3 实验
3.1 实验建设
我们使用Mobvoi (SLR87) , Snips 、 Google Speech Command (GSC) 数据集评估我们的WeKWS。
Mobvoi是一个普通话语料库,应用于唤醒任务。其有两个关键词,每个关键词有36k语音。非关键词语音大约183K.
Snips是一个众包唤醒词语料库,其关键词是“Hey snips”,大约有11K的关键词语音,和86.5K非关键词语音。
Google Speech Command包括64721个一秒长的记录,由1881位不同的说话者说的30个单词。
我们使用40维梅尔过滤器特征( Mel-fifilter bank (Fbank) )作为模型输入,其采用25毫秒窗口和10毫秒窗口移动。
我们使用Adam。batch size为128.训练80 epochs。
3.2 实验结果
下表是和LF-MNI-based的方法比较(其依靠基于图的编码算法)。误拒绝率(false rejection rate,FRR)为实际辨别中误拒绝发生的百分比。我们的方法WeKWS相比对FRR进行了下降,效果较好。
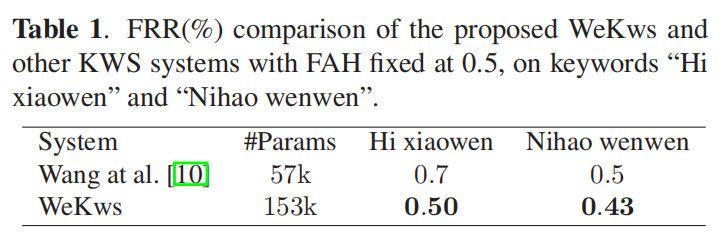
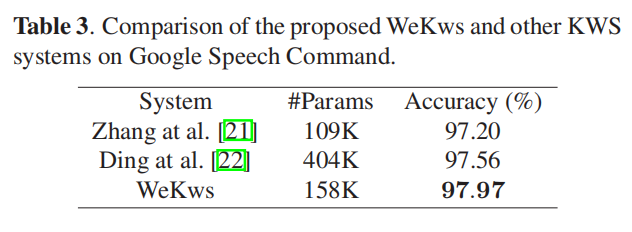
下表2、3是WeKWS和另外两个端到端方法进行比较。

3.3 消融实验
max-pooling方法较好。
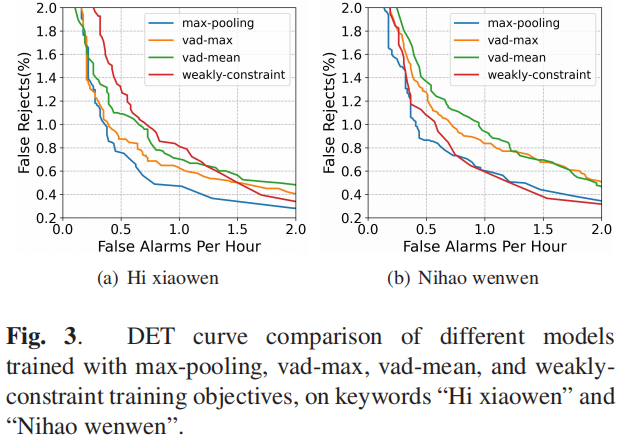
MDTC骨干较好。