目录
1.集成学习基本思路
集成学习(classifier combination)是将多个数据挖掘模型(基模型,base classifier)集成在一起进行学习。多个基模型对数据集进行学习,并分别输出结果,然后集成学习模型再通过一定的方法将这些结果进行整合,最终形成集成学习模型的结果。
2.集成学习模型结合策略
(1)平均法&加权平均法(集成回归模型的结合策略)
简单平均法:
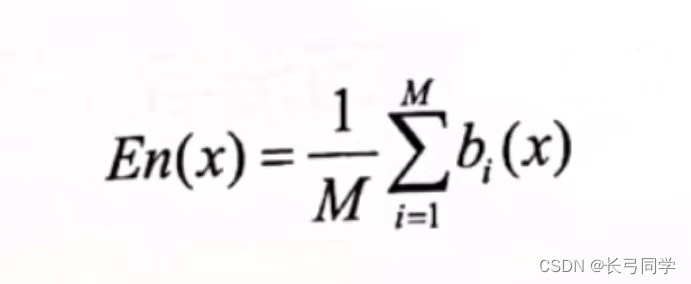
加权平均法:
(相比于简单平均法,增加了权重系数参数,更容易出现过拟合)
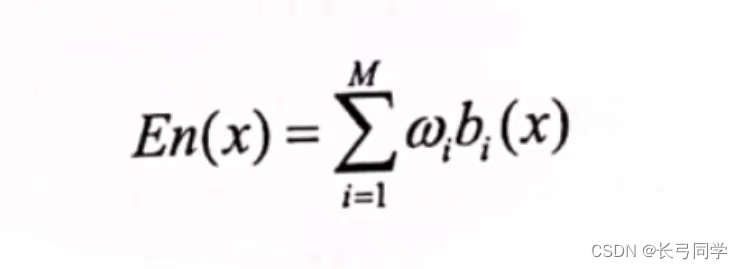
实际使用过程中发现,加权平均法的结果有时还不如简单平均。
(2)相对多数投票法&加权投票法(集成分类模型的结合策略)
相对多数投票法:
获得最多票数的类别为集成模型的输出类别(若有多个类别获得相同的最高票,则随机从这些类别中选取一个作为最终的输出。)
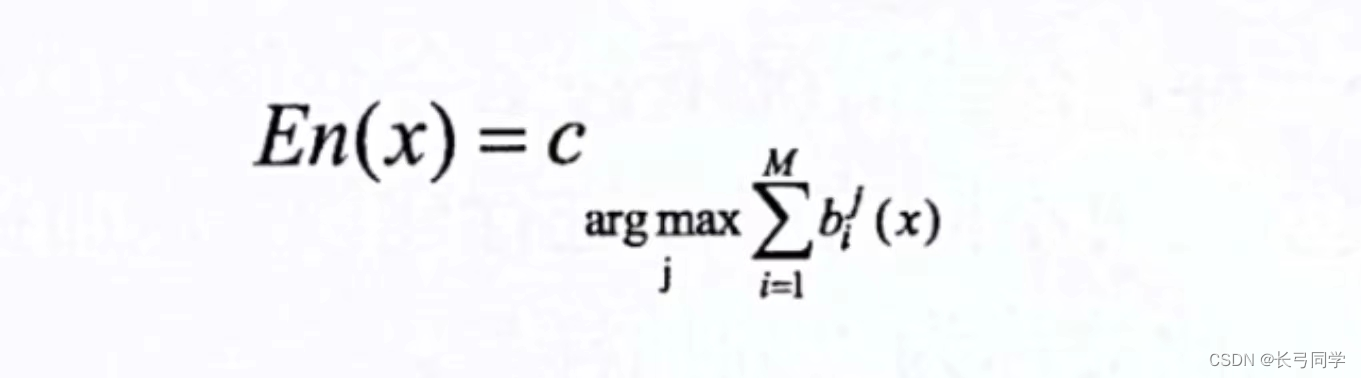
加权投票法:
(是投票法的一种特殊形式,加权投票法中,不同的基模型投票的权力大小是不一样的aaaaa)
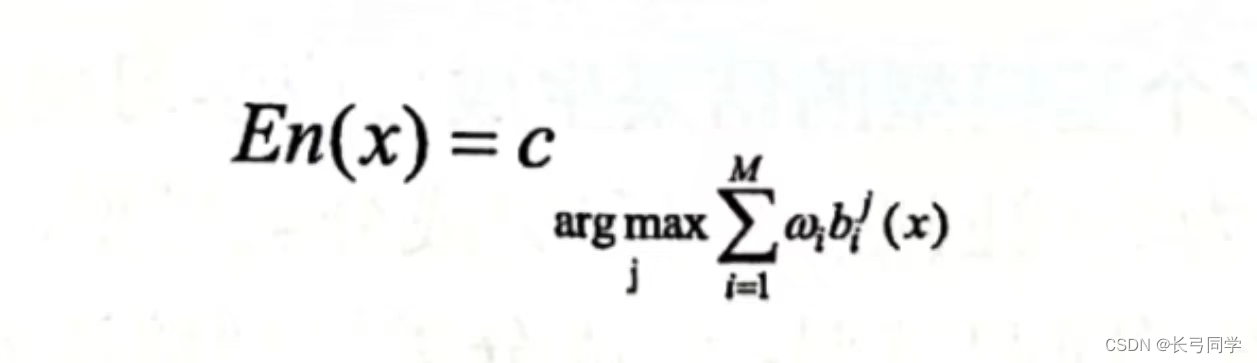
3.Bagging方法和随机森林
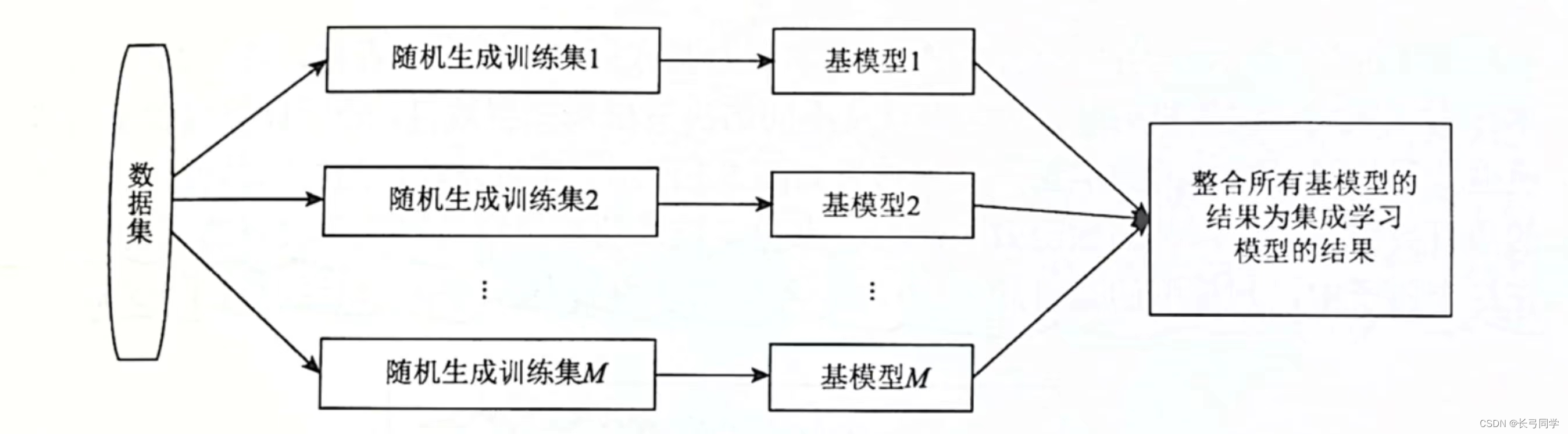
(1)Bagging方法
Bagging方法是一种并行式集成学习方法,其基本结构如下:
(2)随机森林(random forest)
随机森林是Bagging方法的一个具体实现。
基本步骤如下:
1.选取基模型训练样本
2.训练决策树基模型
3.集成多棵决策树
(随机森林中,较多的决策树基模型可以获得较好的预测效果)
4.Boosting方法和Adaboost
(1)Boosting方法
boosting方法是一种串行训练基模型,其基本结构如下:
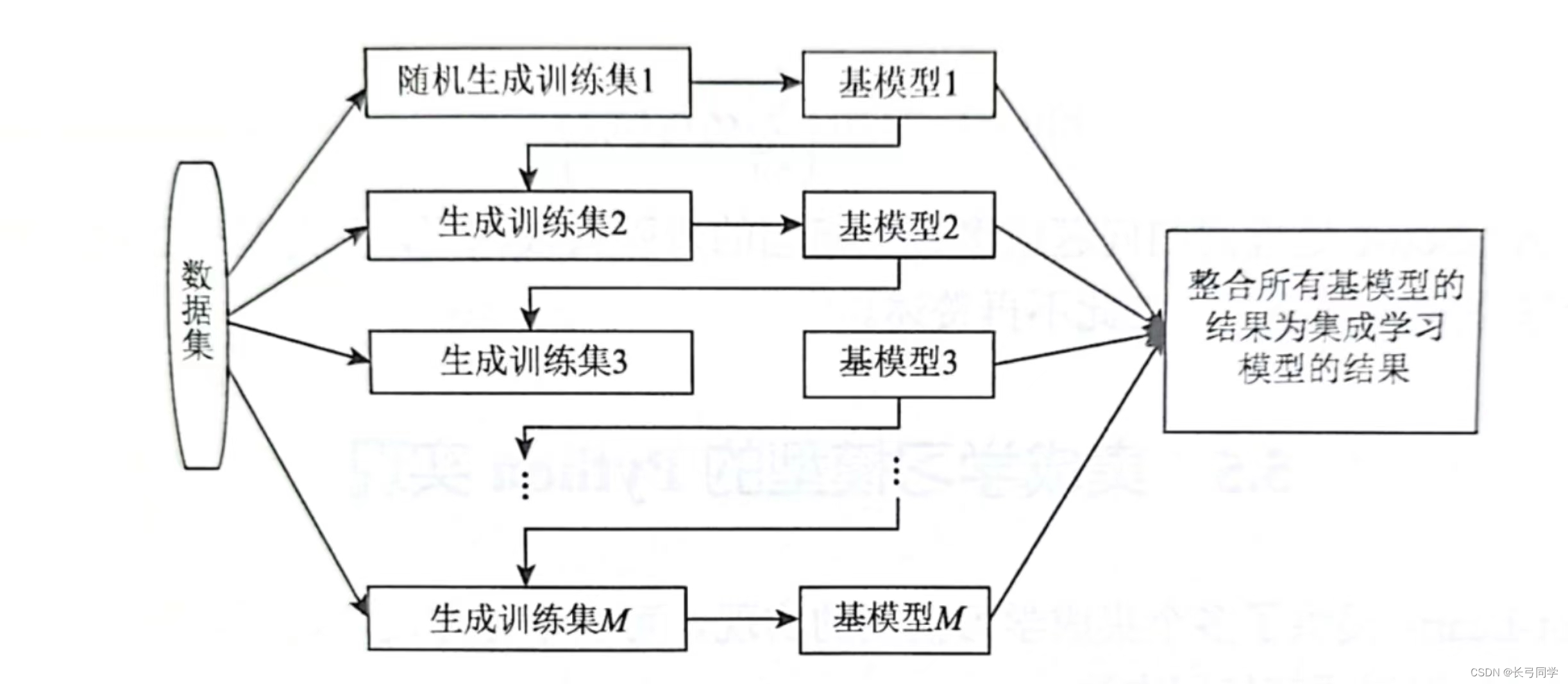
(boosting方法中基模型的训练样本与上一个基模型的预测结果相关,当前基模型重点关注上个基模型预测错误的样本)
(2)Adaboost方法
Adaboost方法(Adaptive Boosting)是Boosting集成学习的具体实现。
具体步骤:
1.初始化样本权重
2.训练基模型
3.计算基模型的权重
4.更新样本的权重
5.迭代训练多个基模型
6.结合基模型的预测结果
5.集成学习python实现
sklearn库中提供了多个集成学习模型的使用,可以直接进行调用。
实例代码(随机森林分类模型函数的使用):
这里用的是上上篇中的代码进行修改的,可以看到,相比于使用单个高斯朴素贝叶斯分器进行训练,用随机森林训练出来的模型准确率更高。
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import confusion_matrix
from matplotlib import pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier
#训练模型函数
def model_fit(x_train,y_train,x_test,y_test):
model=RandomForestClassifier(n_estimators=50)
model.fit(x_train,y_train)#对训练集进行拟合
# print(model.score(x_train,y_train))
print("accurancy:",model.score(x_test,y_test))
Y_pred=model.predict(x_test)
cm=confusion_matrix(Y_pred,y_test)
return cm
#混淆矩阵可视化
def matplotlib_show(cm):
plt.figure(dpi=100)#设置窗口大小(分辨率)
plt.title('Confusion Matrix')
labels = ['a', 'b', 'c', 'd']
tick_marks = np.arange(len(labels))
plt.xticks(tick_marks, labels)
plt.yticks(tick_marks, labels)
sns.heatmap(cm, cmap=sns.color_palette("Blues"), annot=True, fmt='d')
plt.ylabel('real_type')#x坐标为实际类别
plt.xlabel('pred_type')#y坐标为预测类别
plt.show()
if __name__ == '__main__':
cancer = load_breast_cancer()
x, y = cancer.data, cancer.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=3)
cm=model_fit(x_train,y_train,x_test,y_test)
matplotlib_show(cm)
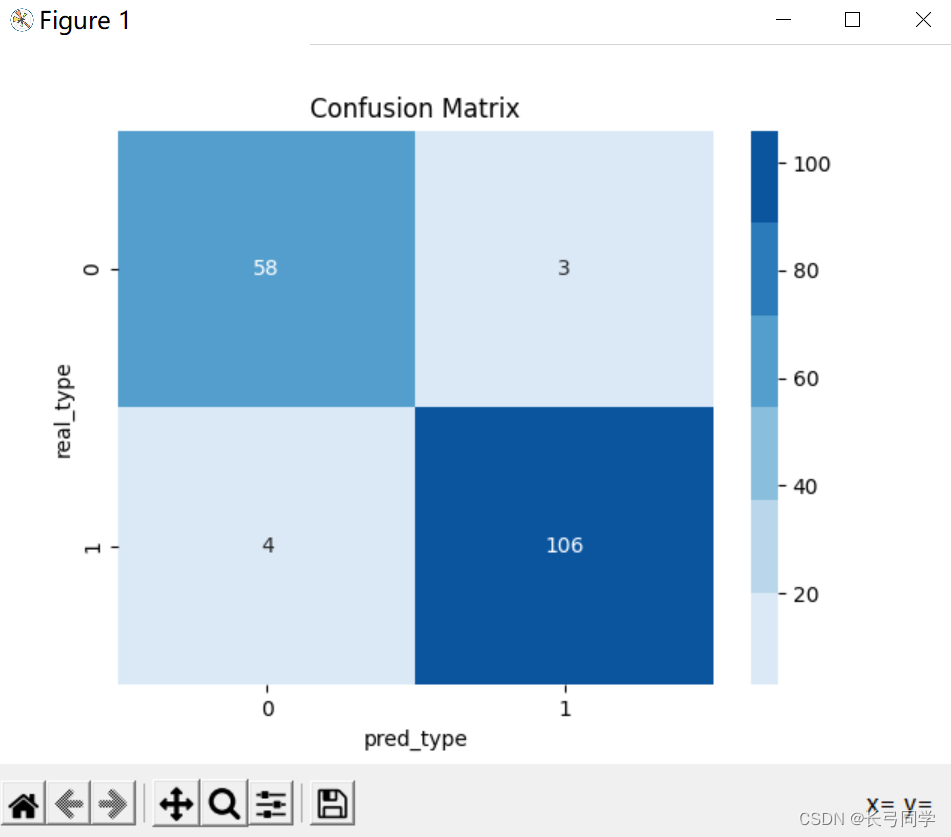
运行结果:(准确率和预测结果图)