零、前言
这是笔者在深夜debug时候,临时产生的感悟。因为这次debug过程较为崎岖,值得总结。
在这篇博客种您不会收获技术层面的知识,但是也许会获得debug工作layer的启示。 这也许会在另一些方面有助于推进您的代码工作。
一、debug问题描述与逻辑推理
1.1 问题描述
在笔者将深度学习系统部署到生产环境时,出现了一些问题。
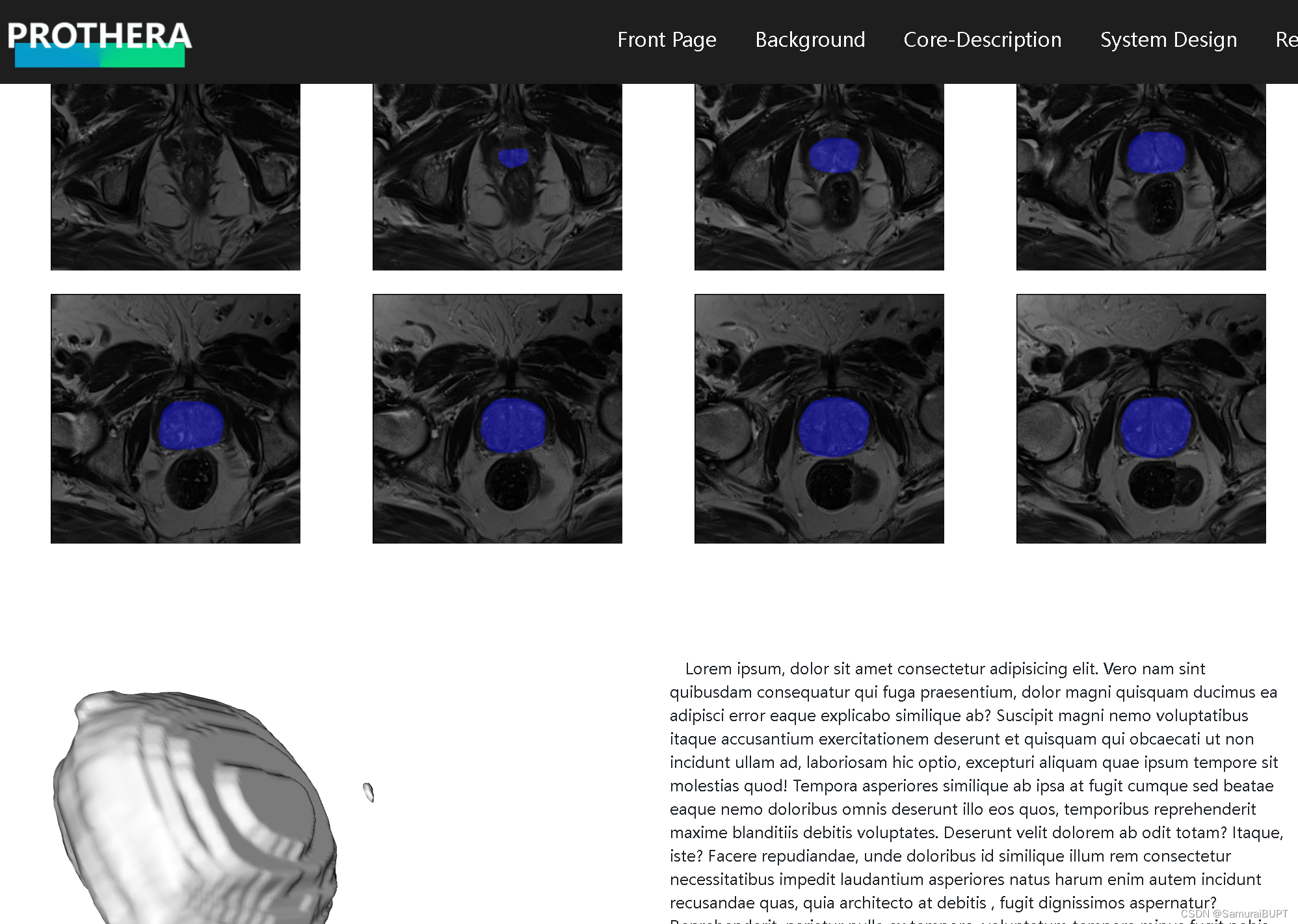
图一:在 w i n d o w s 系统上尝试搭建的 s e r v e r 以及三维重建结果 图一:在windows系统上尝试搭建的server以及三维重建结果 图一:在windows系统上尝试搭建的server以及三维重建结果

图二:在 l i n u x 系统上尝试搭建的 s e r v e r 以及三维重建结果 图二:在linux系统上尝试搭建的server以及三维重建结果 图二:在linux系统上尝试搭建的server以及三维重建结果
从这里不难看出:两份三维重建结果大相径庭,前者还算勉强能看,但是后者缺难以入目。
为什么会这样呢?
1.2 查找原因
三维重建的过程是根据输出的mask而进行提取轮廓并重建的,如果重建的结果有问题,一定是输出的mask顺序存在问题。
于是笔者紧接着对windows和linux两个环境输出的mask做了比较:

图三:两个系统环境下输出的 m a s k s 图像序列 图三:两个系统环境下输出的masks图像序列 图三:两个系统环境下输出的masks图像序列
- 上图是windows系统写输出的masks序列,分别从
mask_0.png到mask_19.png - 下图是linux系统写输出的masks序列,图片命名也是分别从
mask_0.png到mask_19.png
仔细比较,发现windows的序列基本正常,而linux的masks图像序列,虽然确实预测结果与上图无误,但是输出的sequence发生了问题。
下图的mask_0.png对应的是上图的mask_8.png,怎么会这样呢?
1.3 原因揭晓
其实是linux文件排序的问题。
windows系统在读取文件的时候,使用os.listdir()函数,会依据默认顺序排序,而windows的排序方式就是文件的名字。
但是linux系统的文件排序方式是根据文件的创建时间(修改时间)来定序的,也就是说,linux中的os.listdir()函数最终读取出来的序列可能是这样的:
images: ['mask_8.png', 'mask_0.png', 'mask_5.png', 'mask_3.png', ..., 'mask_17.png']
也就是乱序排布的。那么在推理时候,调用到的dataset中的__getitem__函数中,就要写好读取的方案:
self.image_names = os.listdir(image_folder)
self.image_names.sort(key=lambda x: int(x.split(".")[0].split("_")[2]))
也就是在下面加一句话,对该列表进行排序,以便后续的读取照片的函数能够按顺序读取。
只有按顺序读取,才能按标准顺序输出。
二、Debug经验与反思
2.1 综述
这个答案看起来很简单,实际上也很简单,不过笔者是怎么思考到的,这个值得记录,是笔者debug生涯的一个里程碑式的节点。
我们接触到一个问题的时候,比如说这个问题,最初是有些不知所措的,不知道到底是什么原因导致的输出图像的序列有问题,因为该系统较为庞大。
是输出时候的cv2.imwrite()的方式有问题?还是中间处理的逻辑有问题?还是读取时候的问题?这几大问题分别的根源究竟在哪里?
代码系统一旦庞大,问题就多了起来,因为确实不知道到底是哪一个环节出了问题,换言之:哪一个环节都有可能出问题
2.2 破解之法
解决bug的过程,一定是一个**依照逻辑顺序、循序渐进的过程。**他不会是东一下、西一下,兜兜转转就出来了的谜一般的过程。因为代码本身就是有逻辑性的工作,要解决这个问题,必须依靠有逻辑的方法。
回想笔者解决整个问题的过程,我从最初的迷茫到后续的理清思路,层层递进,层层不断肯定哪些地方一定没问题,哪些地方可能存在问题,一层一层抽丝剥茧推理而出,最终找到问题所在。
这里想简单以解决这个bug的思路为例子,对上述论点进行证明:
- 发现两个操作系统的输出不同,怀疑是操作系统的问题
- 发现是两个系统输出的图像序列不一样,可能是最后的cv2.imwrite(‘mask_{k}.png’, xxx)等,最后输出图片的函数出了问题
- 考察后发现
k仅仅是一个索引,而决定这个索引的方法并没有问题,就说明不是在输出层的问题,需要再往前找(这一步其实就是在肯定一些东西、否定一些东西,这个肯定与否定是很重要的,决定了能不能继续往下推导) - 探究是否是推理过程中出现的问题
- 严查推理过程,发现推理的代码没有问题,那就再往前走,看看是否是数据集dataset加载的问题
- 找到数据集加载可能出现问题,就在
os.listdir()函数中,可能导致乱序 - 果然是这个函数在linux系统上有乱序,输入的图像都是乱序的,输出肯定也不会是正确的顺序,于是改正。
至此,找到了问题所在,并且做出了解决方案。
回顾整个过程,发现debug过程无意中好像用到了常用算法中的BFS广度优先遍历的思想。
一层一层对代码内容进行核查,关键是肯定了什么、否定了什么。
这个肯否定的过程,又与算法中常说的剪枝有异曲同工之妙。
至此,一些东西好像串成线:
- acm常用算法
- debug与逻辑性
- debug排查方案与肯否定方案(剪枝)
- 项目代码构建与架构
过往学过的一些东西,在此刻都聚集在一起。
经此一番,在代码中的修炼又上升一个台阶。