说明:最近在看《面向知识服务的知识库结构理论与方法》蒋勋,将自己研究可能用到的知识进行梳理和摘录,并加入部分自己的主观想法,由于17年的书,有些思想或描述已过时,但可借鉴的思想还是有不少的。
目录
一、设计概述
应急情报视角的知识库框架是一个应急响应的知识库集群,集群中的知识库分门别类,各类知识库在应急响应中发挥着不同的作用,是应急响应决策支持的重要手段和智囊。
所构建的应急响应知识库,需要把突发事件事前、事中、事后等不同阶段中知识库应当完成哪些功能,必须起到什么样的作用,如何将知识库与应急响应紧密对接,综合考虑其中。
在应急事件处理过程中,不同的角色也需要不同的知识来帮助自己工作或了解一些基本常识。所以,应急响应知识库必须考虑不同层面的相关人员的知识储备,也必须考虑在处理应急事件的不同阶段中的知识补充,只有满足这样条件的知识库,才会在突发事件快速响应的应对中发挥重要作用。
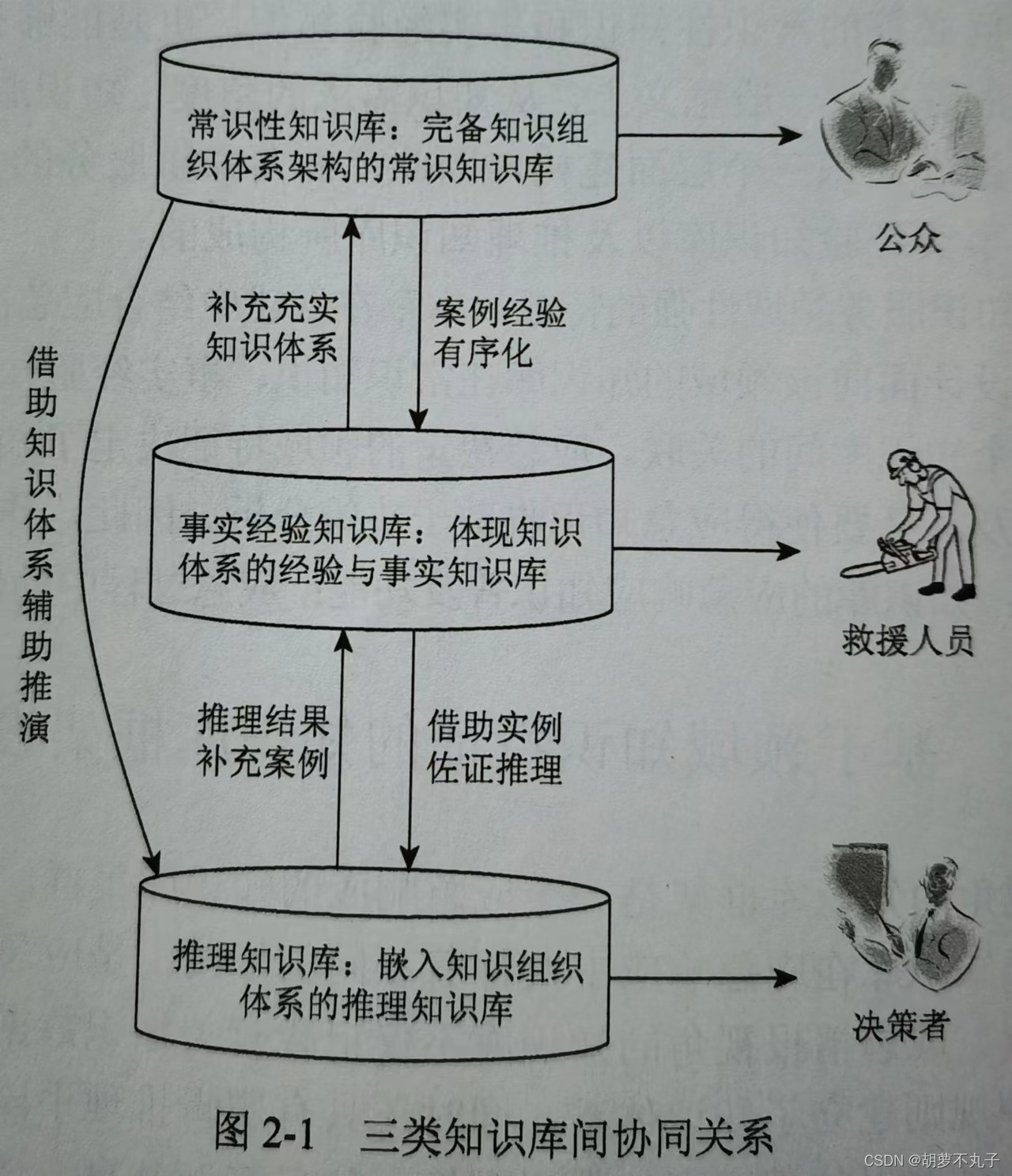
我的思考:用于网络安全场景,公众可以替换为现有安全厂商所建立的安全知识库,统一收集的数据格式,映射到ATT&CK矩阵或其他安全知识框架中(映射的内容包含检测到的攻击和反制方法)。其中图中的有序化,我认为可理解为知识如何有序,一条条的连在一起,构成攻击路径或防御路径,救援人员可以看作针对网络靶场中仿真的攻防场景构建的知识库,两者互为验证和补充,另外,决策者作为使用方,对正在进行的攻防环境进行评估,不仅用到常识性知识图谱进行推理,而且和真实已发生的攻防事实一道构建知识库,通过嵌入进行推理,预判未知的将要发生的攻击,来决策防御如何进行。同样,我们可以构建这三个知识库协同使用。
二、常识知识库的构建
整体架构:
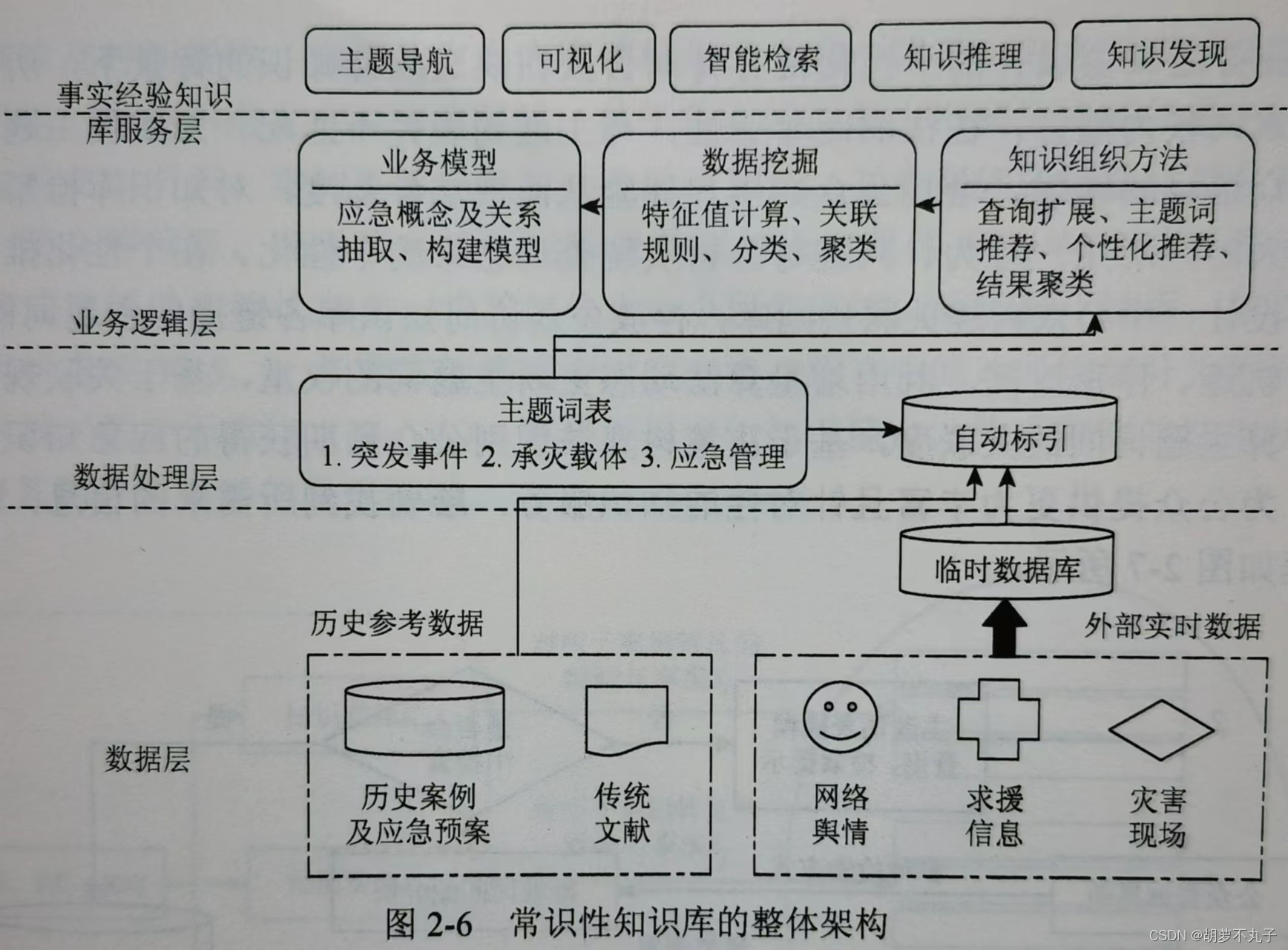
其中书上提到的分解步骤:
① 构建应急响应特征词典(需要分类,分级和分期)【我的理解:特征词典通过历史参考数据和外部实时传过来的数据一起构建】
② 对领域的每个知识(主题词)的刻画描述为三元组【概念(描述事物的概念和属性名),属性(对应属性的状态集),关系(状态之间的相互作用关系)】(专家完成),构成主题词表【我的理解:特征词典索引后映射到主题词表,从而到达业务逻辑层,最终实现常识的查找和服务】
③ 这样就构建出一个主库两个辅库(主题词表和知识分类表)的常识性知识库
分类:
每个特征词被赋予唯一编码,编码是对特征词在分类词表中所处的概念层级结构的直观反应。

分类词表构建过程为利用现有突发事件分类体系中的分类概念,以及从相关部门文件 中抽取的突发事件分类概念, 并结合专家意见,再以具体的突发事件情景中抽取的分类词汇为补充,从而得到完整的分类概念集合并设计规则进行编码,最终生成完善的分类表。
分级:
并非分类表中的每一个分类概念都需要设置分级标准,只有在应急处置措施上具有区分度,能代表一类案例的通用处置需求的分类概念,才需要设置分级标准。
例如,“乙类传染病”虽然是分类表中的一个分类概念,但是包含了众多的下级类目,不同的“乙类传染病”子类具有不同的应急处置需求,因此“乙类传染病”作为一个分类概念,不具有应急处置措施上的区分度,不能根据“乙类传染病”类目的处置措施得到具体的关于“乙类传染病”的通用的处置措施,所以从分类表编制目的出发,该类目不需要设置相应的分级标准。
我的思考:非必要不分级,虽然乙类传染病的子类目属于乙类传染病,但是在应急处理上子类目和乙类这个大类不同,不属于蕴含关系,所以级别不一样,不能统一按大类设置。
分期:
在具体的应急响应中某一分类对应着一定的分级,并且在具体的分级下,还随着应急决策所处的不同阶段,属于事件演化的不同发展时期,简称分期。根据突发事件的生命周期理论以及突发事件阶段划分研究的探讨,本书将突发事件的分期界定为一期(事发前)、二期(事发初期至高潮)、三期(事件高潮至回落)、四期(事件尾声),这一分期可与图 2-1中的应急响应过程相对应。
一期(事发前):突发事件已经开始出现,或者出现了苗头,导致突发事件发生的因素显现。
二期(事发初期至高潮):突发事件大量出现,影响范围或者造成的损失快速扩大。
三期(事件高潮至回落):突发事件造成的损失或影响范围开始减小,或者突发事件造成的损失或影响范围增长的速度开始减缓。
四期(事件尾声):突发事件基本得到控制,造成的损失或者影响范围不再扩大,突发事件趋于结束。
具体的突发事件分期划分时,结合事件自身的描述特征,适当调整分期标准描述文本,以便和事件相适应。
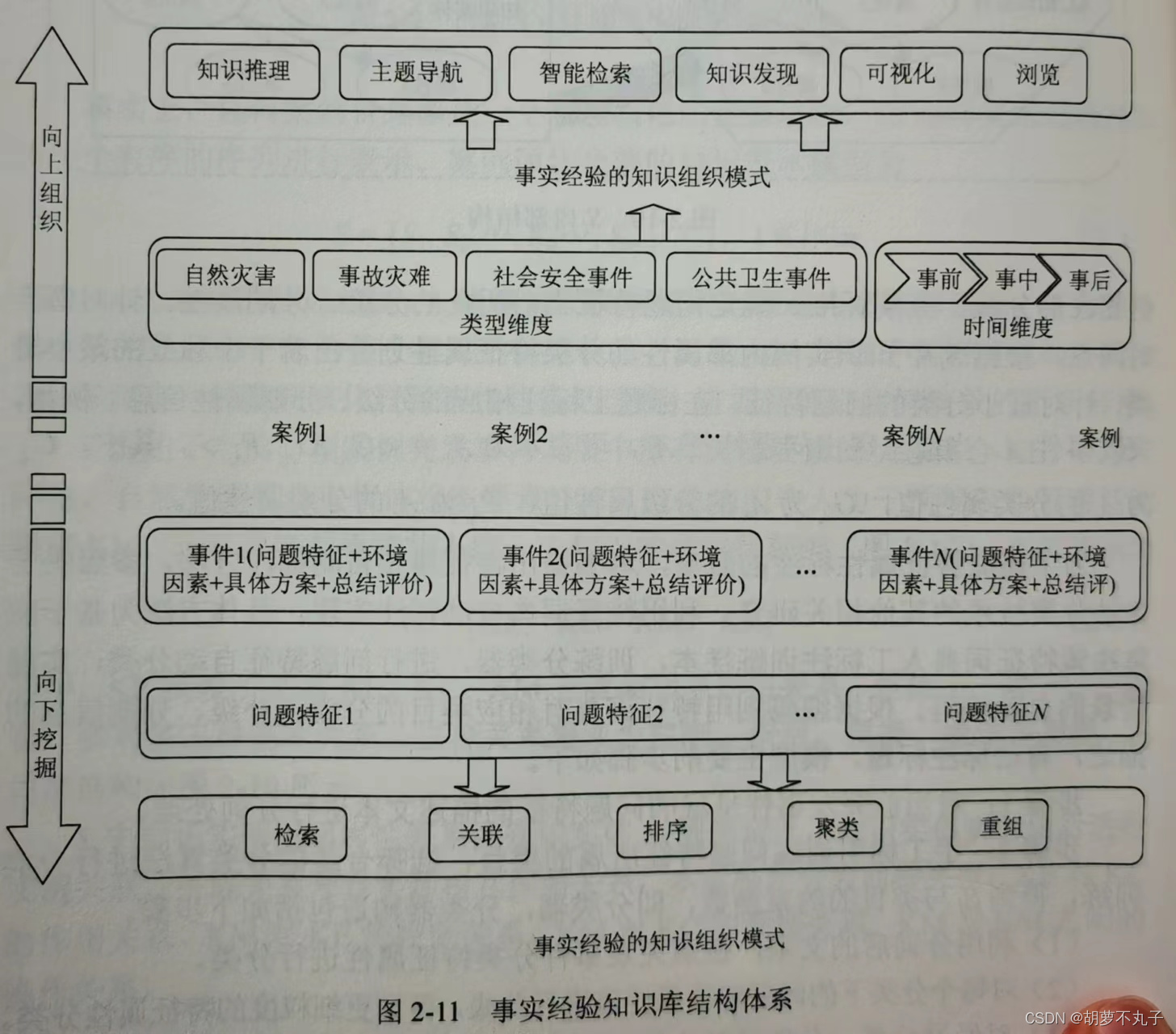
三、事实经验知识库的构建
结构体系:
四、推理知识库的构建
整体架构:
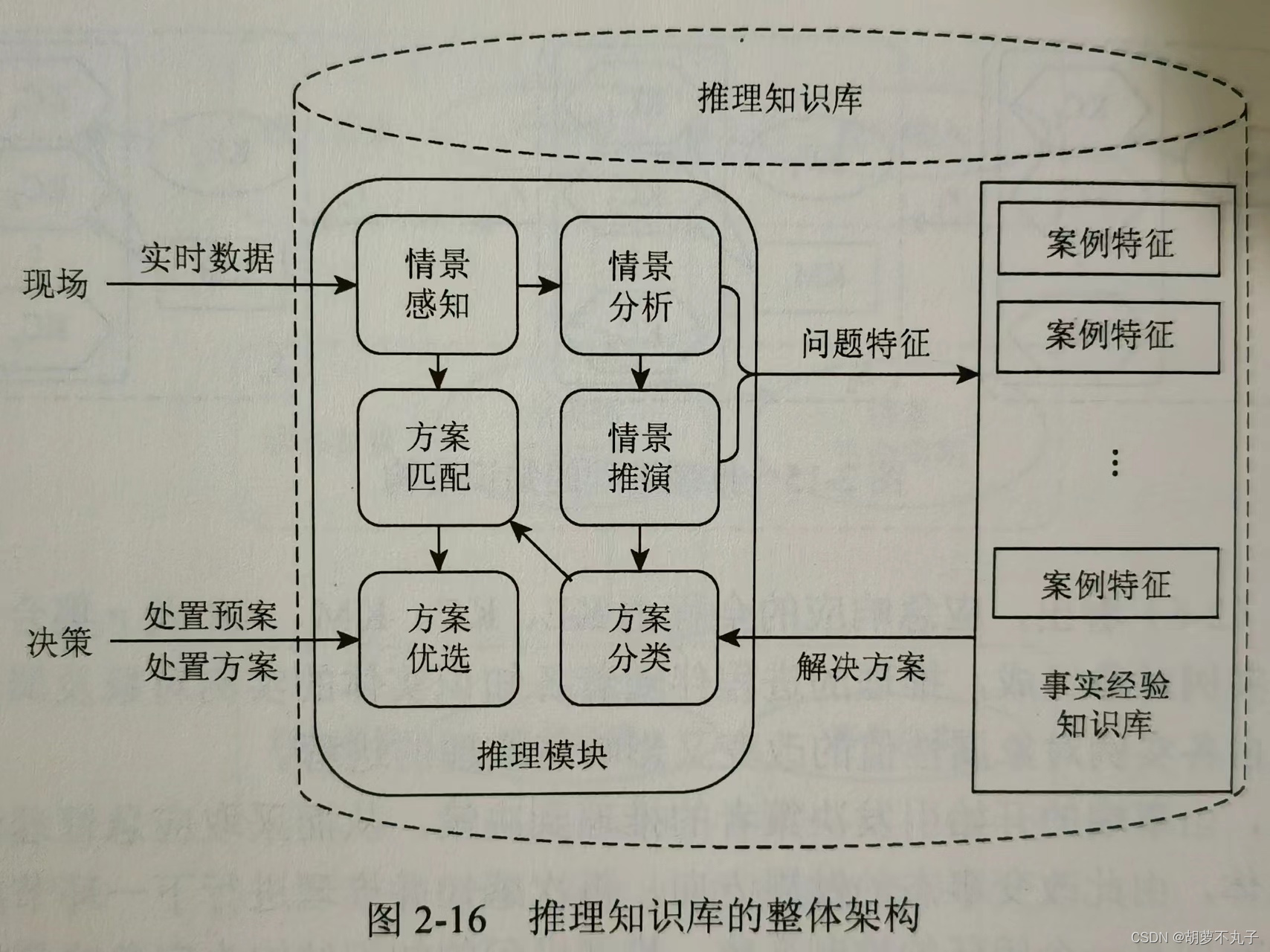
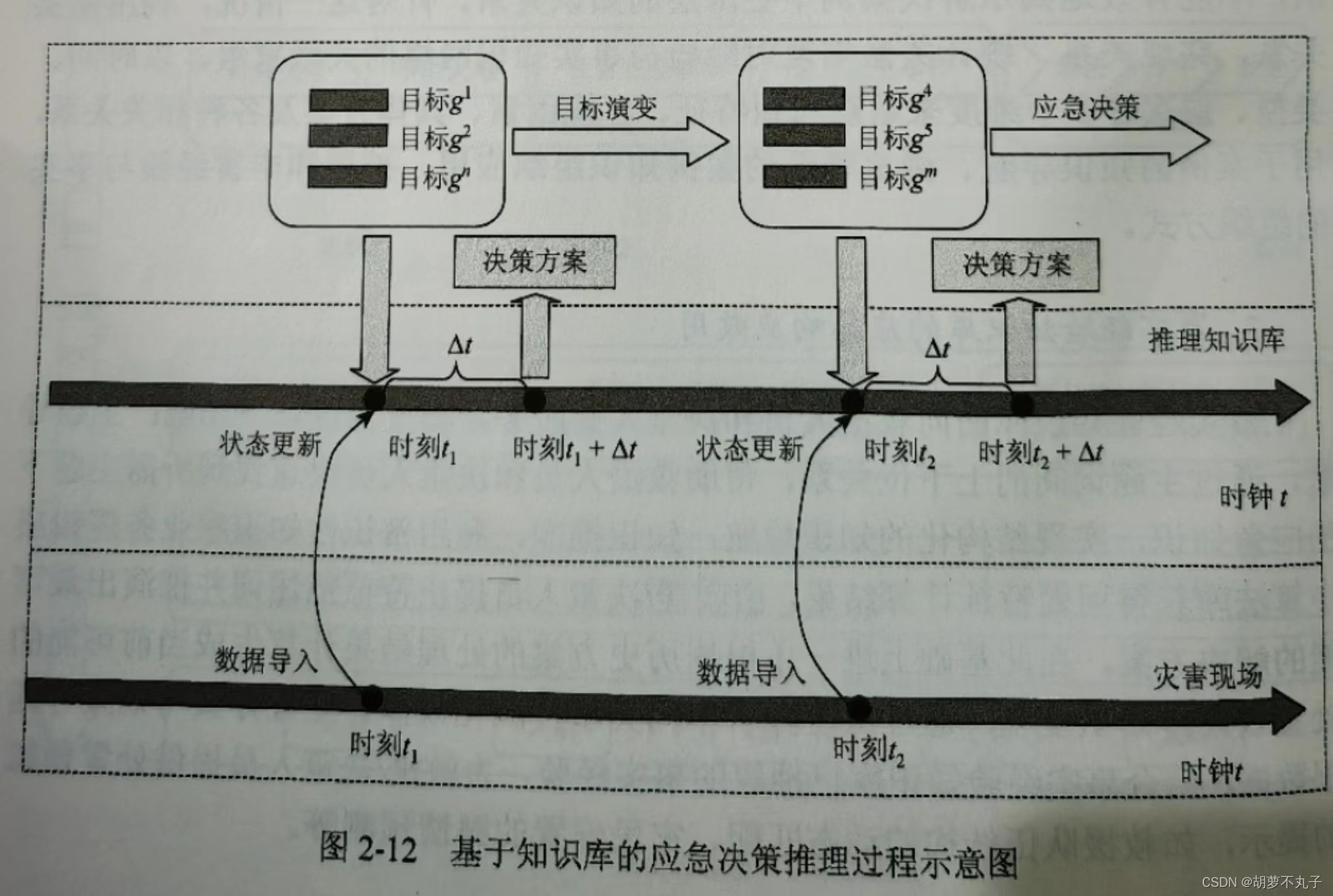
其中应急决策推理过程示意图如下:
在决策触发阶段,决策者通过观测实际灾害现场,评估当前知识库呈现态势分析,若当前实施异常及态势突变,则重新触发决策分析机制,调整决策目标及策略;
在决策优化阶段,利用经验事实知识库预测未来 t+Δt 的状态,与当前 t 的状态进行对比,分析策略优势。
下图是基于知识库的应急决策推理过程示意图。推理知识库是决策分析与现实世界动态交互的桥梁,使得决策建立在实时信息的基础上,系统内部及环境外部的不确定性、异常和突变行为都能实时反映到决策中。推理知识库不仅避免了连续优化引起的决策效率低下,且实现了对灾害现场的实时监控和干预。
附录
一、知识库中的数据清洗面临的问题
目前针对知识库中数据清洗的研究不多,就现有的研究工作中可以看出面临的问题:
①知识库中很多非清洁的数据是很难被彻底清洗干净的
②对非清洁数据的清洗可能造成部分知识的丢失或失真
③知识库中信息更新频繁,要同步执行非清洁数据的辨识与清洗将极大影响知识库系统的效率
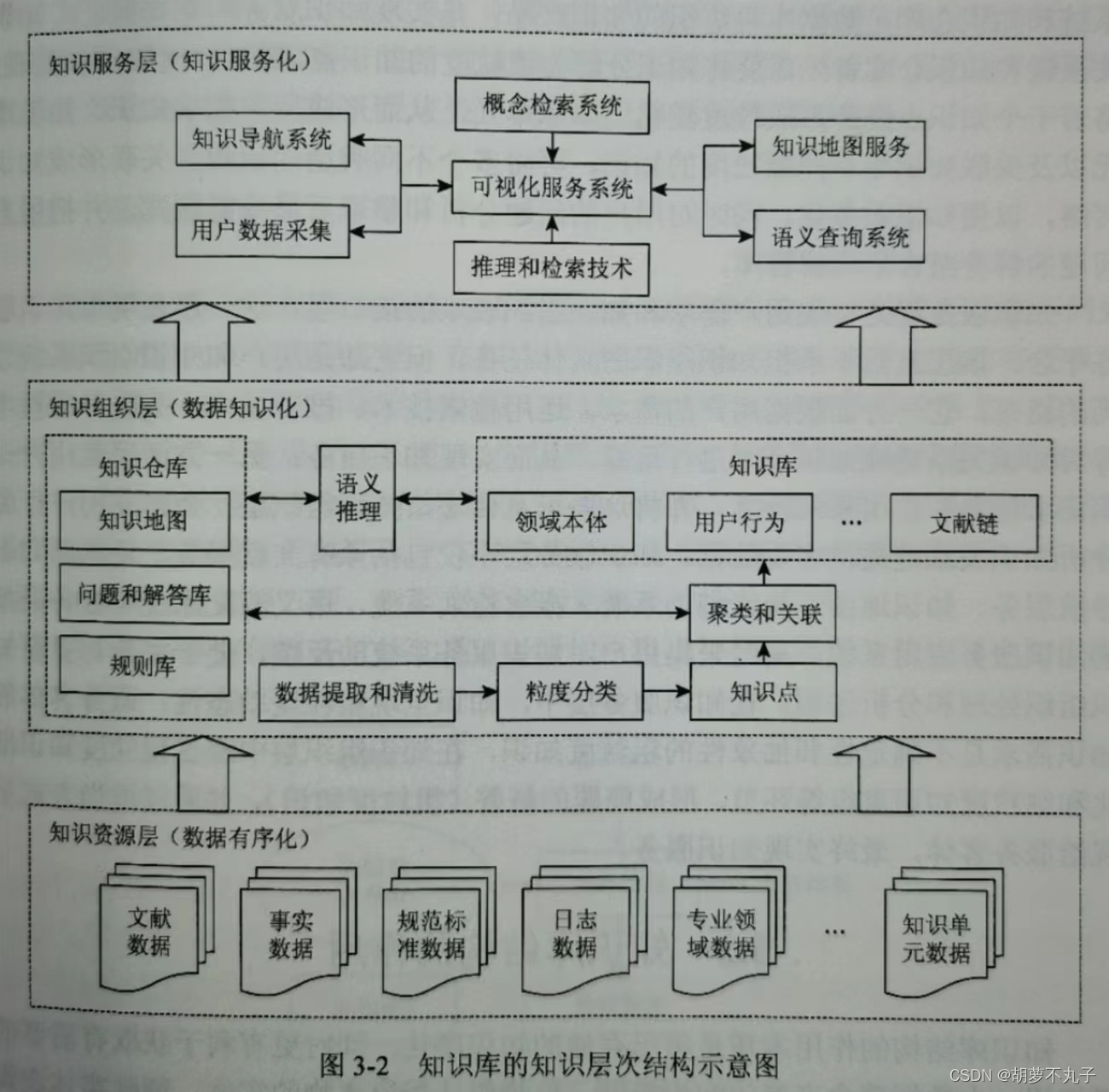
二、知识库的知识层次结构示意图
三、知识库的知识对齐、知识更新和知识发现
① 知识对齐
知识库作用之一是高效地实现知识序化。知识服务中各类需求驱动着不同知识集结组合解决具体服务实际,在组合中有些不同命名的知识可能指向客观世界的同一实体刻画,有些知识名称相同(相似)而实际刻画着不同的语义,实现知识序化的一般方式是进行实体对齐。知识库的实体对齐是知识库结构研究的热点,其目标是高质量链接多个现有知识库,是知识库群工作的基础,也是协同知识服务的前提。
实体对齐是判断两个实体是否指向真实世界同一对象的过程,这一过程是数据清洗的关键方面,对数据挖掘和数据集成至关重要。

② 知识更新
知识在知识库中是“流动”的,我们要将正确的知识更新扩充到知识库中。知识更新的一般方法是进行知识库的实体扩充。实体扩充的目标是从网络大数据的文本中获取的实体动态扩展到知识库中,从文本中获取的实体与知识库中的实体存在两种关系:
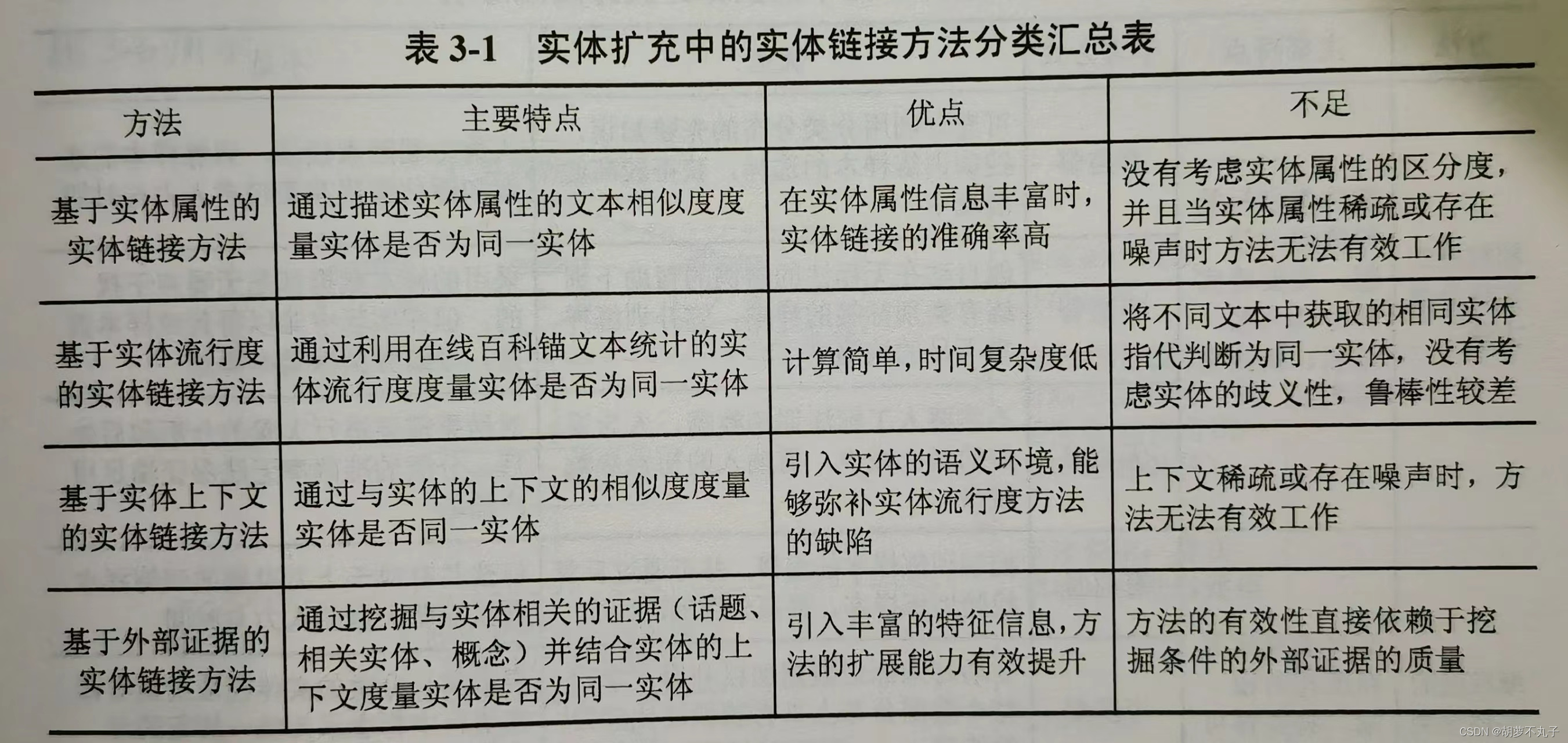
一是知识库中存在与文本实体映射的实体,对此类实体只需要找到文本实体在知识库中的映射实体,即实体链接。
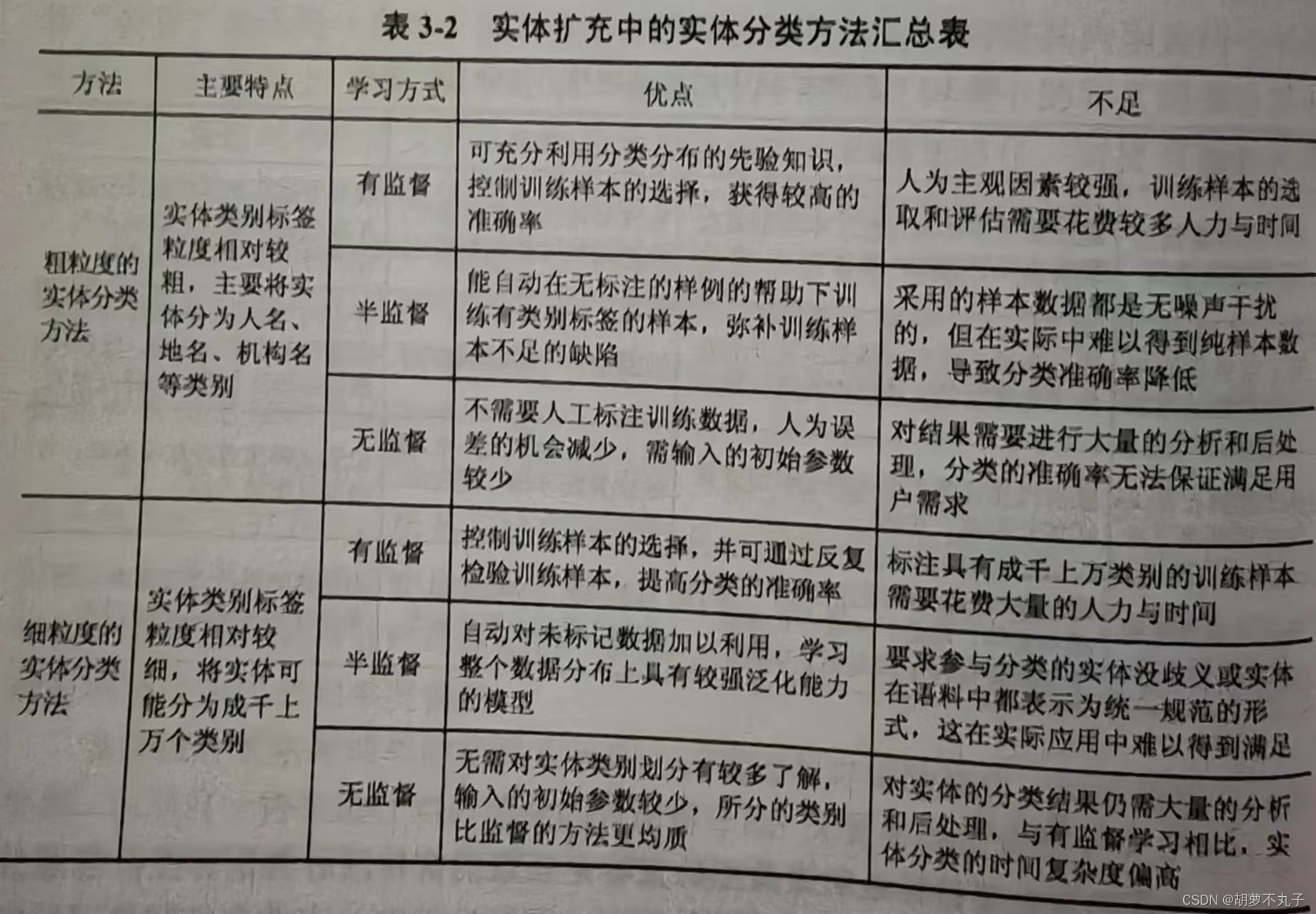
二是知识库中不存在于文本实体映射的实体,首先基于知识库中分类为文本实体标注类别,即实体分类(entityclassification),然后根据分类将文本实体扩展到知识库对应的分类下。

③ 知识发现
