0. 知识补充:
有穷自动机(Finite Automata):一个有穷自动机有一个有限的状态集合以及状态之间的跳转,其中每个跳转至少有一个标签(label)。
最基本的FA是有限状态接收机(finite state acceptor/FSA),输入一个输入符号序列,FSA返回“接受”/“不接受”。其判断条件为:是否存在一条从初始状态到终止状态的路径,使得路径上的标签序列正好等于输入符号序列,如果是则返回“接受”,否则返回“不接受”。
下图为一个FSA的例子:
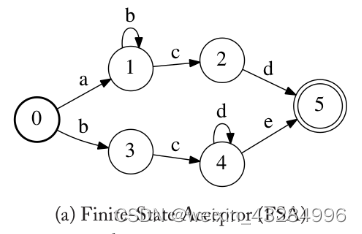
图中的节点代表状态,节点间的连线代表状态之间的跳转,连线上的字母为每个跳转的标签(label),加粗的圆圈表示初始状态,两个圆圈表示终止状态。
当输入序列为“abbcd”时,这个FSA返回接受,因为存在开始状态 0 到终止状态 5 的一条路径“011125”,使得路径上的标签序列正好等于输入符号序列。当输入序列为“abccd”时,则返回“不接受”,因为不存在满足条件的路径。
上述FSA匹配的所有字符串用正则表达式表示为:ab*cd | bcd*e
FSA有几种扩展,即有限状态转录机(Finite-State Transducer/FST)、加权有限状态接收机(Weighted Finite-State Acceptor/WFSA)、加权有限状态转录机(Weighted Finite-State Transducer/WFST)。其继承了FSA的基本特性,但是他们的输出不再局限于“接受”/“不接受”。
有限状态转录机(Finite-State Transducer/FST):其每个边上是一个pair<输入标签:输出标签>,如下图所示:
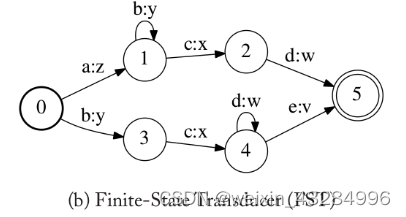
其中每个边的 pair 用“输入:输出”表示。
其描述了把一个接受的输入序列转换为另一个输出序列的转换规则。例如,输入序列为“abcd”时,输出序列为“zyxw”。
加权有限状态接收机(Weighted Finite-State Acceptor/WFSA):其每个边上增加了一个权重weight,此外初始状态和终止状态也有对应的初始weight和终止weight。其中weight通常表示状态跳转的概率或者代价,一条路径中的weight通过“乘法”累计,不同路径的weight通过“加法”累计。从而输出接受的不同路径的度量。WFSA如下图所示:
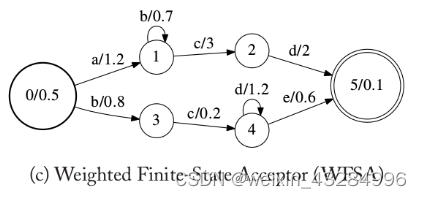
当输入状态为“abcd”时,输出为:0.5*1.2*0.7*3*2*0.1=0.252。
加权有限状态转录机(Weighted Finite-State Transducer/WFST):其每条边上不仅是一个pair<输入标签:输出标签>,还有对应的权重,此外初始状态和终止状态也有对应的初始weight和终止weight。WFST如下图所示:
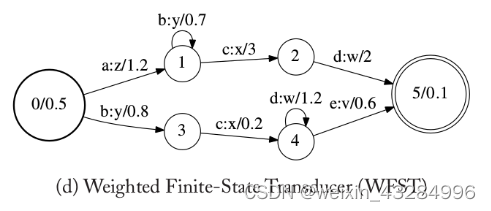
当输入序列为“abcd”时,输出为“zyxw / 0.252”。
半环(Semiring):半环类似于环,这是一种代数结构,这里用来定义WFST的加权值,一个半环定义为。其中 K 是一个集合;
是在 K 上的“加法”和“乘法”;
分别表示零元和幺元。一下是一些半环举例:
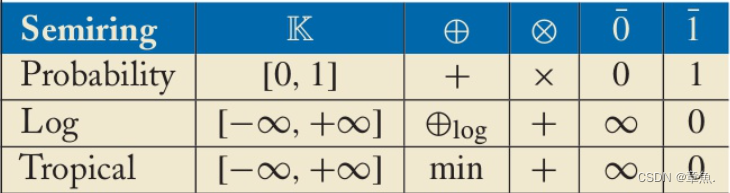
这样定义的好处是可以使WFST相关操作的表达式统一。例如当权重是概率时,路径总权重一般为相乘;当权重是损失时,路径总权重一般是相加 。分开定义会很冗杂,引入半环定义后,可以统一公式,在权重代表不同的意义时,即其在不同的半环集合中时,使用其对应的“加法”、“乘法”、零元和幺元即可。
1. 加权有限状态转录机(Weighted Finite-State Transducer/WFST)
WFST(Weight finite state transducer),带权有限状态转录器,可以用一个八元组进行表示:

在语音识别解码器中,他包含了H、C、L、G这四个网络,通过一定的操作,形成了解码网络N。

一般网络构建流程如下:
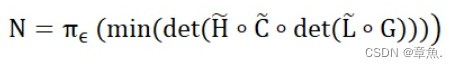
只要复合的WFST构建完毕,解码器的工作就是对于给定的语音输入搜索最优的路径。如果模型没有发生变化,则WFST不需要更新(静态解码网络)。
1.1 四个网络
1)声学模型(H)
在基于WFST的方法里,一个声学模型可以被看成一个转换机(transducer),其将输入的语音信号转化为一个上下文相关的phone(音子,音素)序列(HMM模型)。
一个典型的声学模型:
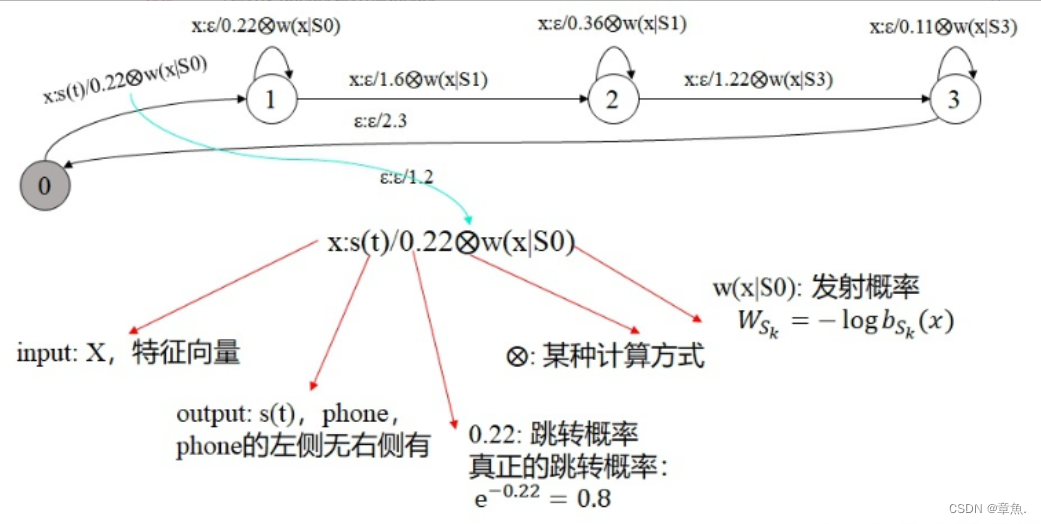
其中 :
s(t) 表示 s 右边有 phone t , 左边没有 phone
(s)s 表示左边有 phone s ,右边没有 phone
(s)s(t) 表示左边有 phone s ,右边没有 phone t
2)跨词三音子模型(H)
声学模型的输出是上下文相关的因子序列。但是,L要求的输入是上下文无关的因子序列。所以需要C来把上下文相关的因子序列转换成上下文无关的。
3)发音词典(L)
对于每一个词,根据发音词典输入是一个(或者多个)子词单元的phone的序列,而输出是这个词。
以START、STOP、IT这几个词为例:

4)语言模型(G)
有限状态文法Finite State Grammar (FSG)和n-gram模型是在语音识别里被广泛使用的语言模型。
一个经典的FSG:
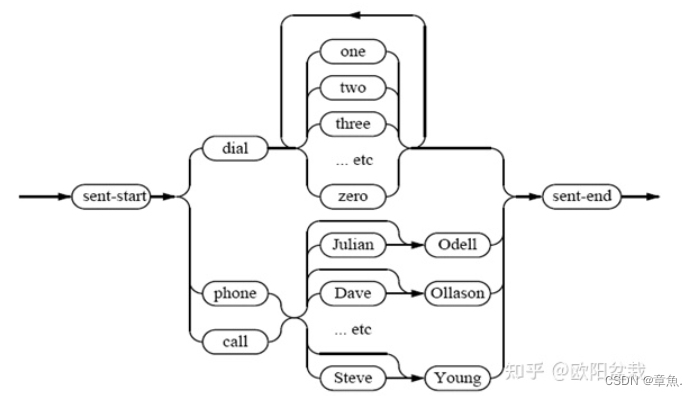
(有关n-gram:N-gram语言模型_章魚.的博客-CSDN博客)
1.2 四个操作:
WFST常用的四个操作为:组合(Composition)、确定化(Determinization)、转移消除(-removal)、最小化(Minimization)(最小化前需要进行 权重规整(Weight-Pushing))。
1)组合(Composition)
组合就是用来把两个不同层级的WFST“整合”成一个WFST。用一个串联的WFST模型序列生成单一的WFST,使得新WFST的输入输出关系与原WFST序列相同。
前提:串联。前一个WFST的输出属于后一个WFST的输入
算法公式如下:

基于Probability SR,其中“乘法”为 ×, “加法”为 +。(WFST中路径权值为概率等,即计算一条路径总权值 = 权值相乘时,常采用Probability SR)
举例组合如下两个 WFST :

组合结果如下:
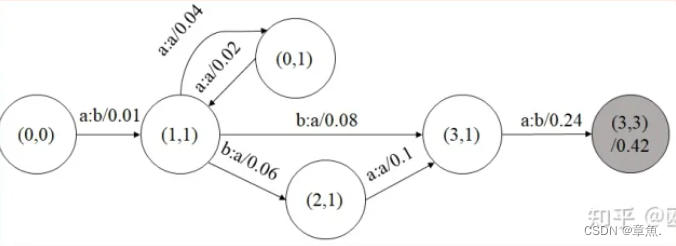
其中代表 A 的第 a 个节点和 B 的第 b 个节点。
2)确定化(Determinization)
如果从一个状态遇到一个字母会有两条及其以上的边,那么它就是非确定的。
确定化的算法就是把一个非确定的WFST转换成等价的确定的WFST的算法,确定化后,网络将变为唯一输入和唯一输出。(与FSA相同)
举例非确定 WFSA 如下:
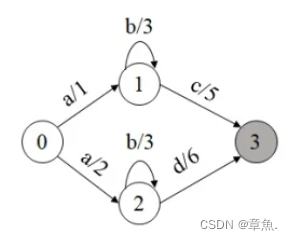
计算基于Tropical SR,“乘法”为 +;“加法”为 min;头结点的权重默认初始化为。(WFST中路径为损失等,即计算一条路径总权值 = 权值相加时,常采用Tropical SR)
对于 0 节点,下一状态为 1,2。计算新弧的权值如下:
其中 W(0)代表状态节点的权值,W(0-1)代表从 0 到 1 的转移弧上的权值。
即:
则状态1,2剩余权值计算如下:
即 剩余权重 = 上一状态权重 + 转移权重 - 已经有的转移权重:
同理可得:
则确定化第一次的WFST如下:
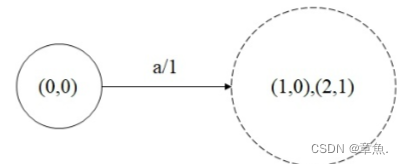
图中代表状态 i, 权重为 j。
此后将状态1,2当做一个状态,继续进行确定化操作,依次类推,即可得到如下确定化WFST:
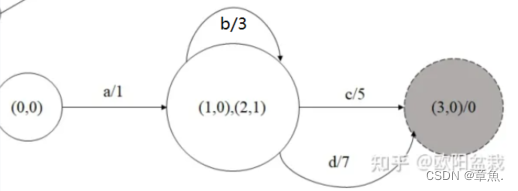
去除计算量得新的WFST为:
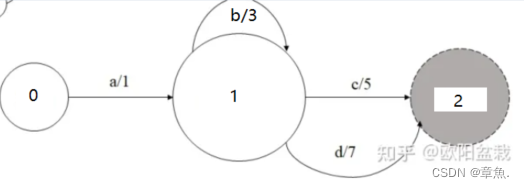
可以举例计算,其路径权值与原网络相同。
3.1)权重规整(Weight-Pushing)
语音识别问题可以转化为搜索最优路径。在构图时清除掉“绝路”能够有效缩短搜索时间。而且权重调整是最小化操作的必要条件,变换前后路径上的总权重相等。
思想是重分配WFST上的权重,使得权重尽可能提前。即把一个WFST所有路径的weight分布往初始状态push,但是不改变任何成功路径的weight。
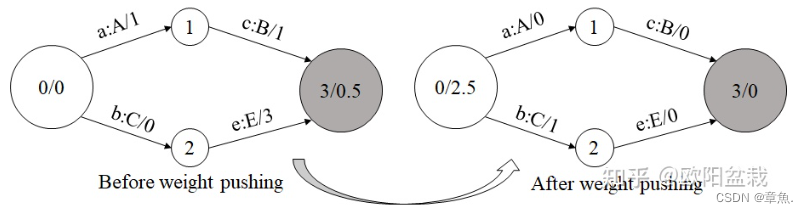
举例 WFST 如下:

计算基于Tropical SR,“乘法”为 +;“加法”为 min;
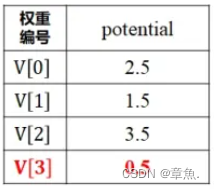
1)首先计算各个节点相对于终止节点的“势”,如果有多条路径取最小值。
对于 0 状态点:
其中:
同理得:
故:
依次类推计算得其他状态“势”为:
2)调整初始和终止节点的权重。
调整后权重权重:
此处 V(0) 可以看做两部分,一部分为路径到达终止状态时“乘”上的权重(0.5),另一部分为所有从初始状态到结束状态路径中,最小的转移弧权值“乘积”,即其他任何路径的转移弧权值“乘积”都大于这一部分(2.0),方便讲解,暂将这一部分叫做最大公共“势”。
故可以将这两部分的权值提前。将最末尾“乘”上的权重提前到初始状态;每条路径都会有的转移弧权值“乘积”也“推”到初始状态。这样后续的路径计算只需要计算路径间的不同即可,减少计算量。
对于中间节点的权重,可以将其看做其所在子网络中的初始节点,即:
3)从起始状态依次调整转移弧权重
对于所有状态节点,有:
等式右边为以终止节点为 0 参照时,i 节点经过 j 节点的最大公共“势”;左边 为 i 节点已经有的势,Weight-Pushing要尽可能的把权重提前,故将剩余最大公共“势”全部赋值给最接近的这一条转移弧。
那么:
即:
依次计算得最后的网络为:
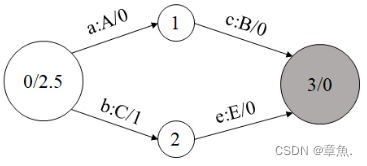
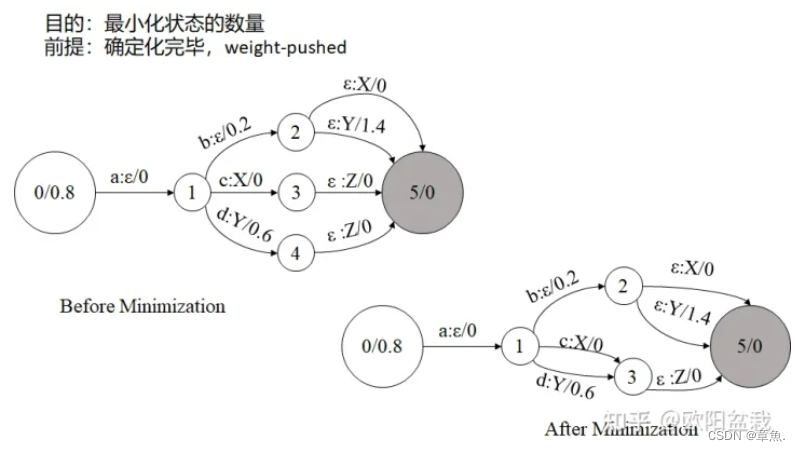
3.2)最小化(Minimization)
最小化之前首先要保证网络已经确定化完毕,且经过权重规整(Weight-Pushing)。
最小化的目的是最小化状态的数量。
对于网络中 P 和 Q两个状态节点,如果从这两个节点出发到终止状态的所有路径上的所有字元和权重全部相同,则称 P 和 Q 等价,可以将他们合并成一个状态节点。。
4) 转移消除(-removal)
转移消除(ε-removal)的作用,主要是去空弧,在WFST网络之中,ε是一个特殊的(输入和输出)符号,它代表空,没有输入/输出。输入符号为ε的跳转叫做ε-跳转,这个状态的跳转不需要任何输入符号就可以进行。
前期优化过程中留下、生成或引入空弧标记(例如组合声学模型(H)时,会引入大量空弧),最后进行去空弧操作减少整体复杂度。
以如下 WFSA 为例:
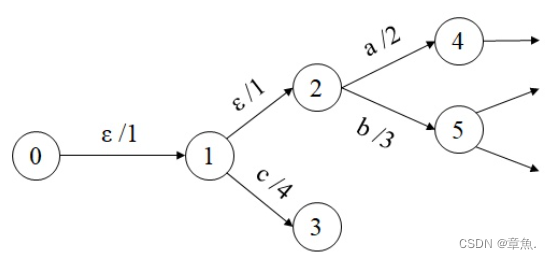
计算基于Tropical SR,“乘法”为 +;“加法”为 min;
要想消除空弧,即将空弧连接的节点看为一个节点,空弧连接路径最开始的节点为合并后的初始节点。
对于含有空弧的路径0-1-2-4:
对其他含空弧路径进行合并得到新的网络:

2.总结
WFST(Weight finite state transducer),带权有限状态转录器。
语音识别中,通过合理安排四个个操作( 组合(Composition)、确定化(Determinization)、转移消除(-removal)、最小化(Minimization))的顺序,将四个网络(声学模型(H)、跨词三音子模型(C)、发音词典(L)、语言模型(G))组合成高效的静态解码空间。