Redis也是对外服务,所以Google四个黄金指标同样适用,还从延迟、流量、错误、饱和度分析Redis关键指标。
1 延迟
选择Redis是想得到更快响应速度和更高吞吐量,所以延迟数据对使用Redis的应用程序至关重要。
1.1 如何监控延迟
① 客户端应用程序埋点
Java程序调用Redis时,计算各命令花费多久,然后把耗时数据推给监控系统。
灵活,想按什么维度统计就按啥
缺点:代码侵入性,和客户端埋点监控MySQL的原理一样。
② redis-cli的–latency
客户端连上 redis-server,然后不断发 ping 命令,统计耗时。我在远端机器对某 redis-server 做探测,看探测结果:
javaedge@JavaEdgedeMac-mini ~ % redis-cli --latency -h x.x.x.x -p 6379
min: 5, max: 187, avg: 8.19 (469 samples)^C
javaedge@JavaEdgedeMac-mini ~ %
跑到 localhost 机器对本机的 redis-server 做探测:
javaedge@JavaEdgedeMac-mini ~ % redis-cli --latency -h localhost -p 6379
min: 0, max: 12, avg: 0.23 (1505 samples)^C
javaedge@JavaEdgedeMac-mini ~ %
远端机器平均延迟是 8.19 ms,本地探测平均延迟是 0.23 ms,相差巨大,时间主要花在网络 I/O,Redis本身执行效率是很高的。
只使用 ping 对 redis-server 探测,怎能反映真实工作负载?
是不是ping命令执行很快,而应用发起的真实请求其实很慢?
Redis 是单线程顺序执行,若某请求执行得慢,其他所有客户端都得等,所以 ping 对 redis-server 探测,理论上探测结果就能反映 redis-server 真实情况。
若发现Redis变慢,咋找那些执行慢的命令?
slowlog,先定义执行时间超过多久算慢,Redis默认配置10ms,比如调成5ms。
javaedge@JavaEdgedeMac-mini redis % grep slower redis.conf
# In many cases the disk is slower than the network, and storing and loading
slowlog-log-slower-than 10000
javaedge@JavaEdgedeMac-mini redis % redis-cli
127.0.0.1:6379> config set slowlog-log-slower-than 5000
OK
127.0.0.1:6379> get slowlog-log-slower-than
(nil)
127.0.0.1:6379> config get slowlog-log-slower-than
1) "slowlog-log-slower-than"
2) "5000"
127.0.0.1:6379> config rewrite
OK
127.0.0.1:6379> quit
javaedge@JavaEdgedeMac-mini redis % grep slower redis.conf
slowlog-log-slower-than 5000
之后一些执行时间超过5ms的命令就会被记录,然后 slowlog get [count] 查看 count 出的slowlog条数。
# 获取 2 条作为示例
127.0.0.1:6379> SLOWLOG get 2
# 序号
1) 1) (integer) 47
# 时间戳
2) (integer) 1668743666
# 执行时间(单位是微秒)
3) (integer) 13168
# 命令及其参数
4) 1) "hset"
2) "/idents/Default"
3) "tt-fc-dev01.nj"
4) "1668743666"
# 客户端IP和端口
5) "127.0.0.1:43172"
6) ""
2) 1) (integer) 46
2) (integer) 1668646906
3) (integer) 13873
4) 1) "hset"
2) "/idents/Default"
3) "10.206.16.3"
4) "1668646906"
5) "127.0.0.1:44612"
6) ""
2 流量
Redis每秒处理多少请求,每秒接收、返回多少字节,在Redis都内置相关指标,通过 redis-cli 连上Redis,执行 info all 。绝大部分监控系统都是从 info 返回内容提取的指标。
javaedge@JavaEdgedeMac-mini ~ % redis-cli -h 127.0.0.1 -p 6379 info all | grep instantaneous
# 每秒执行多少次操作
instantaneous_ops_per_sec:0
# 每秒接收多少 KiB
instantaneous_input_kbps:0.00
# 每秒返回多少 KiB
instantaneous_output_kbps:0.00
instantaneous_input_repl_kbps:0.00
instantaneous_output_repl_kbps:0.00
javaedge@JavaEdgedeMac-mini ~ %
一般一个 Redis 实例每s处理几w个请求都正常。
每s处理的操作如较恒定,则很健康。如发现 ops_per_sec 变少,注意可能:
-
某耗时操作导致命令阻塞
-
客户端出问题,不发请求过来了
若把 Redis 做缓存,还需关注指标:
javaedge@JavaEdgedeMac-mini ~ % redis-cli -h 127.0.0.1 -p 6379 info all | grep keyspace
keyspace_hits:0
keyspace_misses:1
都 Counter 型,即 Redis 实例启动以来统计的所有命中的数量和未命中数量。如统计总体命中率,使用 hits 除以总量。
hit rate = keyspace_hits / (keyspace_hits + keyspace_misses)
近期命中率,如最近10min,通过 PromQL increase 函数做二次运算:
increase(keyspace_hits[10m])
/
(increase(keyspace_hits[10m]) + increase(keyspace_misses[10m]))
命中率低于 0.8 就要注意可能:
- 内存不够用,很多 Key 被清了
- 数据没及时填充或过期了
较低命中率影响应用程序延迟,因为通常当应用程序无法从 Redis 获取缓存数据时,就要穿透到更慢的存储介质取数。
3 错误
Redis响应客户端请求时,只是操作内存,依赖较少,异常概率很小。如客户端操作 Redis 返回错误,大概率网络问题或命令写错。最好做客户端埋点监控,自己发现自己解决。
Redis 对客户端数量限制默认10w,如超过,rejected_connections 指标+1。和MySQL不同,Redis应该很少遇到超过最大连接数(maxclients) 。
4 饱和度
Redis重度使用内存,内存的使用率、碎片率及因为内存不够用而清理的Key数量都需关注。 info memory 查看:
# Memory
used_memory:26276368
used_memory_human:25.06M
used_memory_rss:39575552
used_memory_rss_human:37.74M
used_memory_peak:33979824
used_memory_peak_human:32.41M
...
maxmemory:0
maxmemory_human:0B
...
mem_fragmentation_ratio:1.51
...
used_memory 顾名思义就是使用了多少内存,是从 Redis 自身视角来看的,human后缀表示人类易读方式来展示结果。
used_memory_rss:从os视角看分配多少内存给Redis
used_memory_rss 除以 used_memory 就是内存碎片率(mem_fragmentation_ratio):
used_memory_rss(39575552) / used_memory(26276368) = mem_fragmentation_ratio(1.51)
碎片化率较高说明 used_memory_rss 相对大,used_memory 相对小,即OS给Redis分配很多内存,但Redis利用不好。OS分配内存时因为有分配单位(如8byte、16byte、32byte、64byte)限制,如Redis申请222个字节,os直接分配256个字节,就会产生内存碎片,但这种内存碎片不多,要不然OS会浪费很多内存,所以多给一些内存正常,即 mem_fragmentation_ratio稍大于1没问题。
若执行 Flushdb,会让Redis把数据删掉,而Redis不会立马把这部分内存归还给OS,碎片化率指标就会巨高,此时推荐重启Redis。毕竟,都已Flushdb,说明 Redis 里已无数据。
随应用程序不断删除、修改Redis数据,内存碎片化率也会上升,mem_fragmentation_ratio>1.5,就说明碎片率太高,需重启 Redis或命令Redis清理碎片:
CONFIG SET activedefrag yes
搞得很紧张啊,这大可不必,就像这例,RSS才占37M,Redis实际使用25M,碎片12M,很小啊,虽 mem_fragmentation_ratio已1.51 ,但无需处理。used_memory_peak 32.41M,说明曾经用到过这么多,后来有些 Key 过期或删除/修改,才导致碎片率高点。
何时需处理碎片?
- 机器内存不够用
- 碎片化内存浪费太多
- 且碎片化率很高时
才需处理。调整如下参数控制碎片处理过程。
# 开启自动内存碎片整理(总开关)
activedefrag yes
# 当碎片达到 100mb 时,开启内存碎片整理
active-defrag-ignore-bytes 100mb
# 当碎片超过 10% 时,开启内存碎片整理
active-defrag-threshold-lower 10
# 内存碎片超过 100%,则尽最大努力整理
active-defrag-threshold-upper 100
# 内存自动整理占用资源最小百分比
active-defrag-cycle-min 25
# 内存自动整理占用资源最大百分比
active-defrag-cycle-max 75
上面讨论 mem_fragmentation_ratio 过大case,实际上这值还可能小于1,表示Redis使用了超过RSS数量的内存,说明此时部分内存已被放到交换分区,而磁盘性能相比内存差了约5个数量级,所以出现这种情况严重影响性能。
饱和度的度量还有指标evicted_keys:当内存占用超maxmemory时,Redis清理的Key的数量。内存达maxmemory时的处理策略可配置,默认noeviction。
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
这些指标出问题,上游服务大概率受影响,还有一些指标虽然短期不会影响上游服务,但是如果不及时处理未来也会出现大麻烦,这类指标通常用于衡量Redis内部的一些运行状况,如:
- 持久化相关指标:rdb_changes_since_last_save 自从上次落盘以来又有多少次变更
- 主从相关指标:master_link_down_since_seconds 主从连接已断开的时长
5 采集配置
Categraf 也提供 Redis 采集插件,配置样例在 conf/input.redis/redis.toml:
[[instances]]
# 最核心配置,即Redis的连接地址
# address = "127.0.0.1:6379"
# 认证信息,username 字段低版本的 Redis 是不需要的,6.0以上版本并且启用了ACL的才需要。
# username = ""
# password = ""
# pool_size = 2
# # Optional. Specify redis commands to retrieve values
# 自定义一些命令来获取指标,类似MySQL采集器的queries ,适用于业务指标采集的场景
# commands = [
# {command = ["get", "sample-key1"], metric = "custom_metric_name1"},
# {command = ["get", "sample-key2"], metric = "custom_metric_name2"}
# ]
# 通用配置,所有的 Categraf 的采集器,都支持在 `[[instances]]` 下面自定义标签
# labels = { instance="n9e-dev-redis" }
个人习惯机器名过滤,便于把 Redis 指标和 Redis 所在机器的指标放到一张大盘。 仪表盘样例:
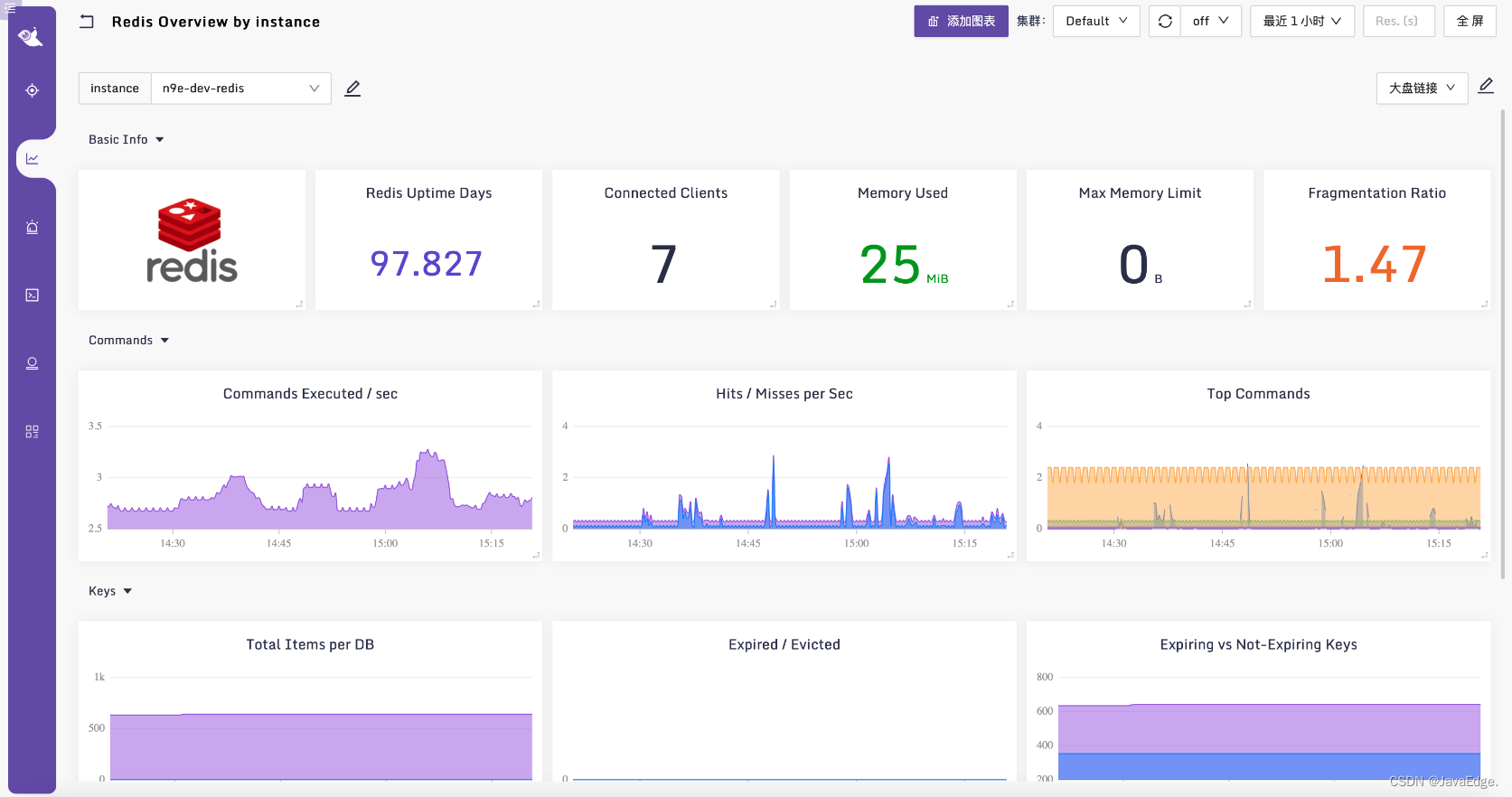
Redis 监控的原理、采集方法、仪表盘相关的知识就讲解完了,下面我们做一个总结。
6 总结
Redis也是对外服务,所以还 Google四个黄金指标的法则来梳理指标。
- 延迟方面使用
redis-cli --latency探测,不过采集器一般不会直接调用这命令行工具,而是采集时先 ping 获取延迟。
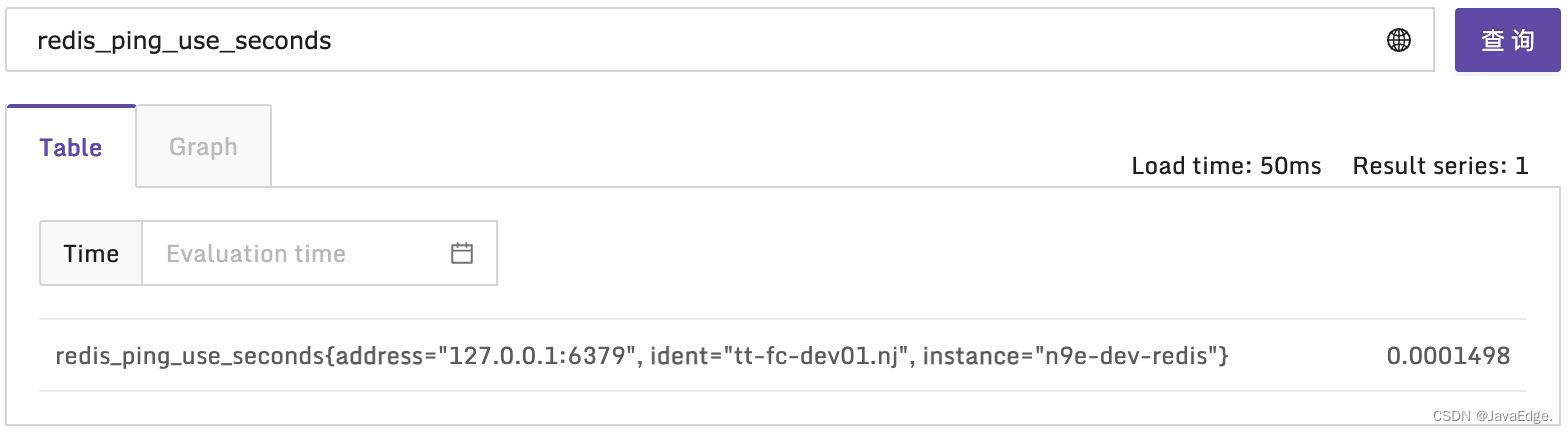
- 流量,关注每s处理多少command,每秒收到多少网络流量,返回多少网络流量
- Redis只是操作内存,基本遇不到错误,可使用客户端埋点采集网络、命令错误
- 饱和度方面,则重点关注内存饱和度,尤其内存碎片率,<1不行,太大也不好

7 FAQ
Redis监控关键指标和告警规则可根据具体业务需求而变化,以下是一些常见的Redis告警规则PromQL表达式:
-
监控Redis内存使用情况:当连续3次采集到的Redis使用的内存超过阈值时,发出告警。
ALARM: expr: REDIS_MEMORY_USAGE > $REDIS_THRESHOLD_FOR_MEMORY_USAGE FOR: 3m ANOMALY_DETECTION_CONFIG: pattern: 7/10 sudden increase lowerBound: 0 upperBound: 2 -
监控Redis连接数:当Redis客户端连接数超过阈值时触发告警。
redisconnectedclients > $REDIS_CLIENTS_MAX_ALERT_VALUE -
监控Redis响应时间:如果Redis响应时间超过设定值,则触发告警。
redis_latency_milliseconds > $REDIS_LATENCY_THRESHOLD_VALUE