前言
Python爬虫很强大,在爬虫里如何自动操控浏览器呢?我们知道在浩瀚的搜素引擎中,有成千上百亿只爬虫,每天往来于互联网之中,那么如此强大的互联网中爬虫是如何识别浏览器的呢,又是如何抓取数据的呢?
概述:
python通过selenium爬取数据是很多突破封锁的有效途径。但在使用selenium中会遇到很多问题,本文就通过一问一答的形式来通熟易懂的普及如何通过selenium执行javascript程序,进而获取动态执行后的网页。如果你喜欢,欢迎转发本文。
【----帮助Python爬虫学习,以下所有学习资料文末免费领!----】

Python爬虫采集数据容易吗 怎么样学好python编程呢
python爬虫编程:用selenium执行javascript出错了,该咋改?
问题:
小明开始学习python爬虫编程了,仿佛整个互联网的数据都快被他纳入囊中了。今天,他又试图完成一个高难度动作,他想让selenium中抓取到以下HTML后,并自动执行js脚本,模仿鼠标自动执行一个点击动作。但令他很失望的是,居然,居然,没用!
Nyaralego , Sikonge , Ab-Titchaz and 11 others like this.
这是他执行的代码。
browser.execute_script(“document.getElement(By.xpath(”//div[@class=‘vbseo_liked’]/a[contains(@onclick, ‘return vbseoui.others_click(this)’)]“).click()”)
它没用,没有反应。究竟做错了什么?
Python大大的答案:
要点回答:
使用selenium查找元素并将其传递execute_script()给单击:
link = browser.find_element_by_xpath(‘//div[@class=“vbseo_liked”]/a[contains(@onclick, “return vbseoui.others_click(this)”)]’) browser.execute_script(‘arguments[0].click();’, link)
如果要从头解决这问题,那么以下就是需要了解它的一系列事情:
- 如何使用JavaScript模拟点击?
这就是我做的东西。这很简单,但它有效:
function eventFire(el, etype){ if (el.fireEvent) { el.fireEvent(‘on’ + etype); } else { var evObj = document.createEvent(‘Events’); evObj.initEvent(etype, true, false); el.dispatchEvent(evObj); } }
用法:
eventFire(document.getElementById(‘mytest1’), ‘click’);
- 如何在Python里进行模拟点击呢?首先制定一个自定义的预期条件,等待元素被“执行”:
class wait_for_text_not_to_end_with(object): def init(self, locator, text): self.locator = locator self.text = text def call(self, driver): try : element_text = EC._find_element(driver, self.locator).text.strip() return not element_text.endswith(self.text) except StaleElementReferenceException: return False
定义完毕后,如何在程序里调用这个类呢?看看以下代码:
from selenium import webdriver from selenium.common.exceptions import StaleElementReferenceException from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC class wait_for_text_not_to_end_with(object): def init(self, locator, text): self.locator = locator self.text = text def call(self, driver): try : element_text = EC._find_element(driver, self.locator).text.strip() return not element_text.endswith(self.text) except StaleElementReferenceException: return False browser = webdriver.PhantomJS() browser.maximize_window() browser.get(“http://www.cnitedu.cn/it/new/20198728.html”) username = browser.find_element_by_id(“navbar_username”) password = browser.find_element_by_name(“vb_login_password_hint”) username.send_keys(“MarioP”) password.send_keys(“codeswitching”) browser.find_element_by_class_name(“loginbutton”).click() wait = WebDriverWait(browser, 30) wait.until(EC.visibility_of_element_located((By.XPATH, ‘//h2[contains(., “Redirecting”)]’))) wait.until(EC.title_contains(‘Kenyan & Tanzanian’)) wait.until(EC.visibility_of_element_located((By.ID, ‘postlist’))) # click “11 others” link link = browser.find_element_by_xpath(‘//div[@class=“vbseo_liked”]/a[contains(@onclick, “return vbseoui.others_click(this)”)]’) link.click() browser.execute_script(“”" function eventFire(el, etype){ if (el.fireEvent) { el.fireEvent(‘on’ + etype); } else { var evObj = document.createEvent(‘Events’); evObj.initEvent(etype, true, false); el.dispatchEvent(evObj); } } eventFire(arguments[0], “click”); “”", link) # wait for the “div” not to end with “11 others link this.” wait.until(wait_for_text_not_to_end_with((By.CLASS_NAME, ‘vbseo_liked’), “11 others like this.”)) print ‘success!!’ browser.close()
看,如何在python里通过selenium来爬取数据就是这么简单。要点掌握好,开始编制自己的爬虫吧。
用爬虫采集数据就是这么简单,如果你对python编程感兴趣,那就好好的学习下吧,用爬虫采集数据一点都不难,对于这个你开始学习了吗?
最后给大家介绍一个完整的python学习路线,内容是从入门到进阶,既有思维导图,也有经典书籍,还有配套视频,给那些想学习python以及数据分析的小伙伴们一点帮助!
python、SQL等工具如何使用都是数据分析过程中需要用到的机巧。以及必备的硬技能!!
一、Python入门
下面这些内容是Python各个应用方向都必备的基础知识,想做爬虫、数据分析或者人工智能,都得先学会他们。任何高大上的东西,都是建立在原始的基础之上。打好基础,未来的路会走得更稳重。
包含:
计算机基础
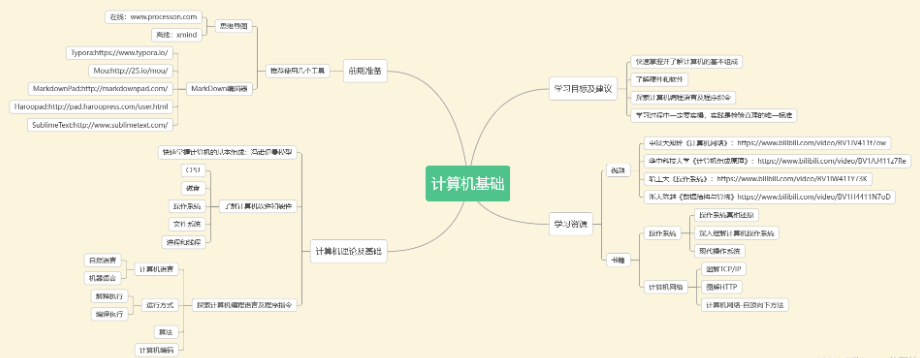
python基础

Python入门视频600集:
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
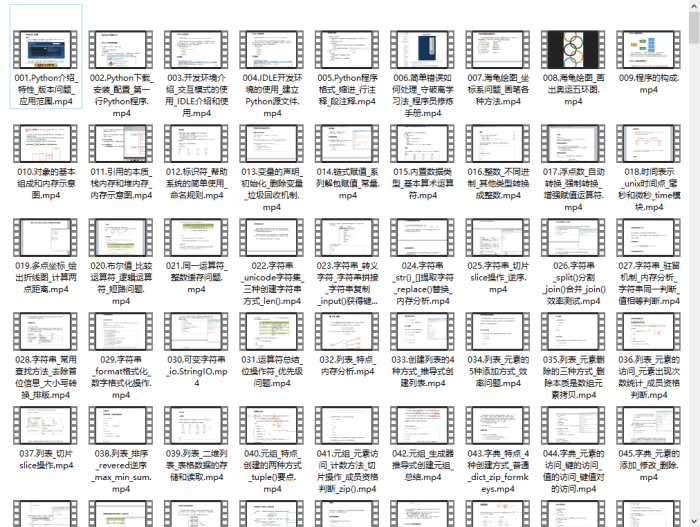
二、Python爬虫
爬虫作为一个热门的方向,不管是在自己兼职还是当成辅助技能提高工作效率,都是很不错的选择。
通过爬虫技术可以将相关的内容收集起来,分析删选后得到我们真正需要的信息。
这个信息收集分析整合的工作,可应用的范畴非常的广泛,无论是生活服务、出行旅行、金融投资、各类制造业的产品市场需求等等,都能够借助爬虫技术获取更精准有效的信息加以利用。

Python爬虫视频资料
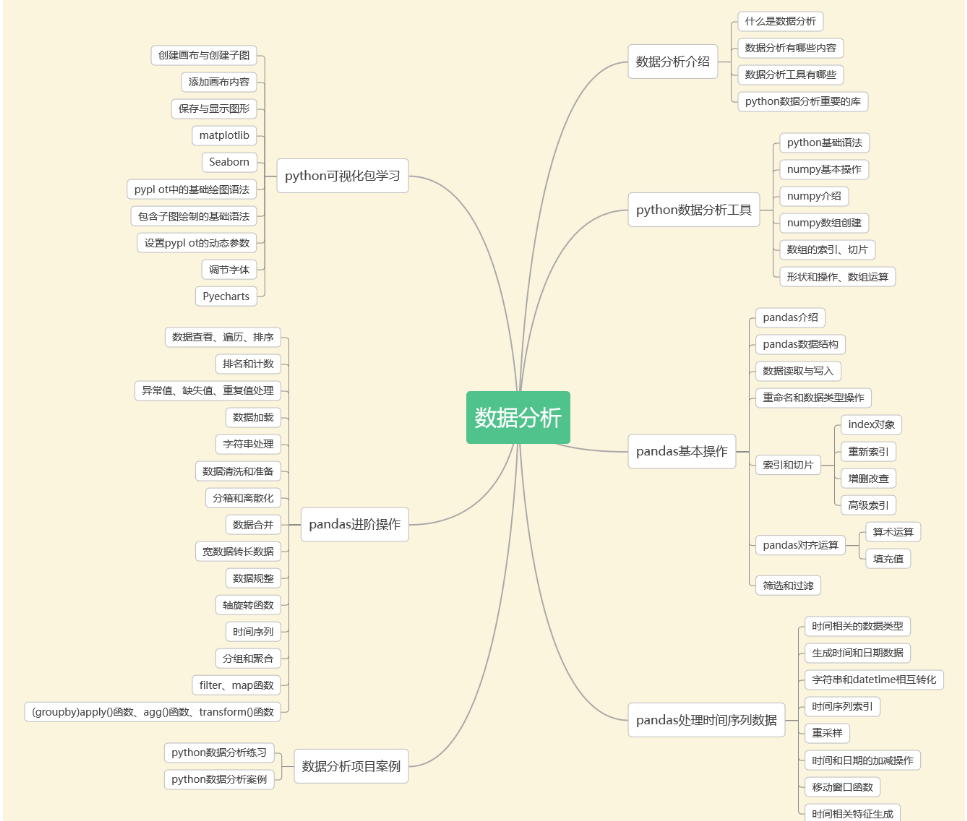
三、数据分析
清华大学经管学院发布的《中国经济的数字化转型:人才与就业》报告显示,2025年,数据分析人才缺口预计将达230万。
这么大的人才缺口,数据分析俨然是一片广阔的蓝海!起薪10K真的是家常便饭。
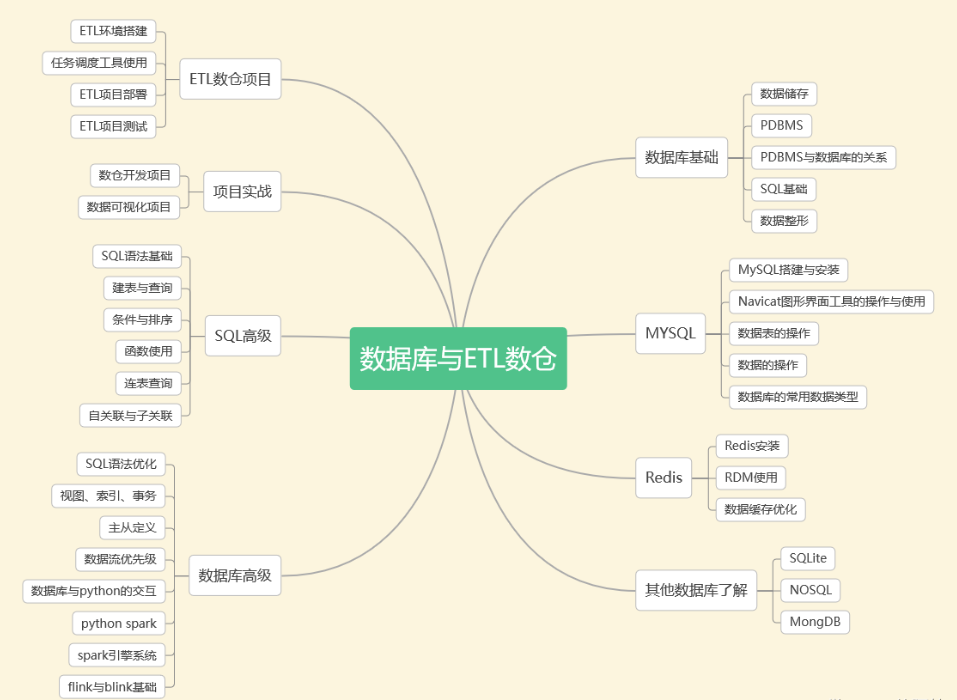
四、数据库与ETL数仓
企业需要定期将冷数据从业务数据库中转移出来存储到一个专门存放历史数据的仓库里面,各部门可以根据自身业务特性对外提供统一的数据服务,这个仓库就是数据仓库。
传统的数据仓库集成处理架构是ETL,利用ETL平台的能力,E=从源数据库抽取数据,L=将数据清洗(不符合规则的数据)、转化(对表按照业务需求进行不同维度、不同颗粒度、不同业务规则计算进行统计),T=将加工好的表以增量、全量、不同时间加载到数据仓库。
五、机器学习
机器学习就是对计算机一部分数据进行学习,然后对另外一些数据进行预测与判断。
机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出决定或预测”。也就是说计算机利用以获取的数据得出某一模型,然后利用此模型进行预测的一种方法,这个过程跟人的学习过程有些类似,比如人获取一定的经验,可以对新问题进行预测。

机器学习资料:
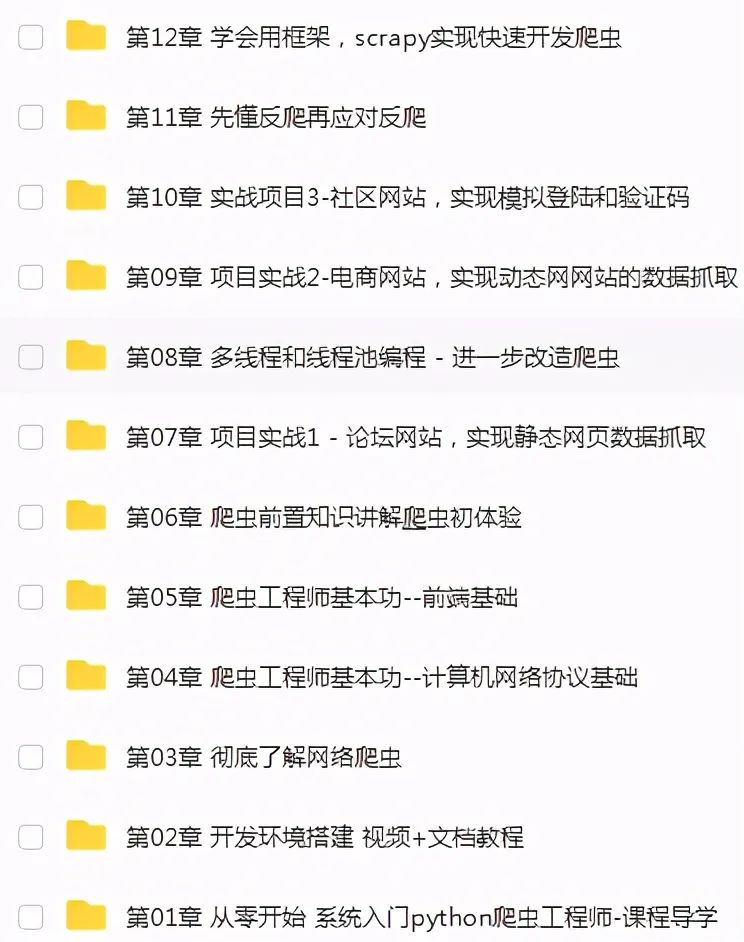
六、Python高级进阶
从基础的语法内容,到非常多深入的进阶知识点,了解编程语言设计,学完这里基本就了解了python入门到进阶的所有的知识点。

到这就基本就可以达到企业的用人要求了,如果大家还不知道去去哪找面试资料和简历模板,我这里也为大家整理了一份,真的可以说是保姆及的系统学习路线了。
但学习编程并不是一蹴而就,而是需要长期的坚持和训练。整理这份学习路线,是希望和大家共同进步,我自己也能去回顾一些技术点。不管是编程新手,还是需要进阶的有一定经验的程序员,我相信都可以从中有所收获。
一蹴而就,而是需要长期的坚持和训练。整理这份学习路线,是希望和大家共同进步,我自己也能去回顾一些技术点。不管是编程新手,还是需要进阶的有一定经验的程序员,我相信都可以从中有所收获。
资料领取
这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以点击下方CSDN官方认证微信卡片免费领取 ↓↓↓【保证100%免费】

好文推荐
了解python的前景:https://blog.csdn.net/SpringJavaMyBatis/article/details/127194835
了解python的兼职副业:https://blog.csdn.net/SpringJavaMyBatis/article/details/127196603