目录

1. YOLO
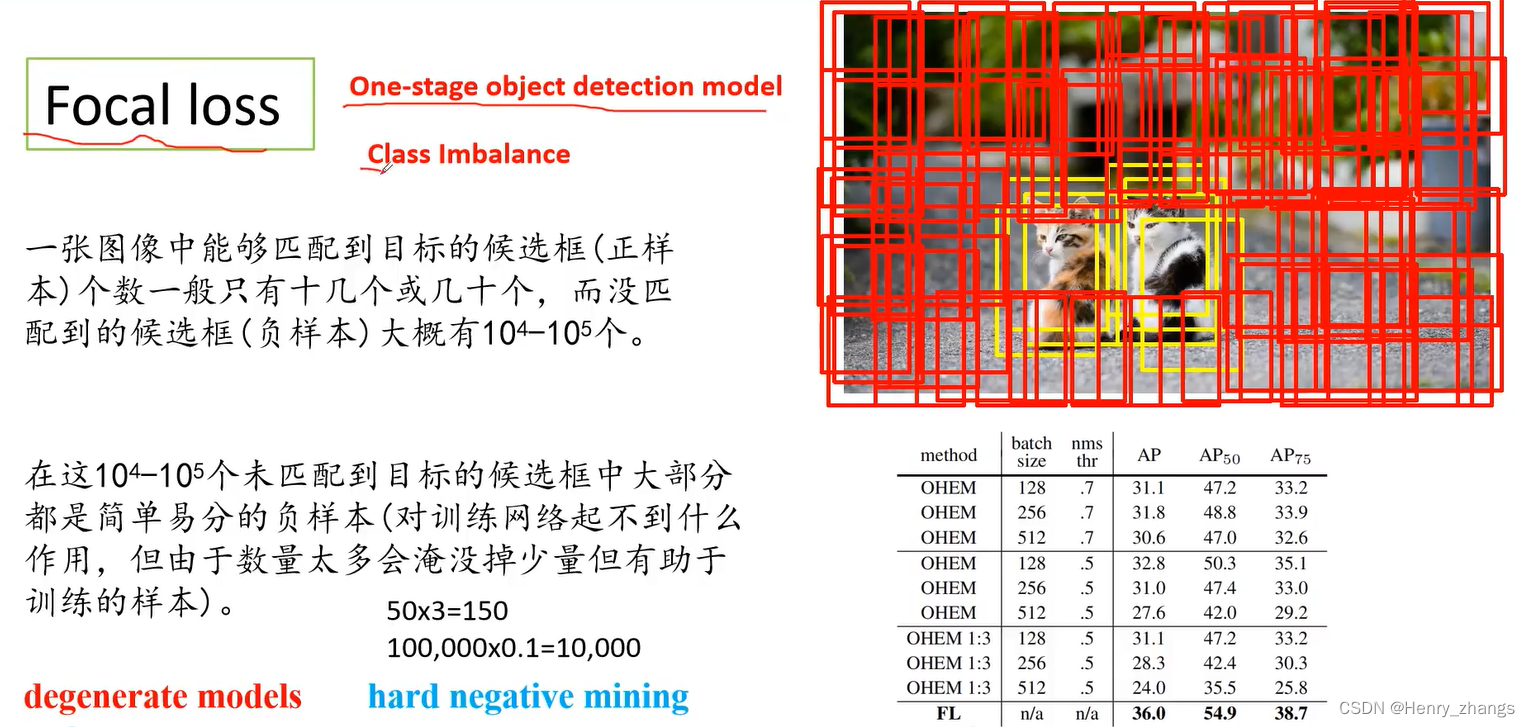
YOLO 是目标检测任务强大的算法,将目标检测的问题转换边界框和相关概率的回归问题,是目标检测单阶段的代表。
YOLO 的全称是You Only Look Once
本章只会对YOLO的前三个版本进行简单的介绍,后面会根据YOLO V3 SPP的trick版本进行训练
2. YOLO V1
yolo v1的代表图如下:
注意:yolo v1没有anchor 的概念
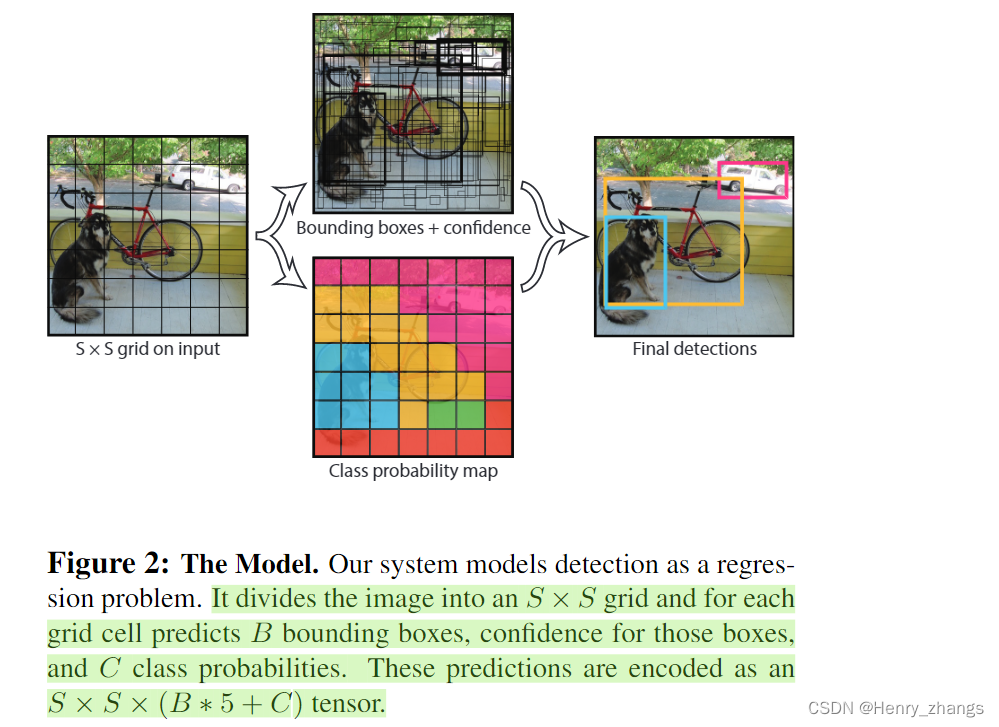
yolo v1将输入图像经过特征提取后,划分为 7 * 7(S = 7)个grid cell。每一个grid cell 会预测两个边界框(B = 2),而yolo v1是在PASCAL VOC 20 个类别进行训练的,所以每一个边界框还会预测20个类别得分(C = 20)。
其中每一个预测框还包括五个输出,前四个为边界框的x,y,w,h,最后一个是置信度,其实就是预测目标和真实ground truth的iou 。
每一个grid cell 产生两个边界框,由最好的那个边界框负责拟合真实的gt
所以,yolo v1的输入是一幅图像,输出是 7 * 7 *(2*5 + 20) = 7*7*30的张量(20个类别的得分是共享的)
yolo v1 的缺点:
- 因为7*7的网格只会预测49个物体,所以yolo v1对密集的物体或者多个小物体的检测不是很好
- 定位精度较差,没有像 faster-rcnn 那样基于anchor的准确
3. YOLO V2
yolo v2 相比于v1 增加了很多 ideas

总而言之,yolo v2的输入是416*416,输出是13*13(grid cell)*5(每一个网格预测五个边界框)* (5*20)的张量
4. YOLO V3
yolo v3输出是3个尺度的,分别是输入图像下采样的8、16、32倍。而一般输入的size是416*416,下采样后的三个尺度是52*52,26*26,13*13
yolo v3更改了网络的backbone,具体的yolo v3如下:
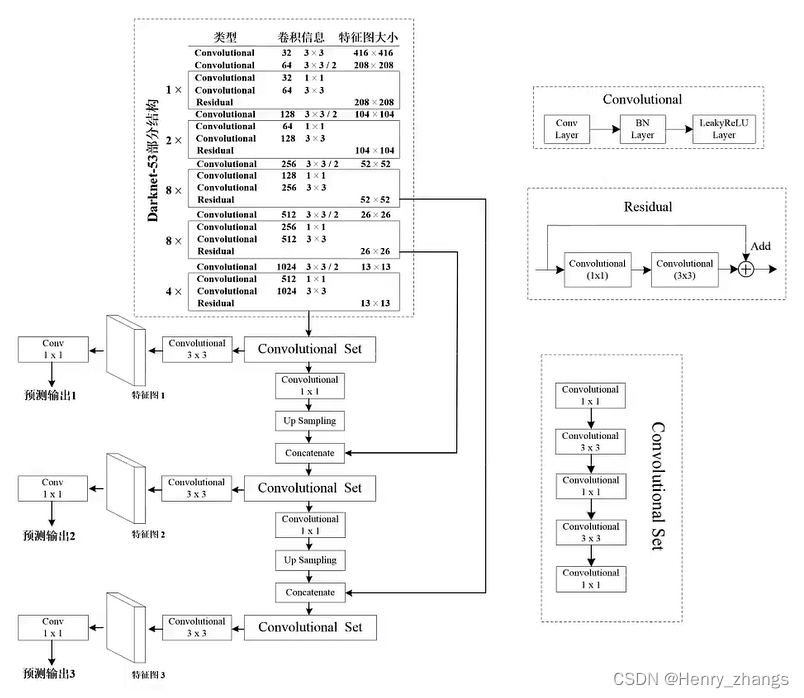
yolo v3输出的预测特征图是三个尺度,每一个grid cell 预测3个边界框,而每一个预测框产生4个坐标偏移值,1个置信度和80个coco的类别得分
关于偏移量,如下:
x、y 相对于每个grid cell左上角的偏移,经过sigmoid可以限制到0-1之间,这样预测的x、y就不会跑出对应的grid cell外面。w,h 相对于全图的缩放比例

关于正负样本分配:
正样本:针对于gt而已,预测最好的为正样本。每一个gt都会分配一个正样本
忽略的样本:预测的还行,但是不是最好的,例如与gt的iou >0.5,那么这类边界框忽略
负样本:剩下的样本均为负样本
5. YOLO V3 SPP网络
YOLO V3 SPP网络对提升网络性能增加了很多的tricks
5.1 Mosaic 图像增强
将多个图像拼接在一起训练,可以增加数据的多样性、单幅图像目标的个数也会增多
这里默认4张图像拼接

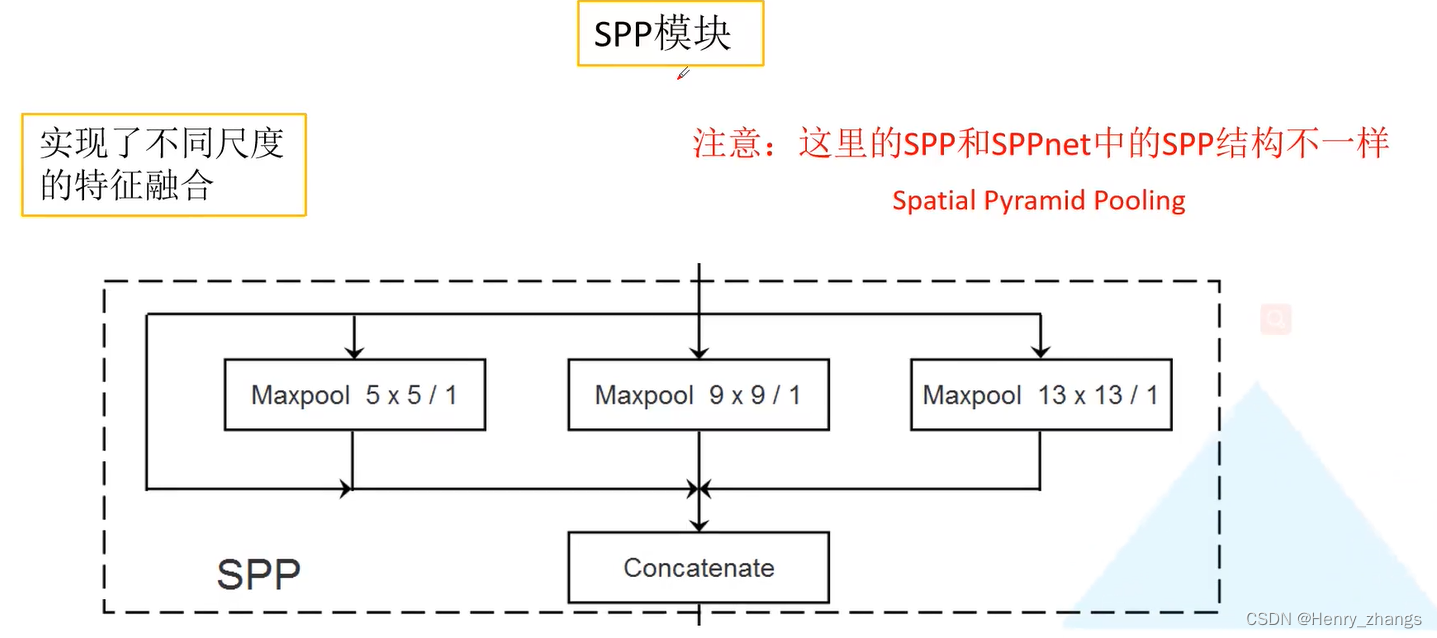
5.2 SPP 模块
多尺度输出结果前,仅仅在第一个前面增加了SPP模块,实现了不同尺度的信融合
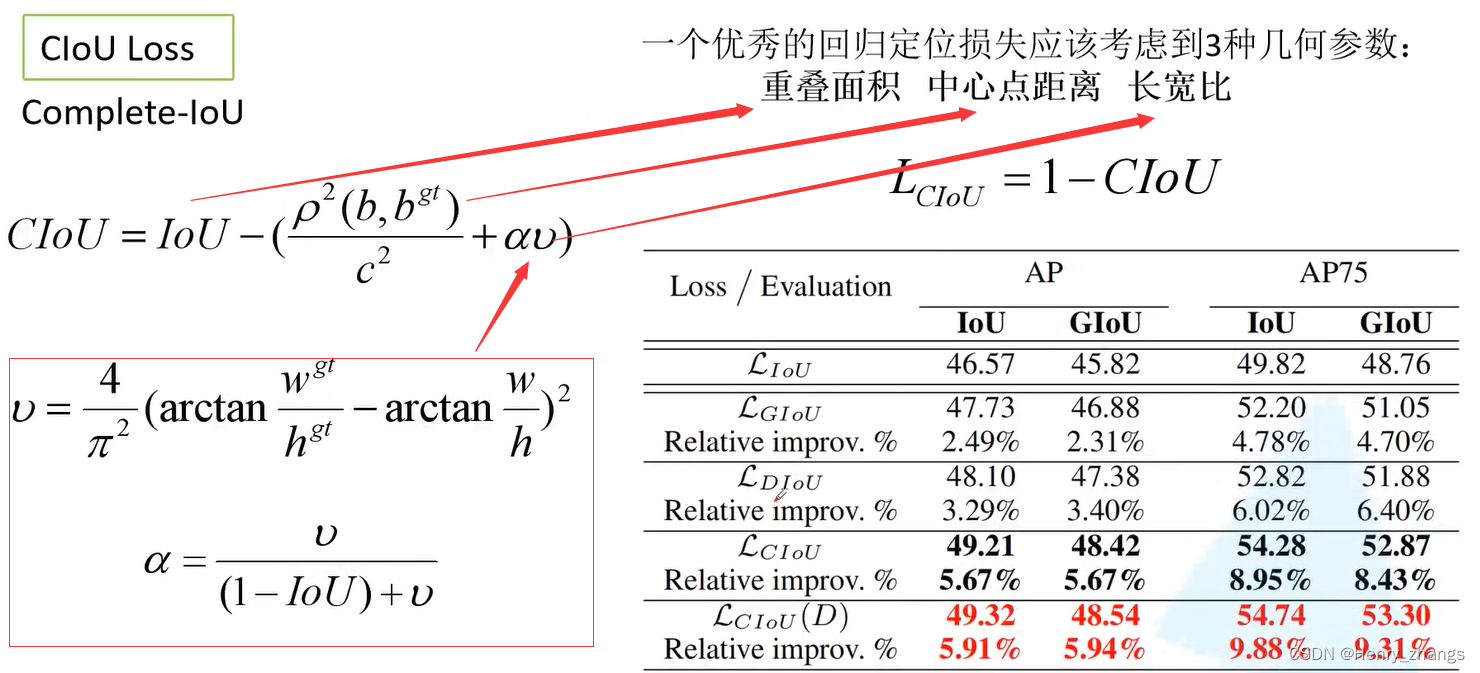
5.3 CIou Loss
CIou Loss 损失
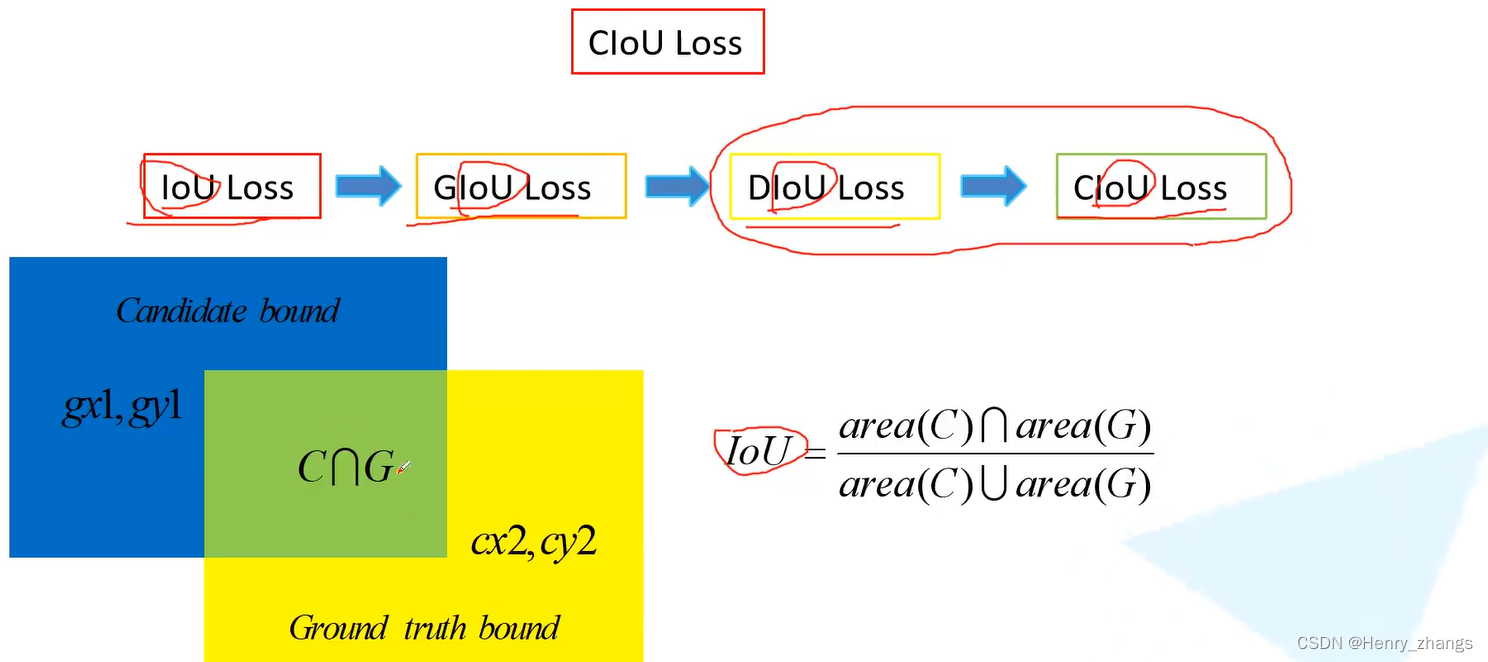
- 关于iou loss:
缺点是预测框和gt没有重合的时候,loss = 0

- 关于giou loss:绿色为预测,红色为gt
预测框和gt完美融合,giou = 1;预测框和gt相距无穷远,giou = -1
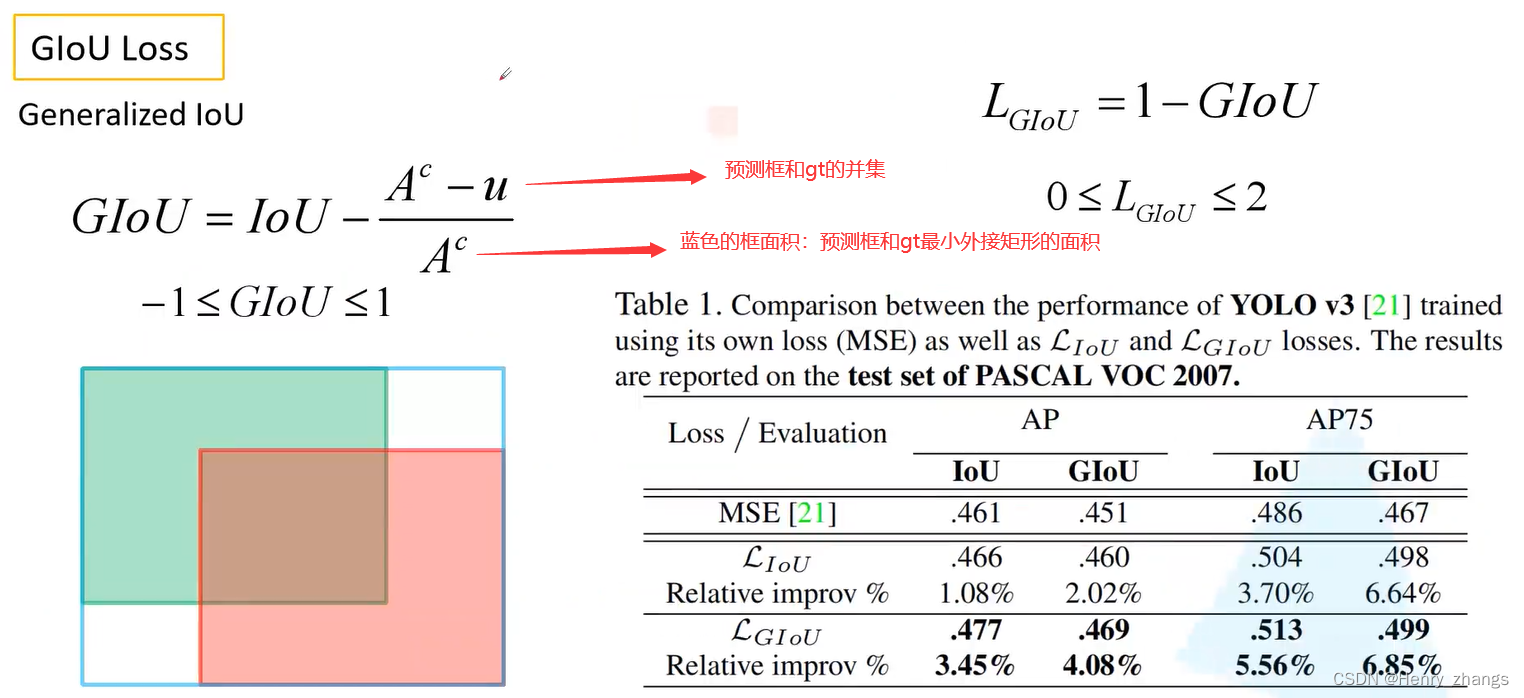
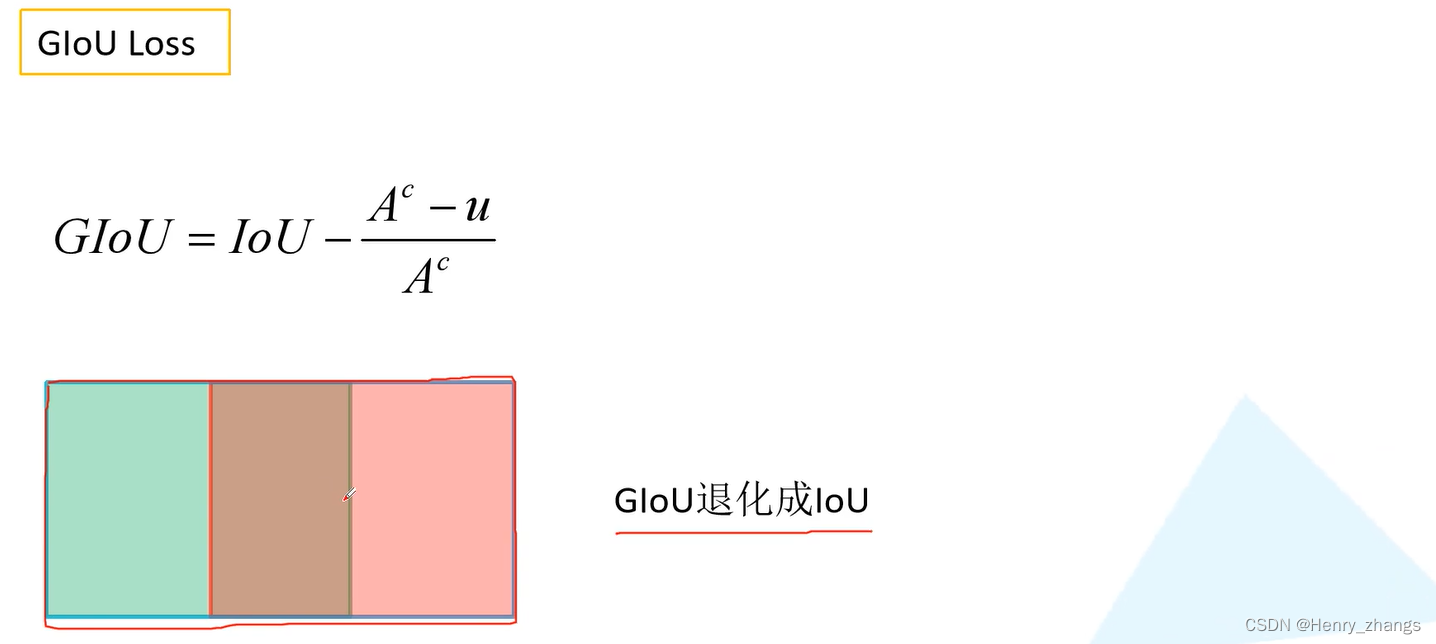
giou 的缺点:
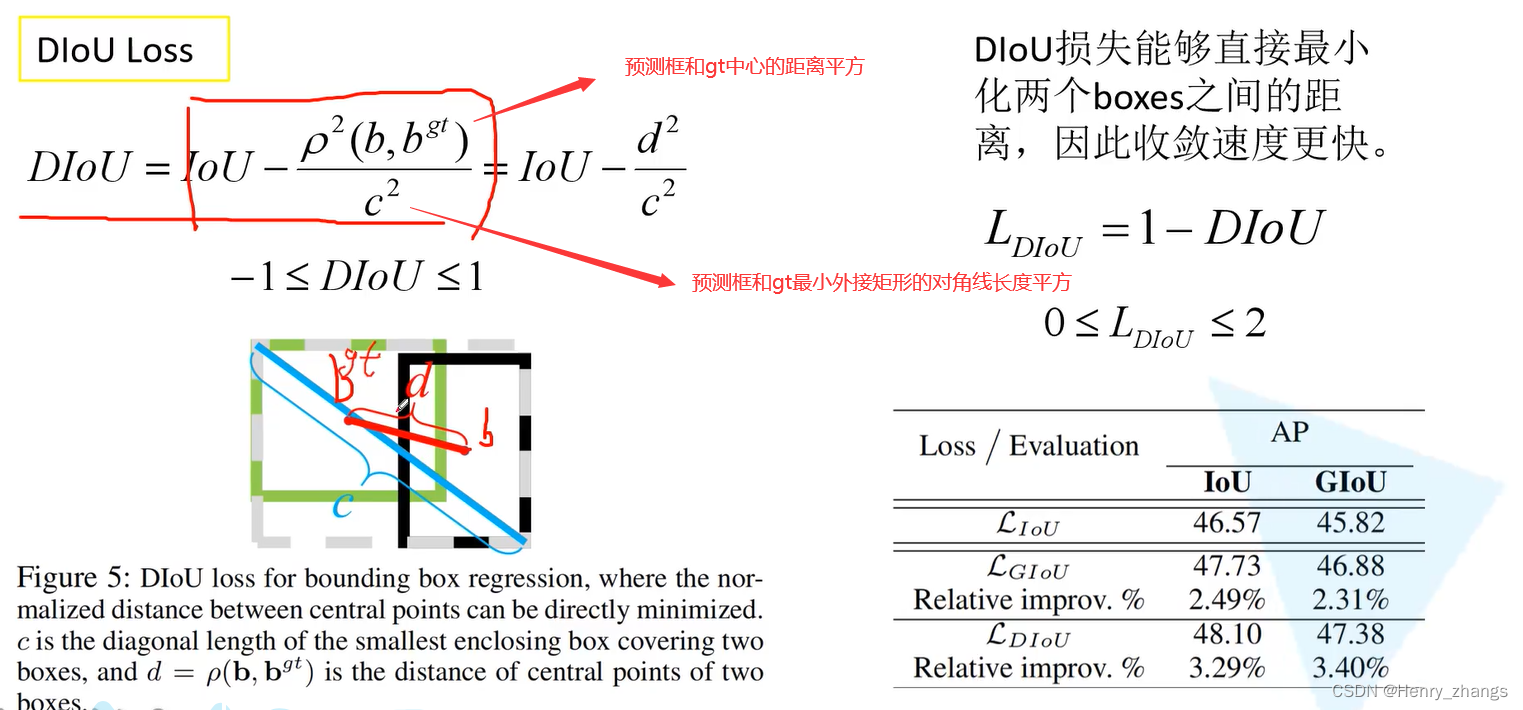
- 关于Diou loss:distance iou
iou loss 和 giou loss 有两个问题:收敛太慢、回归不够准确
预测框和gt完美融合,diou = 1;预测框和gt相距无穷远,diou = -1
- 关于Ciou loss:
5.4 Focal loss
Focal loss 最初用于图像领域解决数据不平衡造成的模型性能问题