功能测试可以手写一份测试报告
一、如何自动生成测试报告
unittest生成测试报告
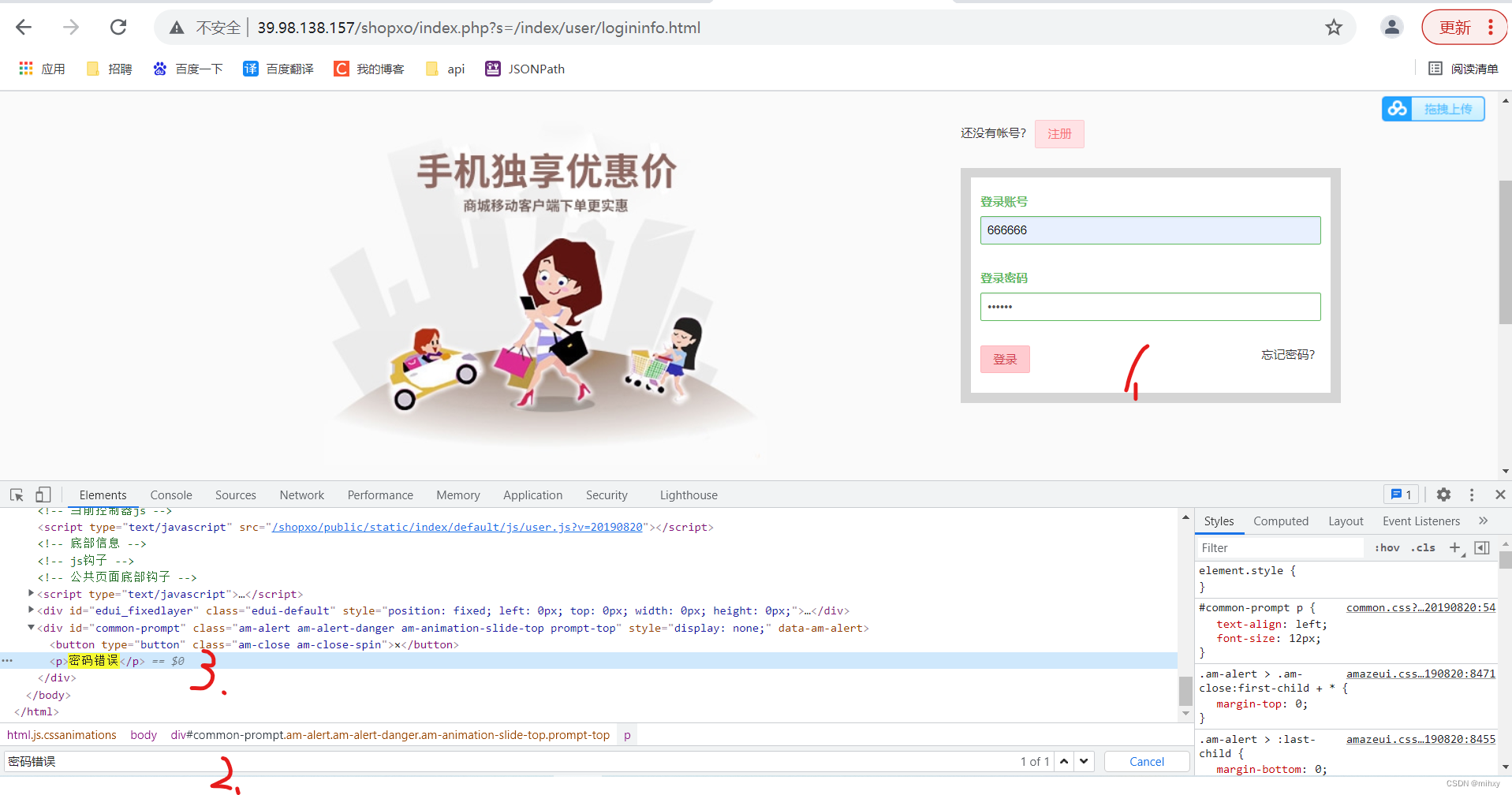
测试用例:账号正确,密码错误
自己依照测试用例输入一组账号,点登录,会出现信息,密码错误

代码:
import unittest
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 必须要继承unittest.TestCase
class TestCase(unittest.TestCase):
# setUP 用例执行前要执行的一个方法
def setUp(self) -> None:
# 登录的准备工作:打开浏览器,访问登录页
# 通过浏览器驱动打开谷歌浏览器
self.driver = webdriver.Chrome()
# 访问登录页
self.driver.get('http://39.98.138.157/shopxo/index.php?s=/index/user/logininfo.html')
# tearDown 用例执行之后要执行的一个方法
def tearDown(self) -> None:
# 关闭浏览器,一般会等待三秒钟关闭浏览器
# alt+enter 自动导包
time.sleep(4)
self.driver.quit()
# 测试过程 测试方法 一条测试用例就是一条test 一个方法必须以test开头
# 用户名正确。密码不正确
def test_01(self):
# 找到输入框,输入用户名
# 找到输入框,输入密码
# 找到登录按钮并点击登录
self.driver.find_element(By.XPATH, '/html/body/div[4]/div/div[2]/div[2]/form/div[1]/input').send_keys('666666')
self.driver.find_element(By.XPATH, '/html/body/div[4]/div/div[2]/div[2]/form/div[2]/input').send_keys('633333')
self.driver.find_element(By.XPATH, '/html/body/div[4]/div/div[2]/div[2]/form/div[3]/button').click()
# 预期结果
# expected='密码错误'
# 做断言
# 一般而言使用if expected ==
# unittest提供了断言
time.sleep(1)
msg=self.driver.find_element(By.XPATH, '//*[@id="common-prompt"]/p').text
self.assertEqual('密码错误', msg)
if __name__ == '__main__':
unittest.main()
注意事项:断言——找到密码错误
二、优化自动生成测试报告 unittest
Pytest 是在unittest基础上加深,会更好用一点,学的难度会高一点
1、unittest生成测试报告
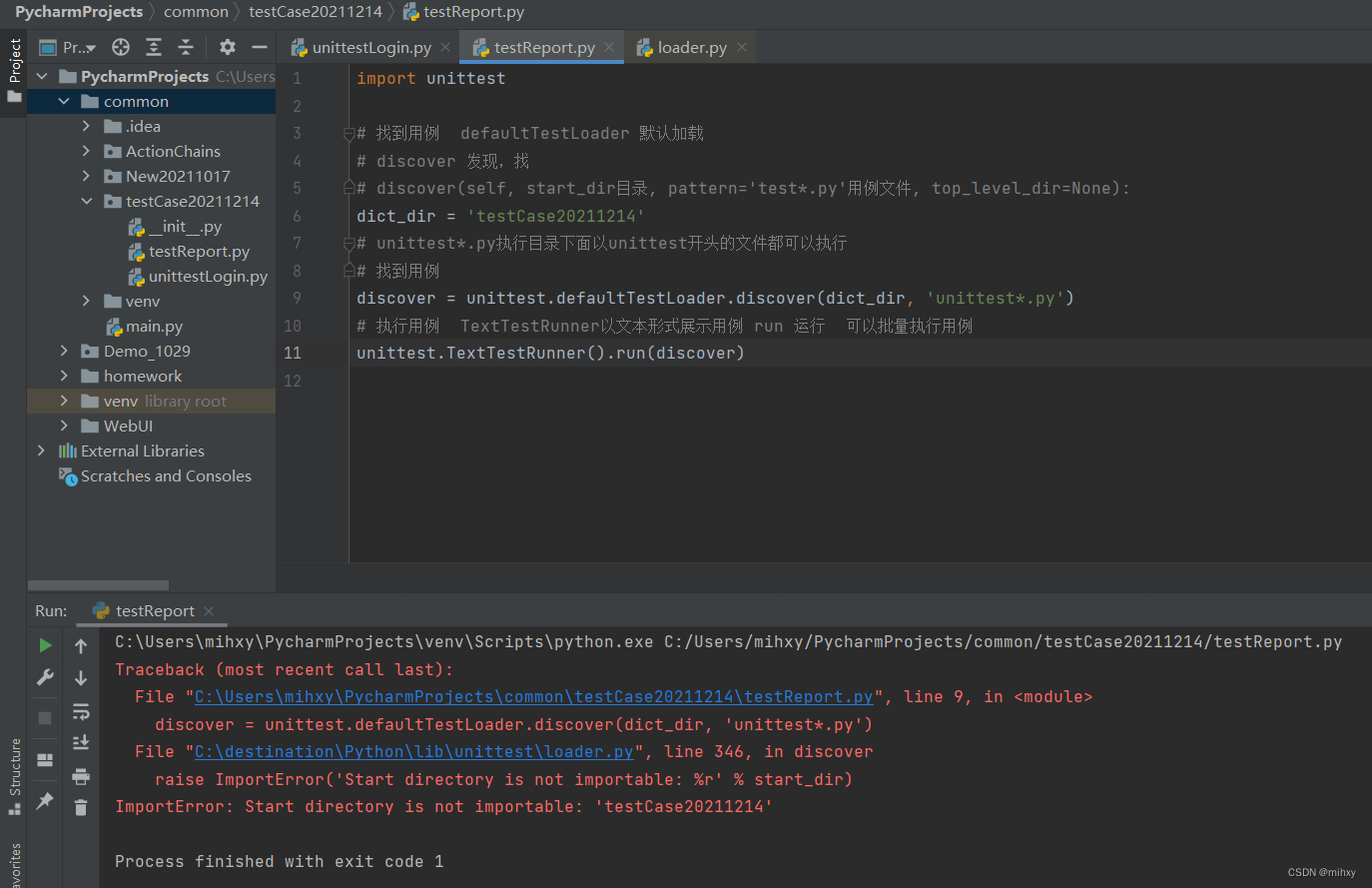
解决问题,导入os包,
正确答案:
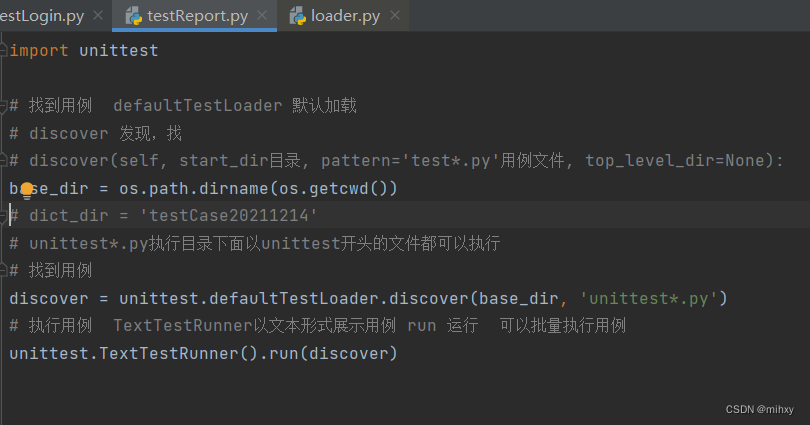
说明:testCase20211214是根目录
控制台输出的也是另类的一种测试报告,但是不全面,难理解
2、unittest有一种特有的生成文本测试报告的方法
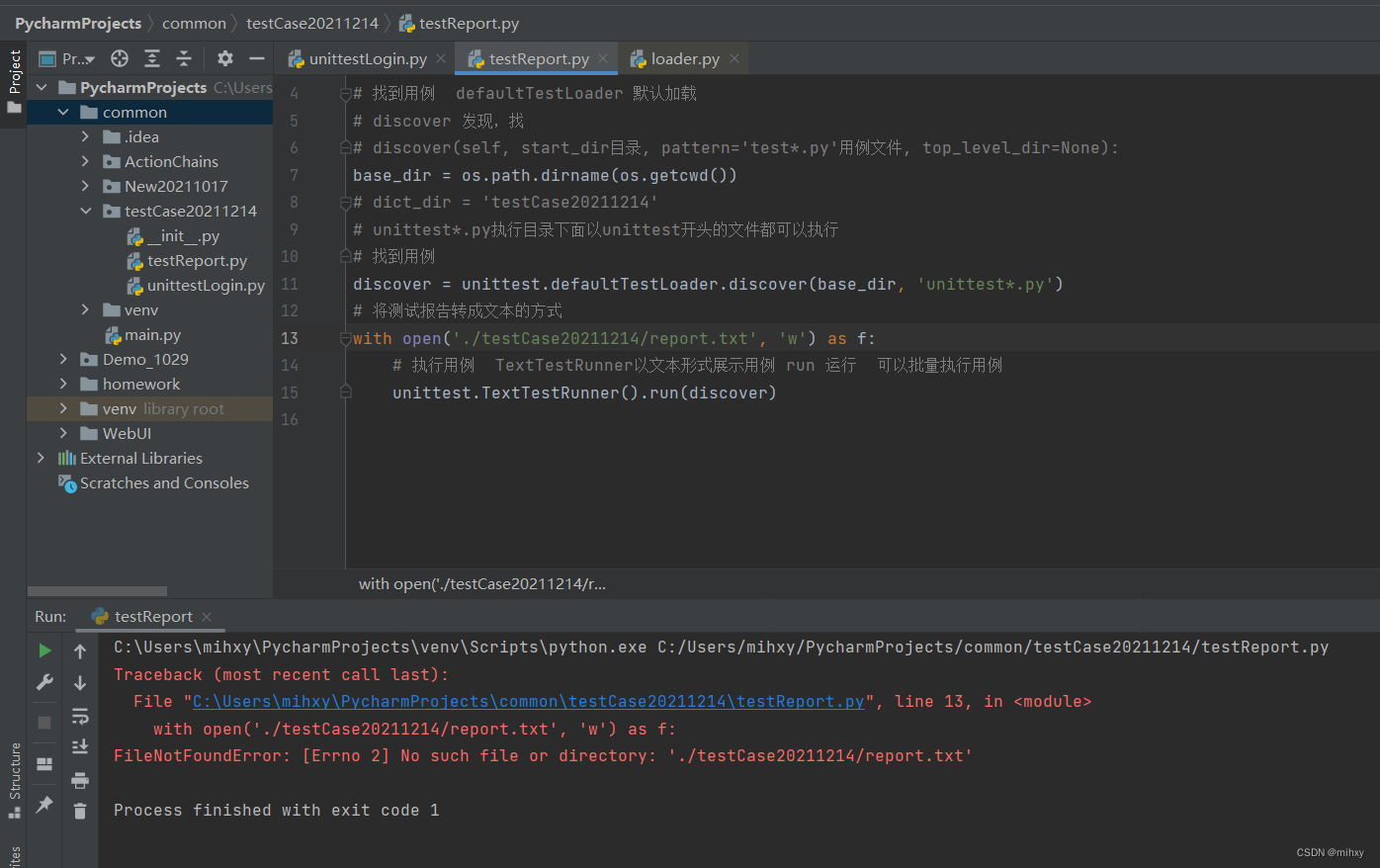

上面问题主要是路径写错了,直接找到根目录下创建文件
正确答案:

运行效果:
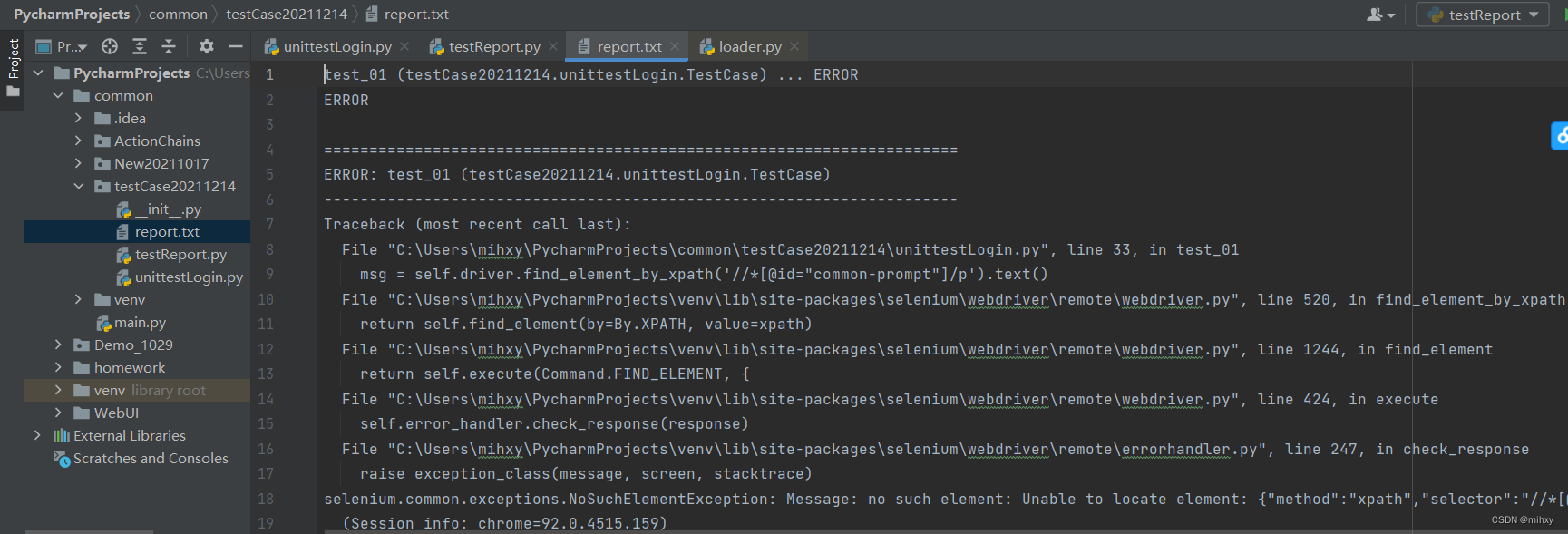
上面的test_01,test_02每执行一次都会新打开一次浏览器
3、插件,html testrunner安装
html testrunner是针对unittest自动生成的测试报告的一个升级
1)下载htmlTestRunner
HTMLTestRunner - tungwaiyip's software
注意事项:如果htmltestrunner有问题,可以依据下面的修改方案修改
htmlTestRunner.py只支持python2,python3不兼容python2
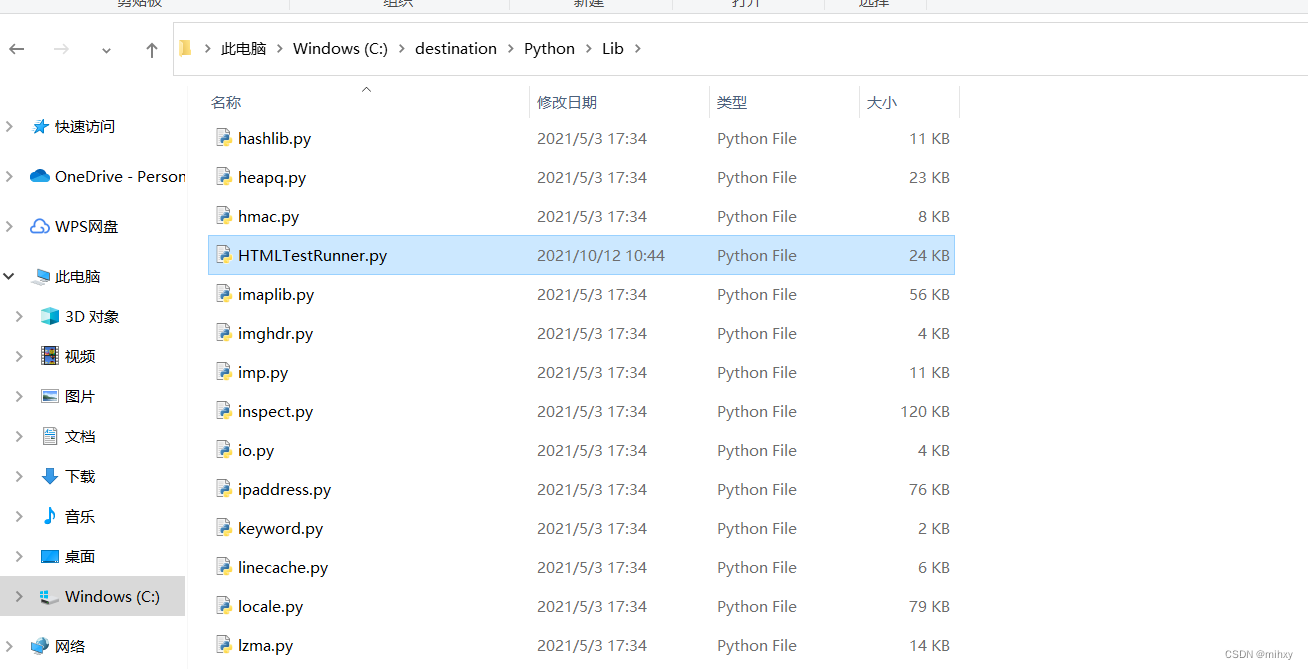
2)查看python版本

3)将htmltestrunner放到lib下面
4)使用HtmlTestRunner.py来实现测试报告

5)运行效果:html文件要用浏览器打开

6)出现问题,运行失败,测试报告也没出现
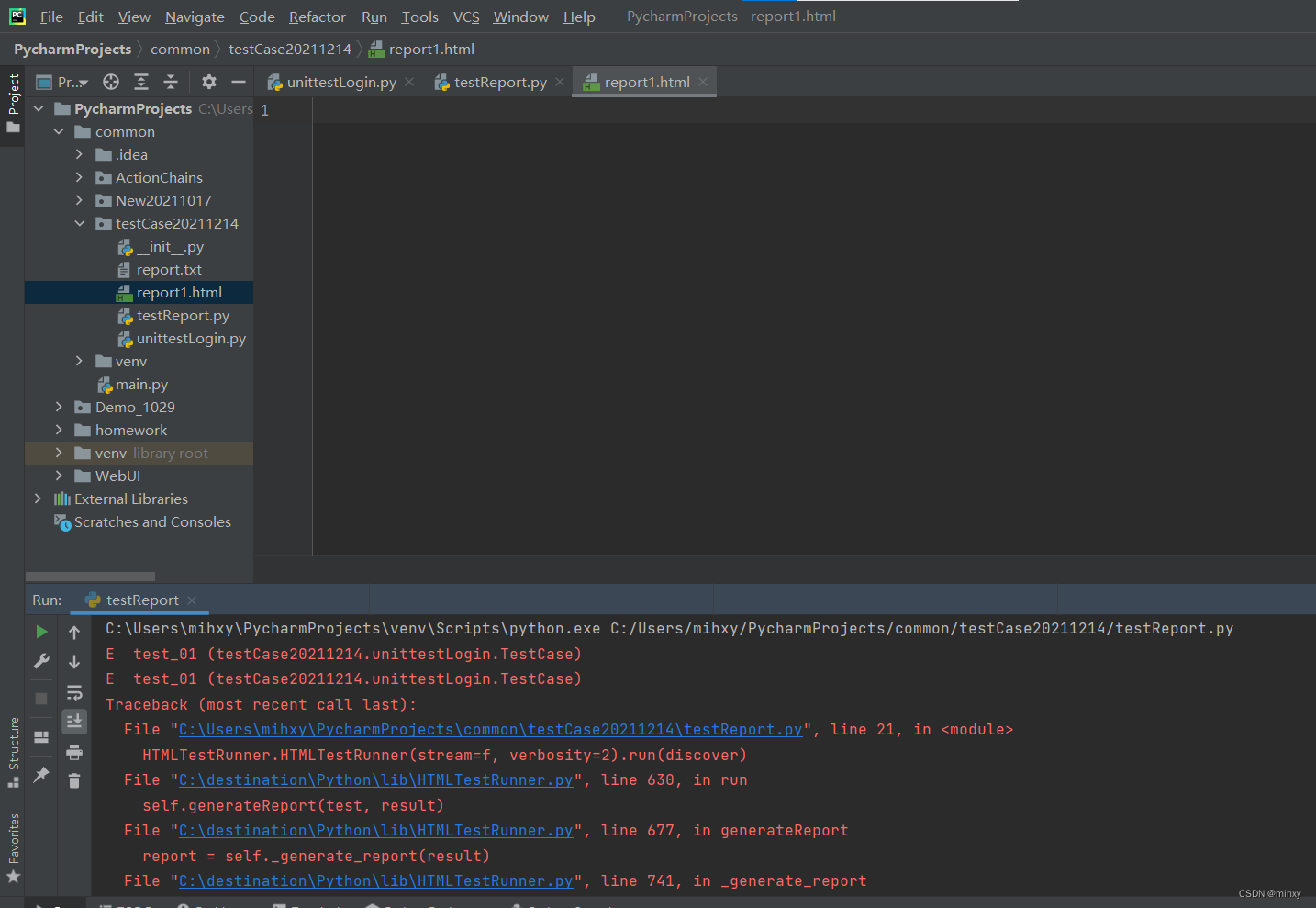
- 6、1)检查是不是HtmlTestRunner.py文件错误
Python+Selenium+HTMLTestRunner 自动生成测试报告,打开却是空白的解决方法
参考文档:
Python+Selenium+HTMLTestRunner 自动生成测试报告,打开却是空白的解决方法_晚晴懒懒懒的博客-CSDN博客
在做测试过程中,最重要的一步就是测试报告的生成,自动化测试也需要做到自动生成测试报告。但unittest是不能生成html格式报告的,这就需要导入一个第三方的模块:HTMLTestRunner。
一:下载 HTMLTestRunner
下载路径:https://pypi.python.org/pypi/HTMLTestRunner ,下载后放到 Python的安装目录\Lib 该目录下。
Download下HTMLTestRunner.py文件就是我们需要下载的包。如果你点击后只能打开此文件,可以将文件内容复制到记事本中并另存为 HTMLTestRunner.py。
二、修改 HTMLTestRunner.py文件
如果你安装的是python2版本,那么不需要做这一步。因为HTMLTestRunner.py 原本就是python2版本,目前还没找到python3版本,所以需要我们自己修改 HTMLTestRunner.py 文件。
修改内容如下:
第94行,将import StringIO修改成import io
第539行,将self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
第642行,将if not rmap.has_key(cls):修改成if not cls in rmap:
第766行,将uo = o.decode('latin-1')修改成uo = e
第774行,将ue = e.decode('latin-1')修改成ue = e
第631行,将print >> sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime)修改成print(sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime))
其中,Python3中,已经没有StringIO了。取而代之的是io.StringIO。
- 6、2)确认htmltestrunner修改无误后,继续运行生成了报告,但是打开还是空白
可能原因一:没有关闭文件,加上代码 fp.close() 即可。
可能原因二:我是用Python unit-test方式进行运行,后面改为Python Run运行后正常生成了报告
7)加上代码fp.close()运行

By需要提前导入
from selenium.webdriver.common.by import By
错误“AttributeError:’builtin_function_or_method’ object has no attribute ‘sleep’”
python编程,才使用time.sleep(n)挂起函数时遇到这个错误
原因:使用引入是 from time import *
解决:引入换成 import time
参考文档:
8)重新运行

参考文档: 解决网页元素无法定位(NoSuchElementException: Unable to locate element)的几种方法_哈士奇说喵的博客-CSDN博客
分析可能应该是加载时间不够导致的报错,因为在执行断言的时候,浏览器已经关闭了
time.sleep(10):将等待时间放长了会跳到腾讯课程?
time.sleep(3)会报Bug
不做断言,不会报错
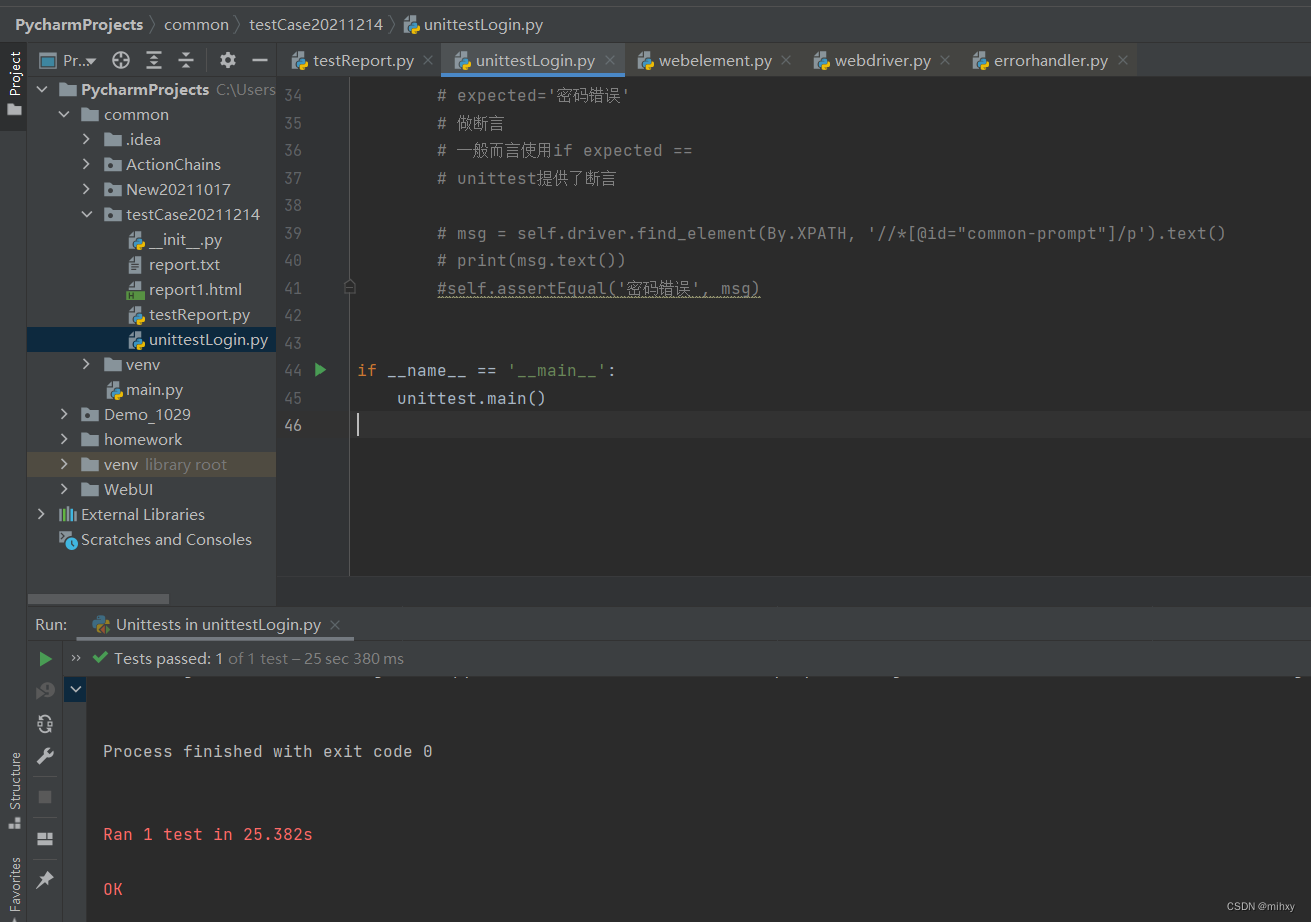
将时间变长试试看
报错:

selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 92
Current browser version is 101.0.4951.67
原因是:浏览器的版本不一致,应该是浏览器自动更新了
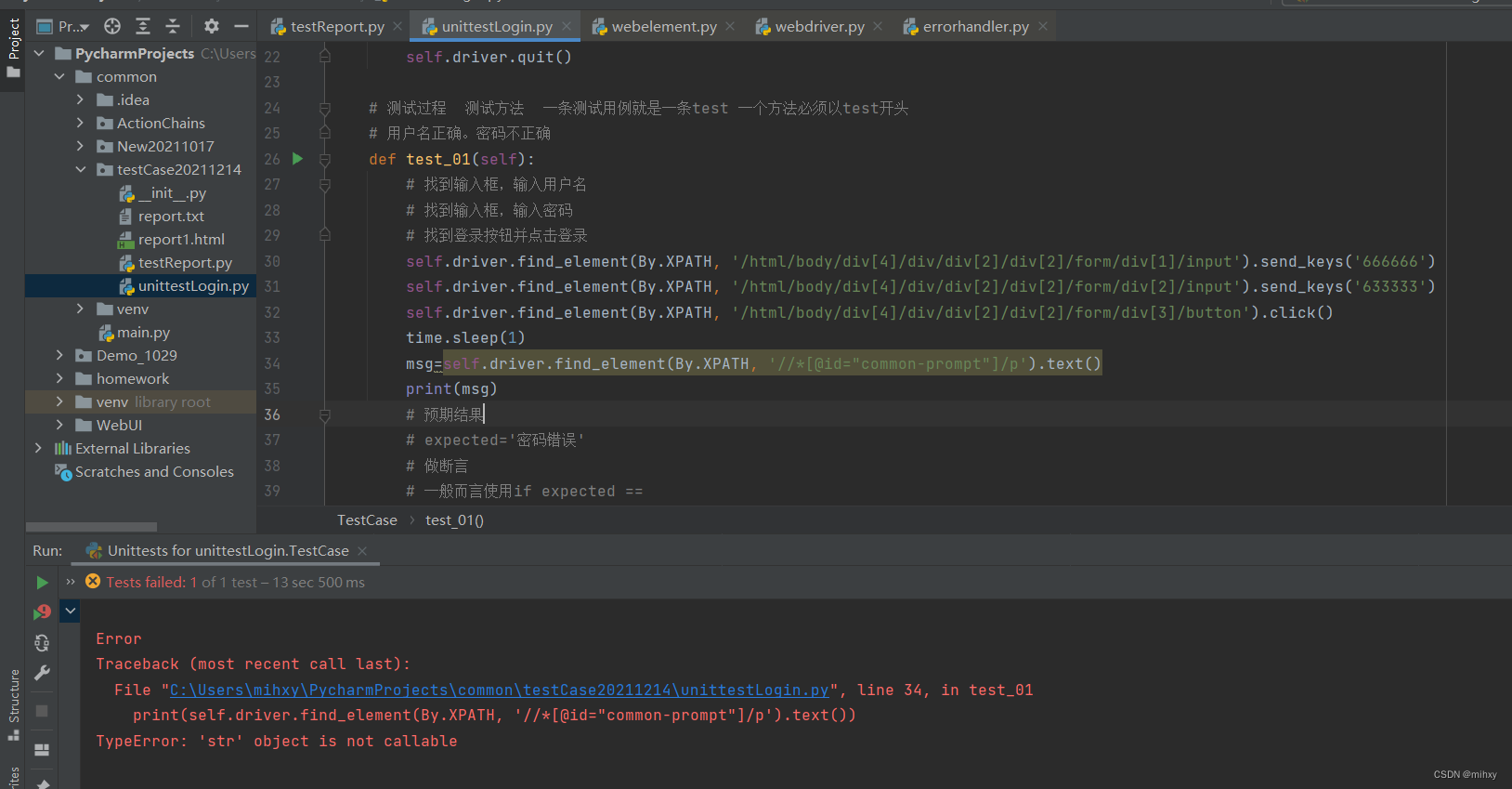
9)python报TypeError: 'str' object is not callable错误的解决办法
参考文档:
python报TypeError: 'str' object is not callable错误的解决办法 - python - web教程网
找到原因:
例子三:函数或者字符串调用错误
def get_list_urls(self):
for list in self.domainList:
#print(self.domainList[list])
url = self.domainList[list]
reqs = requests.get(url = url, headers = self.headers)
html = reqs.text()
bfHtml = BeautifulSoup(html)
上例子也会报:'str' object is not callable
其原因是:requests的返回值reqs并没有text()方法,BeautifulSoup接收一个字符串,而我们误将 reqs.text 写成了 reqs.text(),就造成了这个错误。
下面修改的代码:
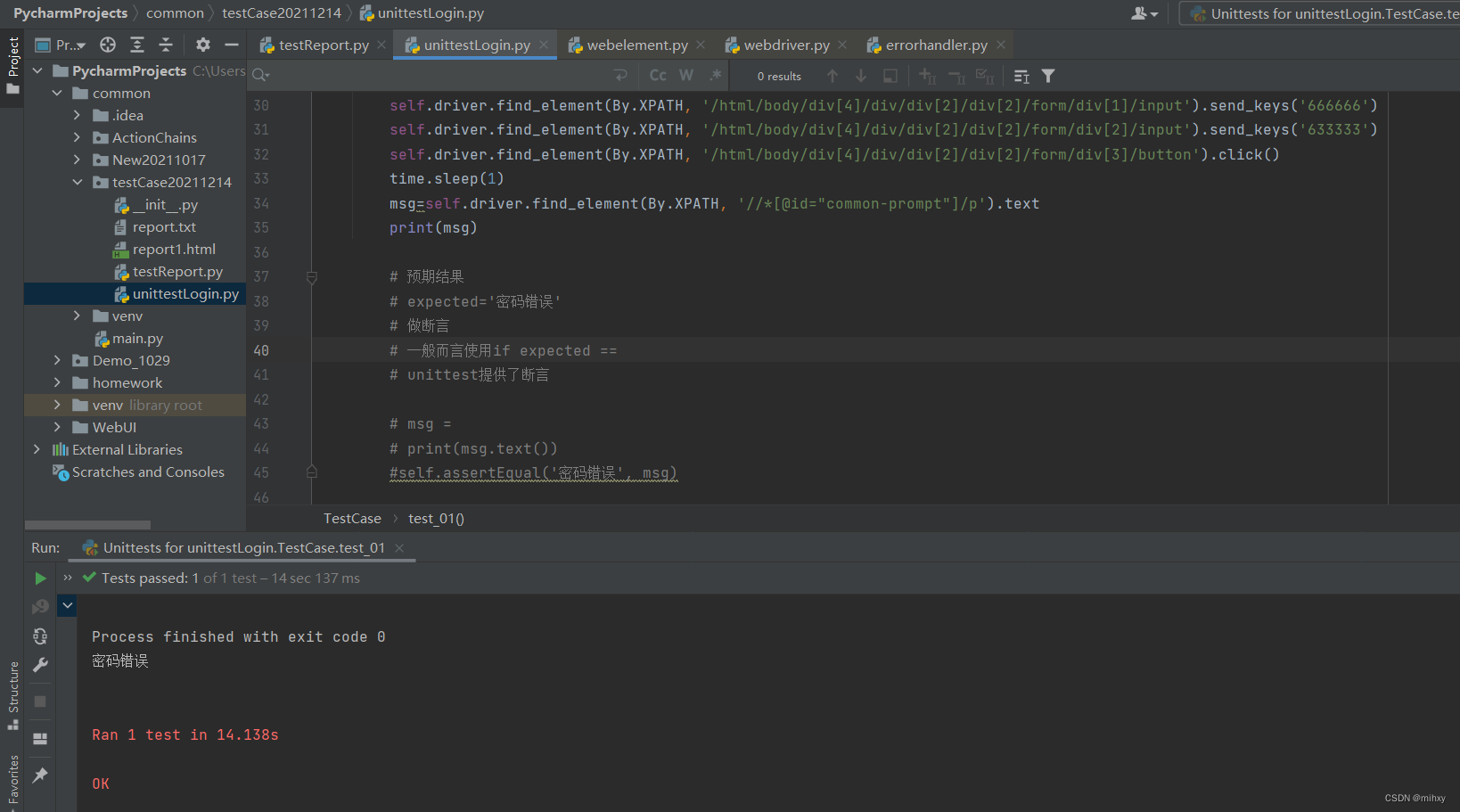
10)完整修改后的代码:
import unittest
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
#必须要继承unittest.TestCase
class TestCase(unittest.TestCase):
#setUP用例执行前要执行的一个方法
def setUp(self)->None:
#登录的准备工作:打开浏览器,访问登录页
#通过浏览器驱动打开谷歌浏览器
self.driver=webdriver.Chrome()
#访问登录页
self.driver.get('http://39.98.138.157/shopxo/index.php?s=/index/user/logininfo.html')
#tearDown用例执行之后要执行的一个方法
def tearDown(self)->None:
#关闭浏览器,一般会等待三秒钟关闭浏览器
#alt+enter自动导包
time.sleep(4)
self.driver.quit()
#测试过程测试方法一条测试用例就是一条test一个方法必须以test开头
#用户名正确。密码不正确
def test_01(self):
#找到输入框,输入用户名
#找到输入框,输入密码
#找到登录按钮并点击登录
self.driver.find_element(By.XPATH,'/html/body/div[4]/div/div[2]/div[2]/form/div[1]/input').send_keys('666666')
self.driver.find_element(By.XPATH,'/html/body/div[4]/div/div[2]/div[2]/form/div[2]/input').send_keys('633333')
self.driver.find_element(By.XPATH,'/html/body/div[4]/div/div[2]/div[2]/form/div[3]/button').click()
#预期结果
#expected='密码错误'
#做断言
#一般而言使用ifexpected==
#unittest提供了断言
time.sleep(1)
msg=self.driver.find_element(By.XPATH,'//*[@id="common-prompt"]/p').text
self.assertEqual('密码错误',msg)
if__name__=='__main__':
unittest.main()
注意事项:time.sleep(1)不能够省略
后面可以优化,让他用及时等待
11)运行报错

AttributeError: ‘str‘ object has no attribute ‘decode‘解决方法
参考文档:
AttributeError: ‘str‘ object has no attribute ‘decode‘解决方法_柠 檬没我萌的博客-CSDN博客
分析原因是,pyhon2和python3的差异问题
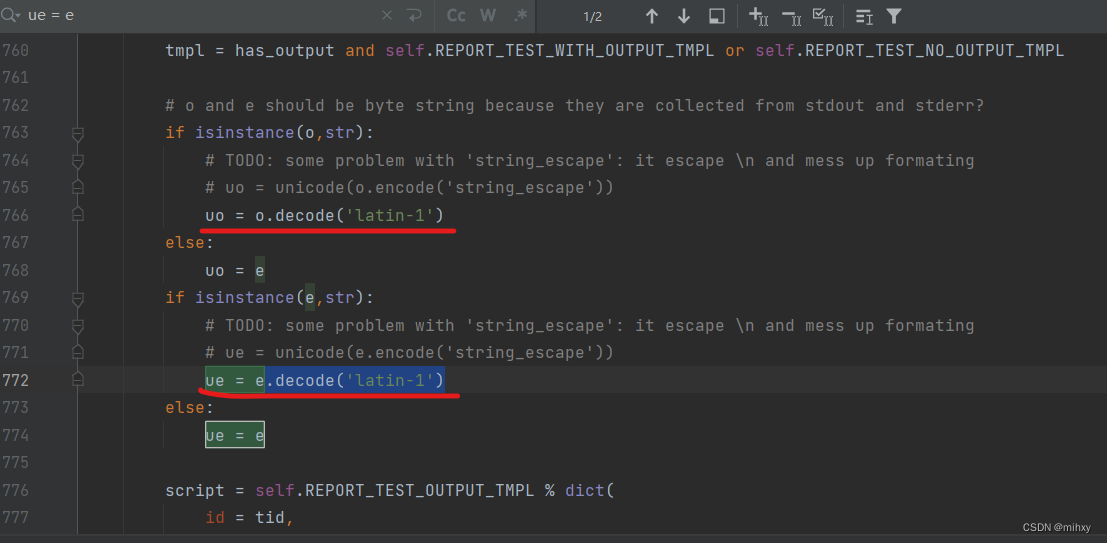


12)修改完成后
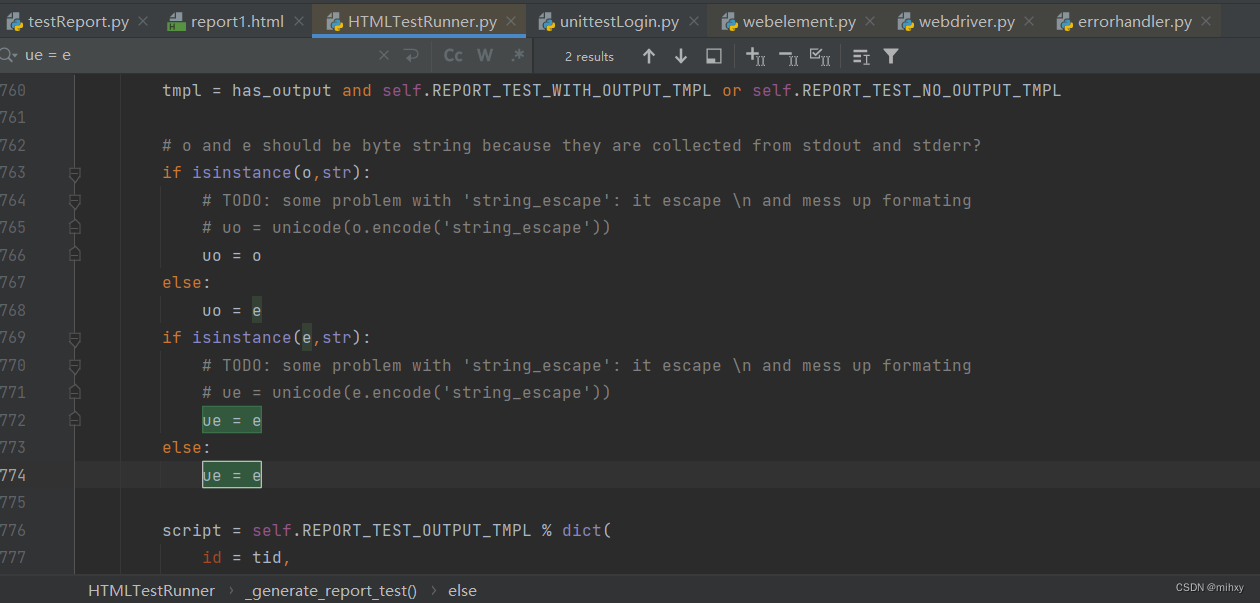
13)执行
1、unittest自带测试报告

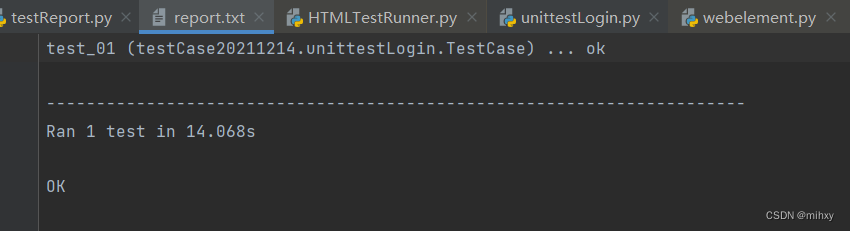
2、htmlTextRunner.py 生成的测试报告 pycharm打开是html代码
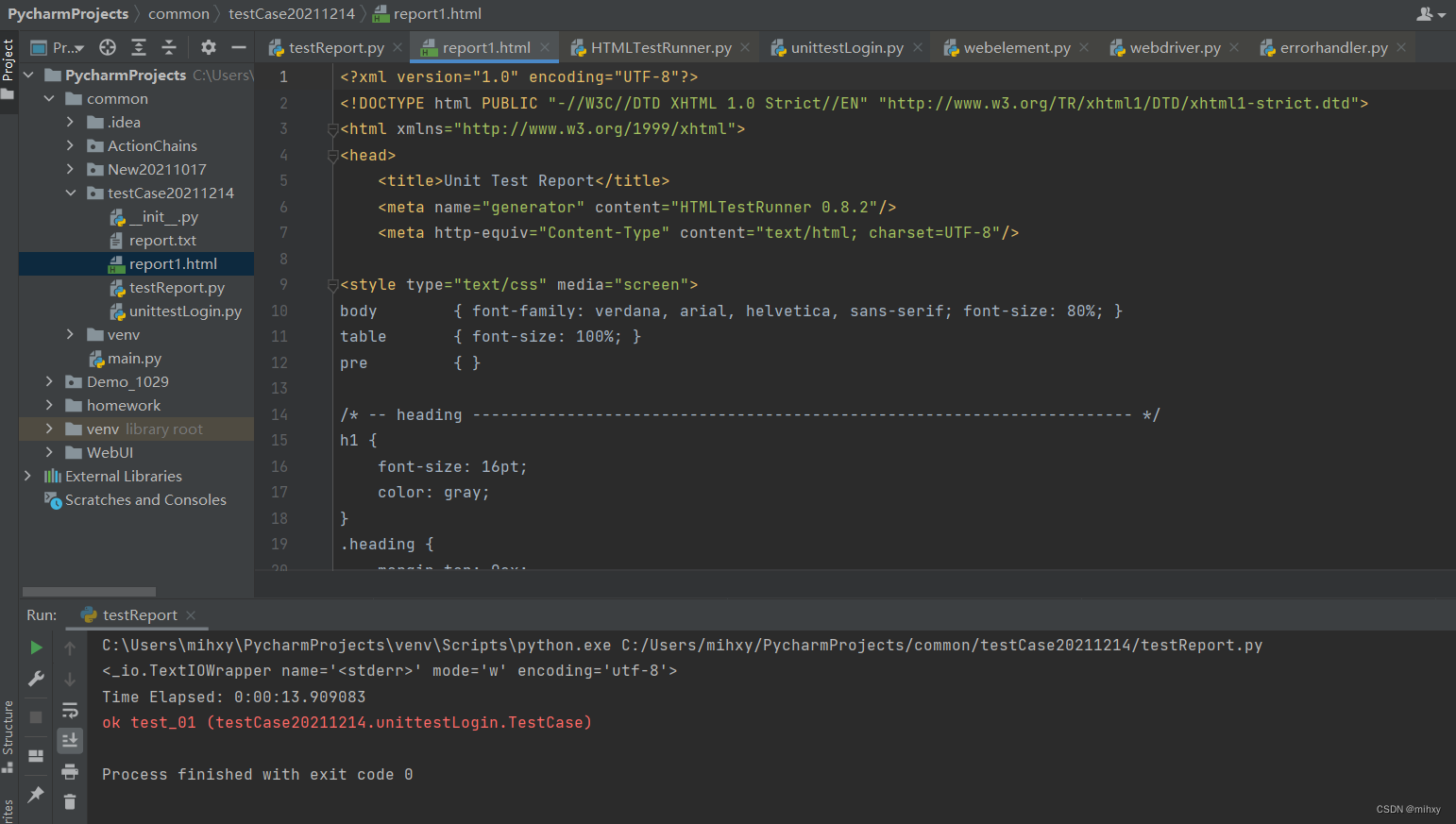
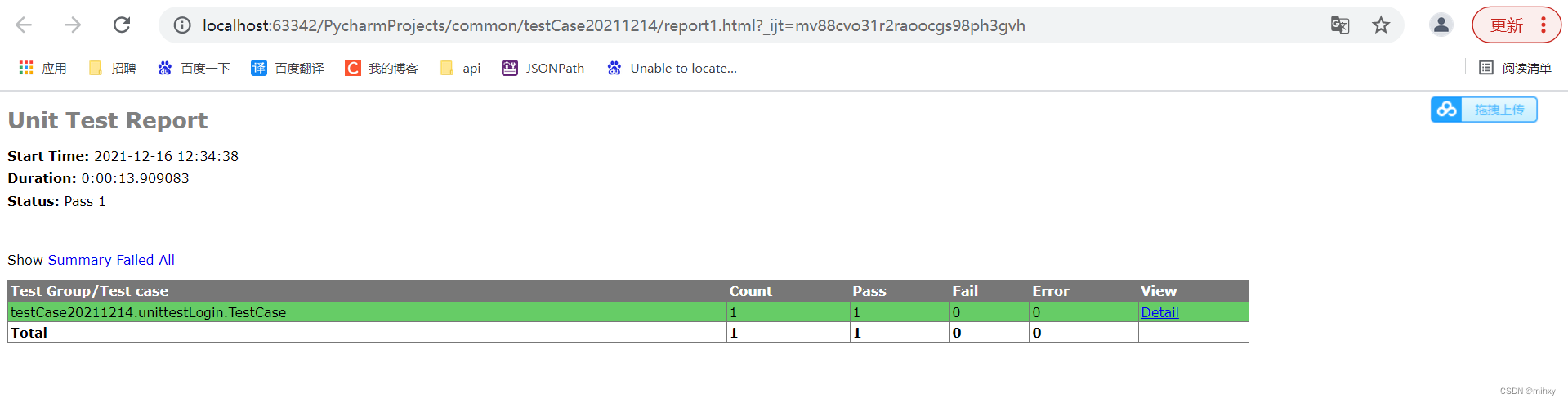
3、继续优化测试报告
参考文档:
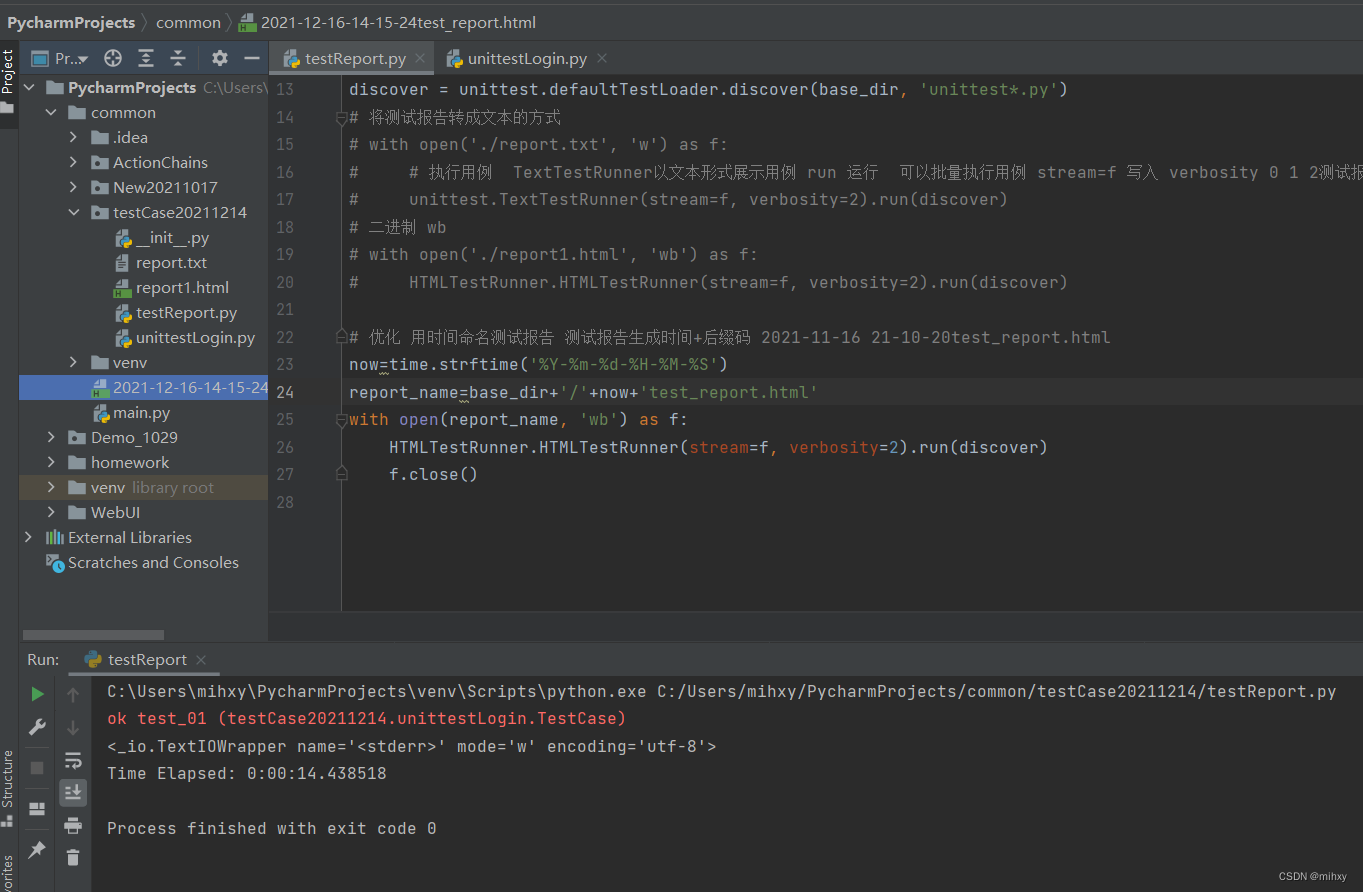
测试报告生成错了地方,路径错了
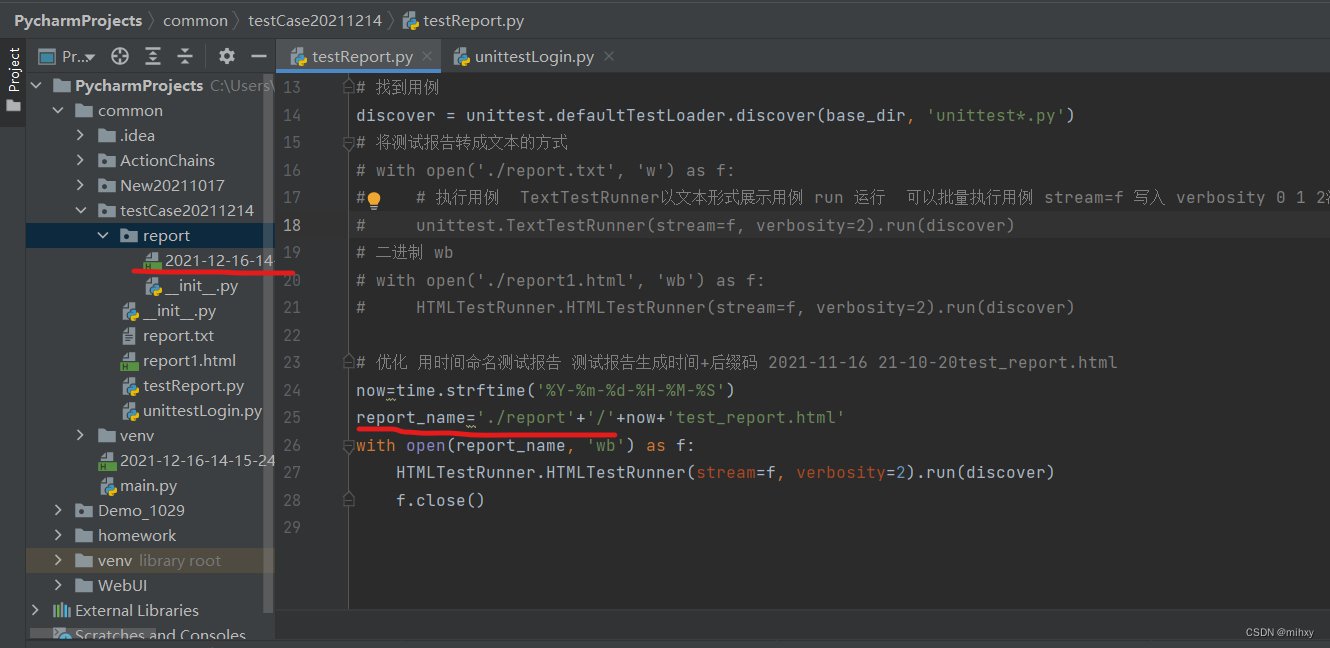
这样路径是在我想要的地方
完整代码:
import os
import time
import unittest
import HTMLTestRunner
#找到用例defaultTestLoader默认加载
#discover发现,找
#discover(self,start_dir目录,pattern='test*.py'用例文件,top_level_dir=None):
base_dir=os.path.dirname(os.getcwd())
#dict_dir='testCase20211214'
#unittest*.py执行目录下面以unittest开头的文件都可以执行
#找到用例
discover=unittest.defaultTestLoader.discover(base_dir,'unittest*.py')
#将测试报告转成文本的方式
#withopen('./report.txt','w')asf:
##执行用例TextTestRunner以文本形式展示用例run运行可以批量执行用例stream=f写入verbosity012测试报告的详细程度2表示详细
#unittest.TextTestRunner(stream=f,verbosity=2).run(discover)
#二进制wb
#withopen('./report1.html','wb')asf:
#HTMLTestRunner.HTMLTestRunner(stream=f,verbosity=2).run(discover)
#优化用时间命名测试报告测试报告生成时间+后缀码2021-11-1621-10-20test_report.html
now=time.strftime('%Y-%m-%d-%H-%M-%S')
report_name='./report'+'/'+now+'test_report.html'
withopen(report_name,'wb')asf:
HTMLTestRunner.HTMLTestRunner(stream=f,verbosity=2).run(discover)
f.close()

优化的重点是:每执行一次都会生成一个测试报告,每个测试报告都有执行时间,这样就不会像前面两个案例一样,后面的执行出现的测试报告覆盖之前的测试报告
4、继续优化、扩展:
1、HTMLtextrunnerCN.py生成的测试报告比HtmlTestRunner更好看
2、BSTestRunner.py
3、Allure 测试报告平台
测试报告的区别在于好不好看,哪些更好看,给领导同事看让他们觉得炫酷而已
个人扩展的方向:比如
用例执行错误了,添加截图
三、知识点
find_element_by_xpath不能使用

解决方案:
find_element_by_*已被废弃使用find_element来代替
参考文档:
http://blog.sina.com.cn/s/blog_53a99cf301030fv4.html
原先的写法
browser.find_element_by_class_name("sort-area")
browser.find_element_by_xpath("//*[text()='时间排序']")
现在的写法
browser.find_element(By.CLASS_NAME,"sort-area")
browser.find_element(By.XPATH,"//*[text()='时间排序']")
源码:
使用find_element代替
def find_element(self,by=By.ID,value=None)->WebElement:
"""
FindanelementgivenaBystrategyandlocator.
:Usage:
::
element=driver.find_element(By.ID,'foo')
:rtype:WebElement
"""
if isinstance(by,RelativeBy):
return self.find_elements(by=by,value=value)[0]
if by==By.ID:
by=By.CSS_SELECTOR
value='[id="%s"]'%value
elif by==By.TAG_NAME:
by=By.CSS_SELECTOR
elif by==By.CLASS_NAME:
by=By.CSS_SELECTOR
value=".%s"%value
elif by==By.NAME:
by=By.CSS_SELECTOR
value='[name="%s"]'%value
return self.execute(Command.FIND_ELEMENT,{
'using':by,
'value':value})['value']