1、文章采用的是回归的方法来做关键点的预测,中间的监督是对坐标的监督,而不是对map的监督,中间map的产生
是简介学习得到的,其实主要是soft-argmax实现了一把映射。
1)采用soft-argmax将map转换成坐标,直接对坐标监督,不需要产生map的监督
2)语义信息可以seamlessly在这个框架里学到
2、map预测的缺点
1)需要heatmap向坐标的转化,使得整个过程不连续,毕竟在map上取最大值是一个不可微操作,not-end-to-end
2)精度过分取决于heatmap的分辨率的大小
3、网络结构
1)Entryflow+blockA+blockB
Entryflow负责特征提取,blockA负责对特征的refine,blockB提供身体part的map图和语义信息的map图。网络由一个 Entryflow+k个(blockA+blockB)构成
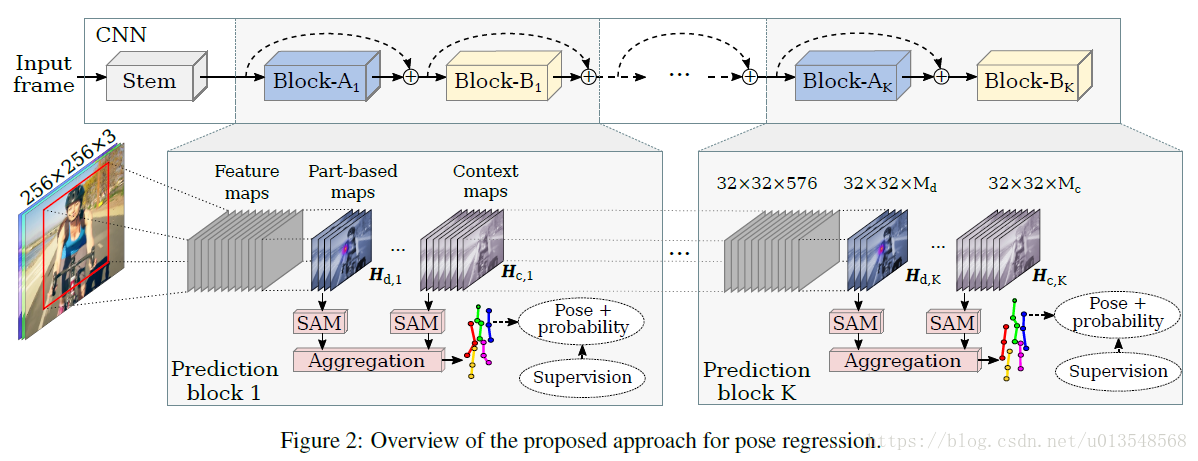
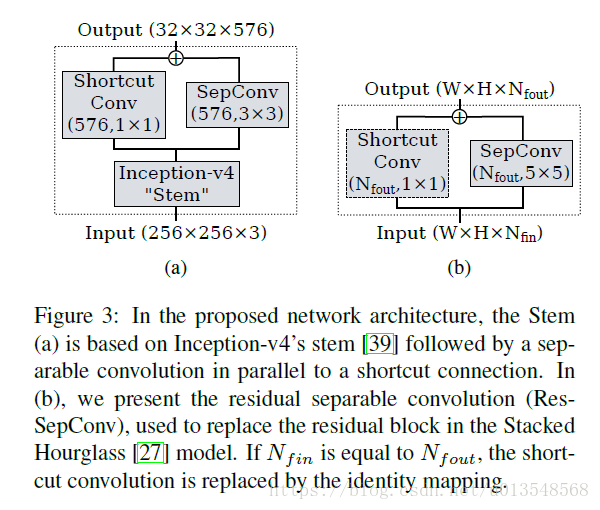
2)
Stem:Inception-v4+Sepconv
3)
BlockA:采用和hourglass相同的结构,只不过这里把所有的残差网络变成残差可分离网络(Sep-Conv),另外文中的map分辨率有三个等级,hourglass是5个等级。
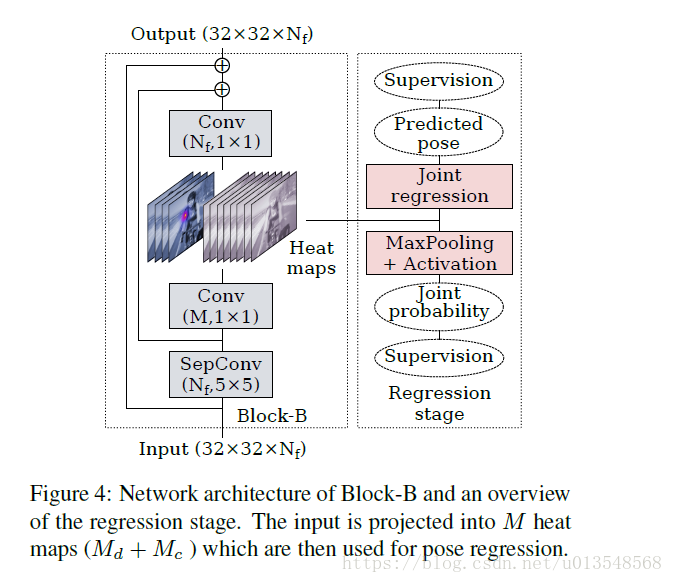
4)
BlockB:将输入map变成M个输出,
,
代表的是part的数量等于
,
,其中
代表的是每个关节点的预测的context map的数量,文章最后
,什么是context map呢?文章好像没有解释,来看他的图吧

context map也不过是一些修正类的map,也是学出来的,怎么学出来的呢,看下面部分。
(在blockB结束后通过1x1map通过映射返回到特征空间,以便输入到下一个block内)
4、
怎么将这些part map和context map映射到坐标呢,以前的做法来个全连接层就可以了,这样效果很差的,所以作者就提出了soft_argmax的方法!
1)在一张WXH的map上面做空间softmax,这很合乎情理吧
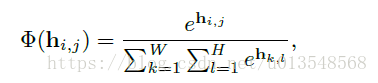
2)然后获得利用这个softmax后的map获得坐标,怎么弄呢?
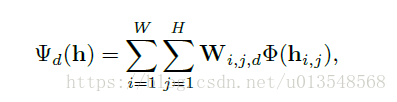
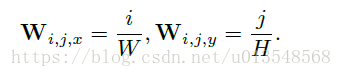
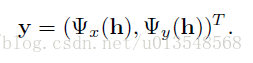
由于作者没有推导,那么怎么解释上面的公式呢?首先了解每个参数的含义!
d是x或者y,因为之后要在x,y两个维度上操作
W是一个WXHX2的权重矩阵,分为
两个权重矩阵,分别对应x,y两个维度呢!
以d=x为例说明,
分母是常数,设为A
其中 , 且 ,所以上面式子含义就是求位置的期望,也即最后的x坐标点是在1~M的那一个,根据期望获得,并且最终除以M将坐标归一化到[0,1]之间,呜~。y坐标也是这样获得的。
3)这样
就是h map图最终的坐标
4)soft-argmax的反传作者推好了,作者推了,我就不写了
5)记下来预测关节点的概率,有了位置还不行,还要预测概率的,现将
max pooling,然后sigmoid一下,最后获得概率值。
6)怎么将part预测结果和context预测结果结合在一起呢?
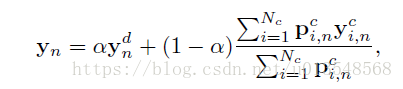
这里的d不再是x或者y了,表示detection的意思,只是说明特征是part来的,第n个part的坐标等于第n个part对应的part heatmap经过soft-argmax提取到的坐标和context map经过soft-argmax提取到的坐标进行加权获得,加权参数由
获得。而对于一个part的
张context map的坐标又是通过对这些context map进行概率加权获得的,加权的部分由
来决定,其实也是说每张context map对最后的贡献是不一样的,又各自的概率值决定比重。
5、训练
训练分为坐标点的回归和概率值的预测两个损失,前缀采用L1L2损失,后者采用交叉熵损失
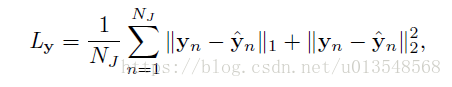
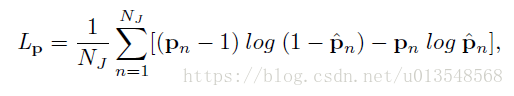
作者最后提到context map作用就是一个refine,通过indirectly的方式学习到的。