目录
2. urllib.error.HTTPError: HTTP Error 403: Forbidden解决
1. urllib模块
Python中urllib模块专门用于读取web中的数据。只要拿到url,我们就能拿到所需要的对象,进而获取data。
from urllib import request
def getResponse(url):
url_request=request.Request(url)
print(url_request.get_method())
url_response=request.urlopen(url)
return url_response
http_response=getResponse("http://data.people.com.cn/publish/_s1/0819.html")
print(http_response.read().decode('utf-8'))url_request = request.Request(url)用来做初始化。request首先用来请求一个url地址,拿到Request对象。
拿到的对象作为urlopen的参数,用来获取请求的对象。
print(http_response.read().decode('utf-8'))拿到网页内容,decode标明解码格式,避免中文解码乱码。
这种方法足够抓取一般网页的内容了。
2. urllib.error.HTTPError: HTTP Error 403: Forbidden解决
在遇到稍好一点的网站时用urllib.request.urlopen的方式请求,由于服务器端接收不到发送端的其他信息,会将请求化为非正常访问,进行拒绝。、
以edge为例,要查看设备向网站发送的的信息,先点击f12,再点击网络标签,刷新页面,在“标头”下方的“请求标头”查看header内容。
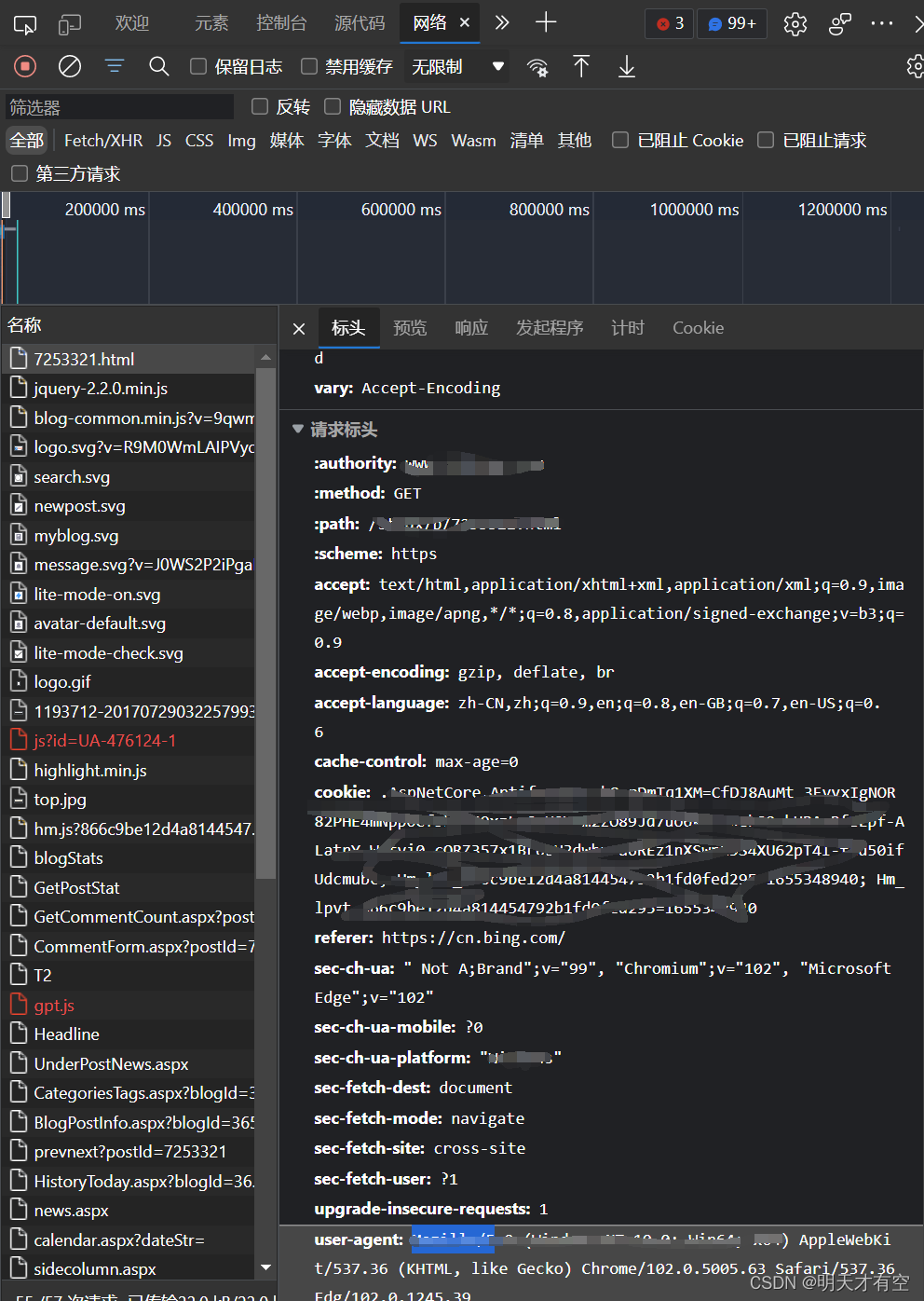
将其添加到request中再进行请求即可模拟浏览器访问向服务器发送请求。
headers = {'Accept': 'text/html, application/xhtml+xml, image/jxr, */*',
'Accept - Encoding':'gzip, deflate',
'Accept-Language':'zh-Hans-CN, zh-Hans; q=0.5',
'Connection':'Keep-Alive',
'Host':'zhannei.baidu.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}
r = requests.get('http://zhannei.baidu.com/cse/search', params=keyword, headers=headers, timeout=3)