MMEditing代码阅读笔记二:main()函数中的build_dataset()
今天,继上篇文章捋清楚build_model()函数之后,进入build_dataset()函数里面看了看。
总结就是:换汤不换药。
build_dataset()函数执行框图
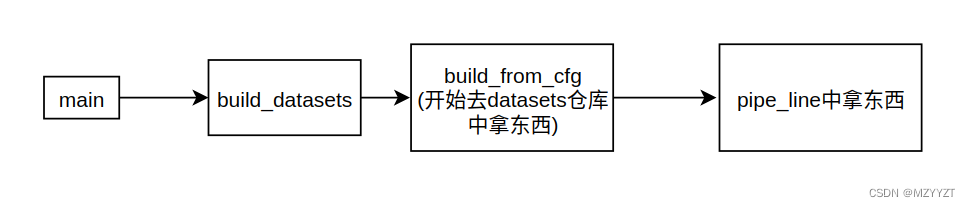 最后pipe_line()那块:其实这块从大框架来说并不能当作是一个独立的模块。或者可以这么说(上篇文章 我们说道build_from_cfg函数中的obj_type = args.pop(‘type’)语句会将除了type类型的其他属性copy到args这个参数中,然后args会赋值给type对应value的实例化对像。) 然后,进入pipe_line里面继续迭代取出type,并将其他属性赋值给type对应的实例化对象。 我觉得简单一点就像一个大函数里面有一对小函数,顺序执行罢了。
最后pipe_line()那块:其实这块从大框架来说并不能当作是一个独立的模块。或者可以这么说(上篇文章 我们说道build_from_cfg函数中的obj_type = args.pop(‘type’)语句会将除了type类型的其他属性copy到args这个参数中,然后args会赋值给type对应value的实例化对像。) 然后,进入pipe_line里面继续迭代取出type,并将其他属性赋值给type对应的实例化对象。 我觉得简单一点就像一个大函数里面有一对小函数,顺序执行罢了。
这里你可以在调试的时候观察type类型的变化 并对比配置文件中的train_pipeline(以edsr_x2c64b16_g1_300k_div2k.py为例) 只是截取了一部分。

首先,你可以把下图当作大函数,或许叫做外层对象更恰当。
 然后,实例化好外层对象之后,开始进入内层对象的建立(对应上面咱说的所谓的小函数,注:对应着上面的字典列表来看,也正是在这一步进入了pipe_line里面) pipe_line的功能就是对数据进行归一化、翻转、取出patch… 也就是常说的预处理。
然后,实例化好外层对象之后,开始进入内层对象的建立(对应上面咱说的所谓的小函数,注:对应着上面的字典列表来看,也正是在这一步进入了pipe_line里面) pipe_line的功能就是对数据进行归一化、翻转、取出patch… 也就是常说的预处理。


到此,退出build_dataset()函数,创建数据部分执行完毕。。
另外,发现train_loader 封装数据这块 在后续的train_model()函数中执行。
好了,关于这部分的记录到此为止。