1、带动量的随机梯度下降
主要思想:累积前面梯度的数值,使得当前这次梯度更新受之前梯度的影响。即使当前更新的情况快要到达一个鞍点的时候也能根据之前的累积梯度 帮助跨过鞍点

如何结合速度和梯度得到最终更新的方向
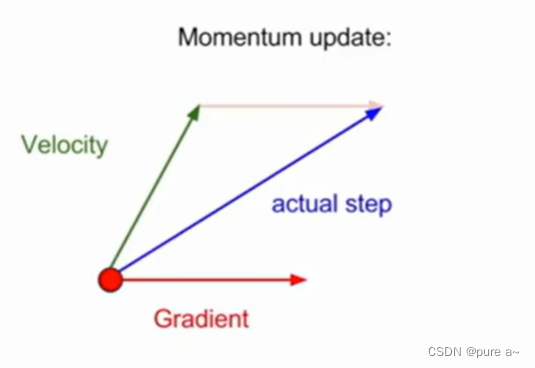
绿色向量是速度向量 或者说是动量向量 红色是当前计算出的梯度 蓝色表示经此方法处理后最后实际用来更新的方向
Momentum在梯度下降的过程中加入了惯性,使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡
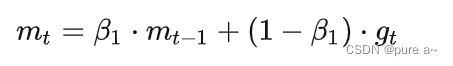

缺点:
这种情况相当于小球从山上滚下来时是在盲目地沿着坡滚,如果它能具备一些先知,例如快要上坡时,就知道需要减速了的话,适应性会更好。
2、Nesterov Accelerated Gradient
相比之前的动量 加入了未来的信息 其选择方向的方式为
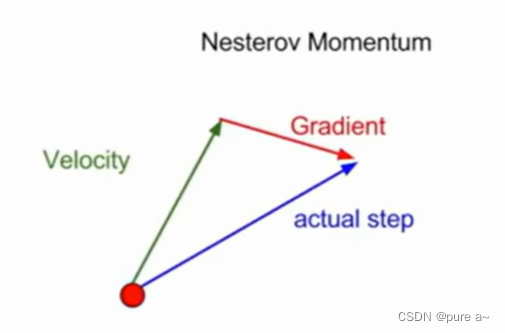
实现方式描述:在取得速度的方向上,进行步进,评估这个位置的梯度 回到原始位置 将二者叠加
表达式如下

在计算梯度时,不是在当前位置,而是未来的位置上。使用之前的速度前进一步当做未来的位置,然后在这个位置计算梯度(即上面的红色向量) 在加上当前的速度(即上面的绿色向量)
在更新梯度时可以顺应 loss function 的梯度来调整速度,并且对 SGD 进行加速。
缺点:不能根据参数的重要性而对不同的参数进行不同程度的更新。
3、Adagrad (Adaptive gradient algorithm)
理解
主要思想:主要累积梯度平方 在计算的时候除以累积的梯度平方
平衡不同参数的梯度不同时 对较小的梯度有较小的衰减 对较大的梯度有较大的衰减
缺点:因为每次都衰减 会造成步长越来越小

设置全局学习率之后 每次通过 全局学习率逐参数的除以历史梯度平方和的平方根 使得每个参数的学习率不同 可以实现在参数空间更为平缓的方向 取得更大的进步 能够使陡峭的方向变得平缓 从而加快训练速度 实际效果如下图所示
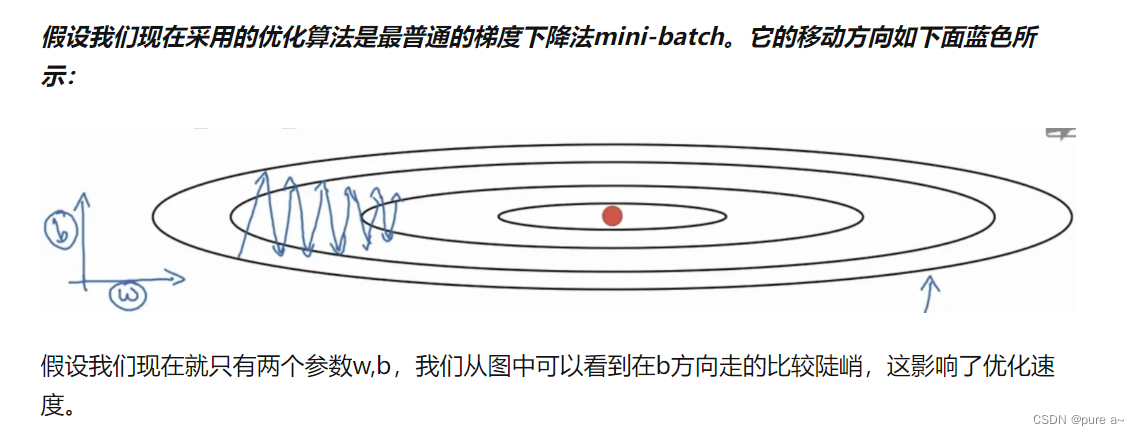
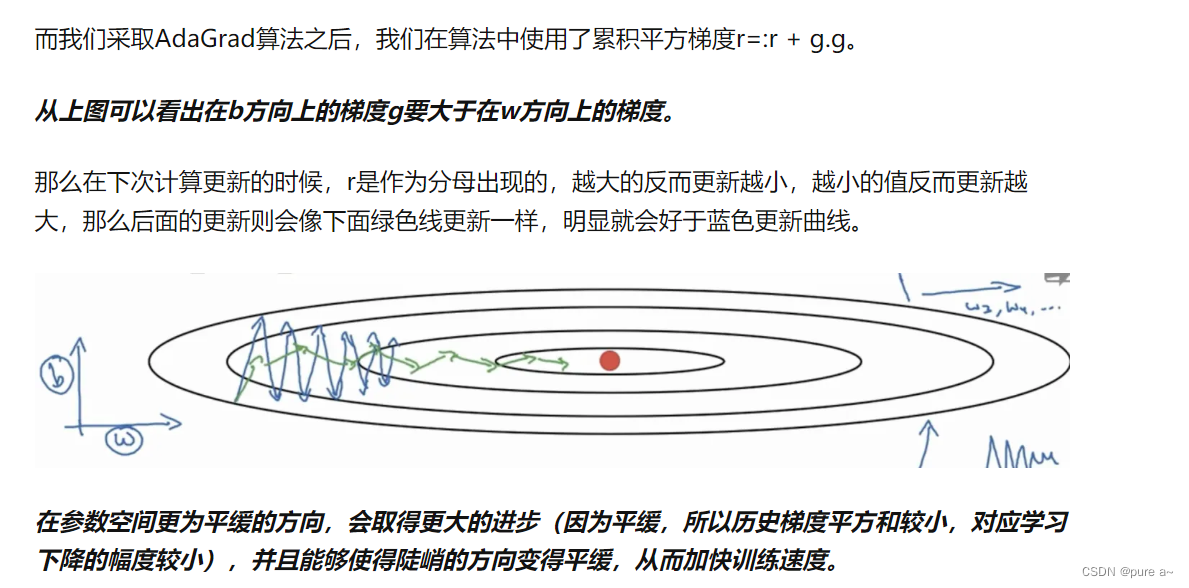
待理解 不一定对:
这个算法就可以对低频的参数做较大的更新,对高频的做较小的更新,也因此,对于稀疏的数据它的表现很好,很好地提高了 SGD 的鲁棒性
Adagrad 的优点是减少了学习率的手动调节
缺点:
它的缺点是分母会不断积累,这样学习率就会收缩并最终会变得非常小。
4、Adadelta
这个算法是对 Adagrad 的改进,解决 Adagrad 学习率急剧下降问题的
5、RMSprop
在Adagrad 的基础上 使得梯度按一定比例衰减
RMSprop 与 Adadelta 的第一种形式相同:(使用的是指数加权平均,旨在消除梯度下降中的摆动,与Momentum的效果一样,某一维度的导数比较大,则指数加权平均就大,某一维度的导数比较小,则其指数加权平均就小,这样就保证了各维度导数都在一个量级,进而减少了摆动。允许使用一个更大的学习率η)
RMSProp优化算法和AdaGrad算法唯一的不同,就在于累积平方梯度的求法不同。RMSProp算法不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。见下:
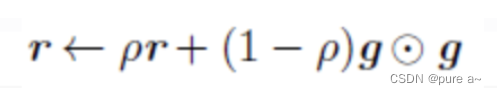
设置全局学习率之后 每次通过 全局学习率逐参数除以经过衰减系数控制的历史梯度平方和的平方根 使得每个参数的学习率不同
6、Adam:Adaptive Moment Estimation
这个算法是另一种计算每个参数的自适应学习率的方法。相当于 RMSprop + Momentum
除了像 Adadelta 和 RMSprop 一样存储了过去梯度的平方 vt 的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 mt 的指数衰减平均值:
实践表明,Adam 比其他适应性学习方法效果要好。
初始的步长非常大 因为rmsprop初始接近于0 被除之后 将会有很大步长