前言:大家好,这里是YY;此篇博客主要是结构体和自定义类型的知识点;包含
- 基础部分:【结构体基本知识】
- 进阶部分:【自定义类型种类】【计算结构体内存大小】【位段】【枚举】【联合体】
PS:创作不易,每个知识点都有例题或者图帮助理解;如果对你有帮助,希望能够得到您的关注,赞,收藏,谢谢!
目录
结构体部分:(基础章部分)
一.结构体的基础知识
结构体是一些值的集合,这些值成为成员变量。结构的每个成员可以是不同类型的变量。
类型分类:
- 内置类型:char,short,int,long,long long(c99),float,double,bool(布尔)
- 自定义类型:结构体(struct),枚举(enum),联合体(union)
1.结构体的声明
结构体:
- Struct:关键字
- Tag:结构体标签
- Member-list:成员列表
- Variable-list:结构体变量

例:

*匿名结构体类型的声明
特点:
- 可以把结构体的名字去掉
- 看似相同,编译器会把其当作不同的结构体类型
例:
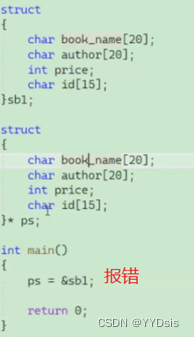
2.访问结构体成员
有两种访问方式:
- 结构体变量 . 结构体成员名(传值)
- 结构体指针 ->结构体成员名(传址)
一:普通场景
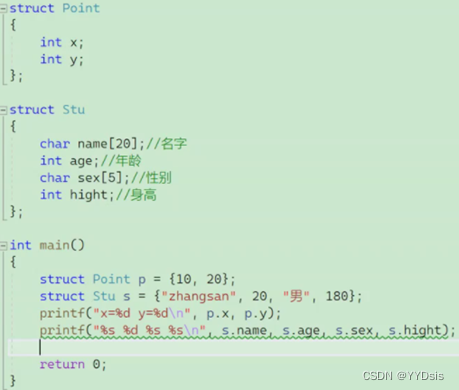
二:结构体内嵌套结构体时

三:要修改的成员变量是字符数组时 (strcpy)
应使用strcpy;原因:数组名是首元素地址不可以覆盖

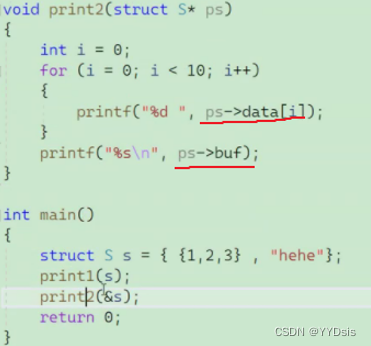
3.结构体传参
传参有两种类型:
- 传值(传结构体变量)
- 传址(传结构体指针)
PS:传值调用,形参是实参的临时拷贝,开辟还要占据空间。而传址调用仅仅传递地址,节省空间
有两种访问方式:
- 结构体变量 . 结构体成员名(传值)
- 结构体指针 ->结构体成员名(传址)
传值场景:
传址场景:

4.结构体的定义与初始化
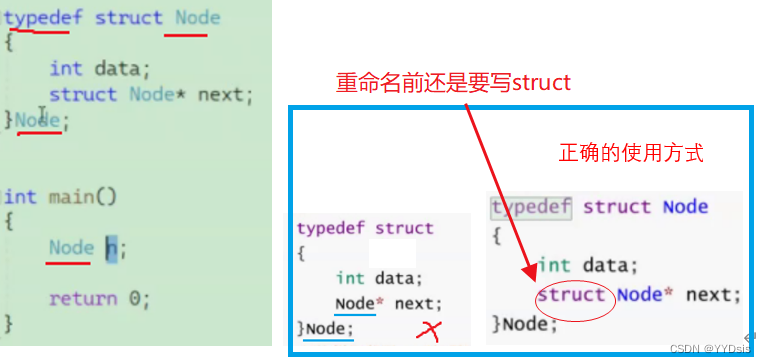
一:结构体重命名(typedef)
注意点:
实例化时,不用再次写struct Node c(例:直接Node c)
在重命名之前不可以使用Node
例:
二:结构体的创建(实例化)
结构体声明时可以同时创建多个变量/多个指针
例:
struct Book { char book_name[20]; char author[20]; int price; char id[15]; }sb3,sb4,*sb5; 等价于struct Book sb3,sb4;
三:结构体的初始化
结构体的初始化分为两种方式
- 声明时直接创建
- 单独创建(按顺序创建/不按顺序创建)
例:
struct Book { char book_name[20]; char author[20]; int price; char id[15]; }sb3={"C++","超人",20,"MB666"};//声明时直接创建 strcut Book SB3={"C++","超人",20,"MB666"};//单独创建(按顺序创建) strcut Book SB3={.price=20};//单独创建(不按顺序创建,直接索引) 不能直接修改成员列表中的数组,要用strcpy!!//详情见同一博客,“访问结构体成员”
自定义类型部分:(进阶部分)
一.自定义类型分类
自定义类型:
- 结构体(struct)
- 枚举(enum)
- 联合体(union)
二.结构体的内存类型
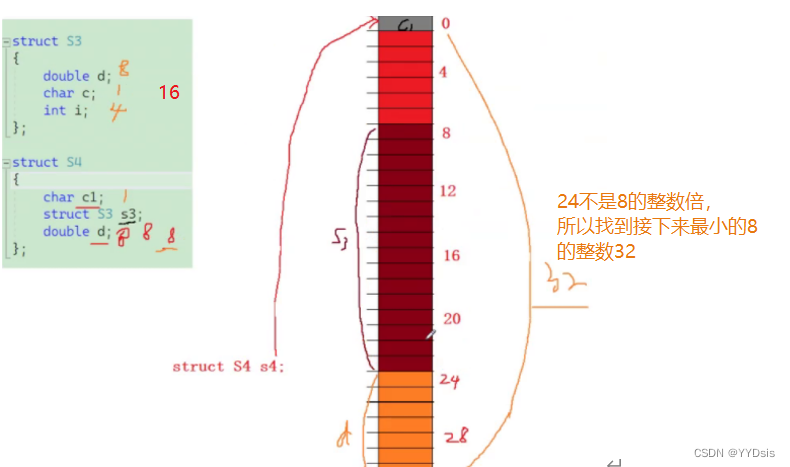
计算结构体的内存大小:考虑结构体内存对齐问题
1.计算结构体内存大小——内存对齐
一.:结构体内存对齐规则
对齐数:结构体成员自身大小和默认对齐数的较小值
PS:Linux环境默认不设对齐数(对齐数是结构体成员自身大小)
规则:
- 每个结构体成员都有一个对齐数,成员的对齐数中最大的即为结构体的最大对齐数
- 结构体的第一个成员直接对齐到相对于结构体变量起始位置为0的偏移处
- 从第二个成员开始,要对齐到某个【对齐数】的整数倍的偏移处
- 结构体的总大小,必须是最大对齐数的整数倍
例:
二:为什么存在结构体内存对齐?
- 平台原因(移植原因)
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
原因在于,为了访问未对齐的内存,处理器需要做两次内存访问;而面对已经对齐的内存访问,仅仅需要一次访问。即牺牲空间来换取时间。

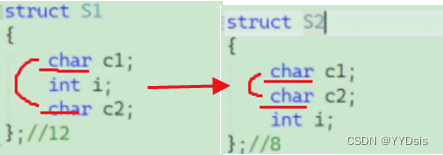
三:考虑结构体内存对齐,应当如何设置结构体成员?
尽量把小的结构体成员放在一起
例:
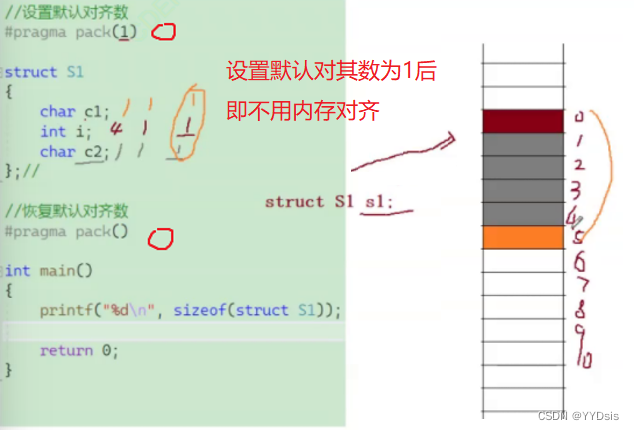
*情景:修改和恢复默认对齐数
- 设置默认对齐数:pragma pack(1)
- 恢复默认对其书:pragma pack( )
例:
2.结构体实现位段 (位段的填充&可移植性)
一:位段的定义
定义:
- 位段的位指的是二进制位
- 数字部分指的是,所需的二进制位个数
要点:位段的声明和结构是类似的,有两个不同
- 位段的成员必须是int ,unsigned int 或 signed int或者char等整型
- 位段的成员名后面必须有一个冒号,和一个数字
struct A { int _a:2; int _b:5; }
二:位段的内存分配
- 位段的成员可以是 int,unsigned int ,signed int或者是char(整型家族);
- 位段上的空间是按照需要以4个字节(int),或者1个字节(char)的方式来开辟
(char与int一般不混用,不确定储存方向,有可能截断/整型提升);
- 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段;
场景引入:为什么使用位段后,A的大小从16变为8?
分析:struct A,以4个字节(int)开辟空间;
struct S { int a; int b; int c; int d; }; printf("%d\n",sizeof(strcut S)); S的大小16 struct A { 先开4byte-32bit空间 int _a:2; 占掉2个剩下30 int _b:5; 占掉5个剩下25 int _c:10; 占掉10个剩下15 int _d:30; 剩下15个不够占,再开4byte空间 总共开了8byte空间 } printf("%d\n",sizeof(strcut A)); S的大小8
三:位段的不确定性/跨平台问题
- int位段是signed int 还是 unsigned int ,不确定
- 位段中最大位的数目不确定(16位机器最大16,32位机器最大32;如写成27,在16位机器中会出问题)
- 位段中成员在内存中从左向右分配,还是从右向左分配标准尚不确定
- 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时。是选择舍弃剩余的位还是再利用,不确定
四:小总结
与结构相比,位段可以达到同样的效果,但是可以很好地节省空间,但是要注意跨平台问题
三.枚举(enum)
枚举顾名思义就是:一一列举
1.枚举类型的定义与用法实例
使用要点:
- 枚举的每一个可能的取值是常量
- 枚举的常量都有默认值(依次0,1,2...),默认依次向下减1
- 这些常量可以赋值
- 可以出现部分不赋值,部分赋值,赋值过后的剩余变量遵循默认依次向下减1
例子:一周的星期一到星期日是有限的7天,可以一一列举
enum Day 星期 { Mon,//默认0 Tues,//默认1 Wed,//默认2 Thur=10,//默认3,赋值成10 Fri,//按照默认原则,10+1,11 Sat,//默认12 Sun//默认13 }; 枚举所有可能的取值
2.枚举相较于#define的优点
我们可以用#define定义常量,为什么非要使用枚举?
区别:后者没有类型,只是单纯的替换(不能调试);前者是枚举类型;

枚举的优点:
- 增加代码的可读性和可维护性
- 和#define定义的标识符比较,枚举有类型检查,更加严谨
- 防止命名污染(封装)
- 便于调试
- 使用方便,一次可以定义多个常量

四.联合体(union)
1.联合体的特点
- 联合体的成员是共用同一块内存空间的,这样一个联合变量的大小,至少是最大成员的大小(因为联合体至少得有足够的能力保存最大的那个成员)
PS:涉及联合体大小的计算
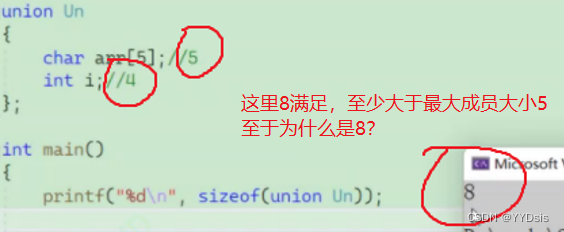
2.联合体大小的计算
对齐数:结构体成员自身大小和默认对齐数的较小值
要点:
- 默认对齐数是8,取两者较小的数为对齐数
- 当最大成员大小不是最大对齐数的整数倍时,就要对齐到最大对齐数的整数倍
例1:
分析:
- char arr[5]的大小是1,默认对齐数是8,取1为对齐数
- int i的大小是4,默认对齐数是8,取4为对齐数
- 两者最大对齐数为4
- 最大成员大小是5,不是最大对齐数4的整数倍,因此对齐到4的整数倍8
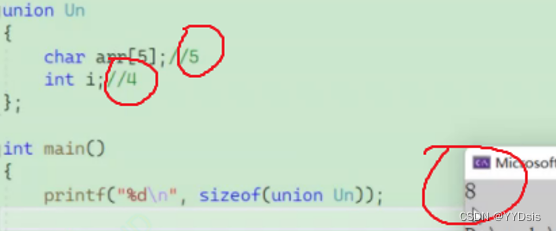
例2:
PS:short的默认对其数为2
分析:
- 最大成员大小是12是最大对齐数4的整数倍,故联合体的大小为12
